Pytorch实现FastText模型对AG_news数据集进行四分类预测(torchtext实现数据预处理)
文章目录
- 1 FastText模型简介
- 1.1 模型简介
- 1.2 Hierarchical Softmax简介
- 2 AG_news数据集
- 3 TorchText简介
- 3.1 自己实现数据预处理的步骤
- 3.2 使用TorchText对数据预处理
- 4 FastText模型实现
- 4.1定义FastText模型
- 4.2 训练模型
- 4.3 测试模型
- 5 复现模型时踩的坑
- 5.1 pytorch输出的label
- 5.2 参数设置
- 6 代码附录
1 FastText模型简介
1.1 模型简介
本模型来自论文《Bag of Tricks for Efficient Text Classification》
网络模型结构如下图,FastText模型只有三层:输入层、隐含层、输出层(Hierarchical Softmax)。输入是多个单词的词向量,隐含层是对多个输入的词向量的叠加的平均,输出是一个特定的label。

1.2 Hierarchical Softmax简介
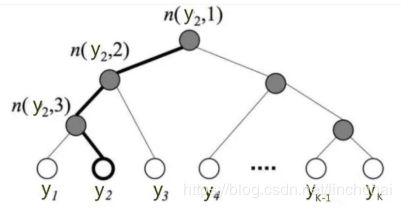
假设隐藏层的神经元数量为h,当前分类任务的类别数量为n,隐藏层与输出层之间是全连接的,则参数矩阵W中元素的个数为h*n,当n较大的时候,计算和更新W的时间复杂度较大。论文中提出了使用Hierarchical Softmax来降低训练时间,首先根据每个label出现的概率,对所有的label,构造一棵赫夫曼树。如下图,若有n个label,则该赫夫曼树有n个叶结点,n-1个非叶结点, 每个非叶结点都对应一个参数Θ,其中每个叶节点都有一个唯一对应的赫夫曼编码(假设左子树为0,右子树为1),则图中叶节点y2的赫夫曼编码为001。
假设当前训练样本的标签为y2,y2的赫夫曼编码为001,则训练步骤如下:
- 从根结点n(y2,1)开始,赫夫曼编码当前为0,使用二分类,计算向左走的概率
- 走到n(y2,2)结点,赫夫曼编码当前为0,使用二分类,计算向左走的概率
- 走到n(y2,3)结点,赫夫曼编码当前为1,使用二分类,计算向右走的概率
- 最后走到了叶节点y2,则损失函数就是各个叶节点进行二分类的概率的乘积
- 根据损失函数,更新所走过的路径上的非叶结点的参数Θ
实质上就是从根节点开始,沿着Huffman树不断的进行二分类,并且不断的修正各中间向量Θ
Hierarchical Softmax的核心思想就是将一次多分类,分解为多次二分类, 举个例子,有[1,2,3,4,5,6,7,8]这8个分类,想要判断词A属于哪个分类,我们可以一步步来,首先判断A是属于[1,2,3,4]还是属于[5,6,7,8]。如果判断出属于[1,2,3,4],那么就进一步分析是属于[1,2]还是[3,4],以此类推。这样一来,就把时间复杂度从o(hN)降为o(hlogN)
结合Hierarchical Softmax的思想后,FastText模型如下图所示,其中hidden layer的节点与哈夫曼树的每个非叶节点进行连接
.

2 AG_news数据集
数据集可以在百度云下载,链接:https://pan.baidu.com/s/1FBkweGDEAFgnakZnPpOfLQ 提取码:5oxn
数据格式如下,每一条数据有三列,第一列为标签,第二列为title,第三列为content:
"3","Wall St. Bears Claw Back Into the Black (Reuters)","Reuters - Short-sellers, Wall Street's dwindling\band of ultra-cynics, are seeing green again."
"3","Carlyle Looks Toward Commercial Aerospace (Reuters)","Reuters - Private investment firm Carlyle Group,\which has a reputation for making well-timed and occasionally\controversial plays in the defense industry, has quietly placed\its bets on another part of the market."
"3","Oil and Economy Cloud Stocks' Outlook (Reuters)","Reuters - Soaring crude prices plus worries\about the economy and the outlook for earnings are expected to\hang over the stock market next week during the depth of the\summer doldrums."
"3","Iraq Halts Oil Exports from Main Southern Pipeline (Reuters)","Reuters - Authorities have halted oil export\flows from the main pipeline in southern Iraq after\intelligence showed a rebel militia could strike\infrastructure, an oil official said on Saturday."
3 TorchText简介
3.1 自己实现数据预处理的步骤
若自己手动对数据进行预处理,需要实现的功能如下:
- 分词
- 去除停用词
- 对训练集建立词汇表(训练集的每个词对应一个唯一的index,其中还包括unk与pad,分别表示未登录词与补齐的词)
- 将训练集划分成mini-batch
- 将每一批的数据表示为词向量
我自己尝试手动实现过这些步骤,过程过于繁琐,确实需要花费一番时间与精力
3.2 使用TorchText对数据预处理
每一条数据有三列,在该例子中只是用第三列的content,没有用上第二列的title(因为对torchtext的API还不是很熟悉,没找到将两列合并,然后分批产生词向量的API,略惭愧,这里就只使用第三列的content跑一跑模型)。关于torchtext的使用,可以参考torchtext入门教程,轻松玩转文本数据处理
def get_data_iter(train_csv, test_csv, fix_length):
TEXT = data.Field(sequential=True, lower=True, fix_length=fix_length, batch_first=True)
LABEL = data.Field(sequential=False, use_vocab=False)
train_fields = [("label", LABEL), ("title", None), ("text", TEXT)]
train = TabularDataset(path=train_csv, format="csv", fields=train_fields, skip_header=True)
train_iter = BucketIterator(train, batch_size=batch_size, device=-1, sort_key=lambda x: len(x.text),
sort_within_batch=False, repeat=False)
test_fields = [("label", LABEL), ("title", None), ("text", TEXT)]
test = TabularDataset(path=test_csv, format="csv", fields=test_fields, skip_header=True)
test_iter = Iterator(test, batch_size=batch_size, device=-1, sort=False, sort_within_batch=False, repeat=False)
vectors = Vectors(name=word2vec_dir)
TEXT.build_vocab(train, vectors=vectors)
vocab = TEXT.vocab
return train_iter, test_iter, vocab
其中train_iter与test_iter是训练集与测试集的迭代器,vocab是训练集的字典
4 FastText模型实现
4.1定义FastText模型
参数说明:
- vocab:训练集的字典
- vec_dim:词向量的维度
- label_size:类别数量
- hidden_size:隐藏层神经元数量
class FastText(nn.Module):
def __init__(self, vocab, vec_dim, label_size, hidden_size):
super(FastText, self).__init__()
#创建embedding
self.embed = nn.Embedding(len(vocab), vec_dim)
# 若使用预训练的词向量,需在此处指定预训练的权重
self.embed.weight.data.copy_(vocab.vectors)
self.embed.weight.requires_grad = True
self.fc = nn.Sequential(
nn.Linear(vec_dim, hidden_size),
nn.BatchNorm1d(hidden_size),
nn.ReLU(inplace=True),
nn.Linear(hidden_size, label_size)
)
def forward(self, x):
x = self.embed(x)
out = self.fc(torch.mean(x, dim=1))
return out
4.2 训练模型
参数说明:
- train_iter:是个可迭代对象,可以从batch中获取data与text
def train_model(net, train_iter, epoch, lr, batch_size):
print("begin training")
net.train() # 必备,将模型设置为训练模式
optimizer = optim.Adam(net.parameters(), lr=lr)
criterion = nn.CrossEntropyLoss()
for i in range(epoch): # 多批次循环
for batch_idx, batch in enumerate(train_iter):
#注意target=batch.label - 1,因为数据集中的label是1,2,3,4,但是pytorch的label默认是从0开始,所以这里需要减1
data, target = batch.text, batch.label - 1
optimizer.zero_grad() # 清除所有优化的梯度
output = net(data) # 传入数据并前向传播获取输出
loss = criterion(output, target)
loss.backward()
optimizer.step()
# 打印状态信息
logging.info(
"train epoch=" + str(i) + ",batch_id=" + str(batch_idx) + ",loss=" + str(loss.item() / batch_size))
print('Finished Training')
4.3 测试模型
def model_test(net, test_iter):
net.eval() # 必备,将模型设置为训练模式
correct = 0
total = 0
with torch.no_grad():
for i, batch in enumerate(test_iter):
# 注意target=batch.label - 1,因为数据集中的label是1,2,3,4,但是pytorch的label默认是从0开始,所以这里需要减1
data, label = batch.text, batch.label - 1
logging.info("test batch_id=" + str(i))
outputs = net(data)
# torch.max()[0]表示最大值的值,troch.max()[1]表示回最大值的每个索引
_, predicted = torch.max(outputs.data, 1) # 每个output是一行n列的数据,取一行中最大的值
total += label.size(0)
correct += (predicted == label).sum().item()
print('Accuracy of the network on test set: %d %%' % (100 * correct / total))
在测试集上准确率为89%,和论文中的92.5%有点差距,但是该模型没有使用bigram和层次softmax,实现得比较粗糙,这个准确率还是可以接受的
5 复现模型时踩的坑
5.1 pytorch输出的label
AG_news数据集有四个类别,分别为1,2,3,4,一开始直接使用该1-4的标签进行预测,但程序报错了。后来发现,pytorch在分类时,label默认是从0开始的,所以需要对数据集的label进行减1操作,是label的取值范围变成0,1,2,3
5.2 参数设置
- learning rate也不要设置太大,设为0.001训练效果还不错
- 一开始按照论文令hidden_size=10,预测准确率=88%。后来令hidden_size=200,准确率变成了89%。可以看出,hidden_size对于模型还是有一定的影响
6 代码附录
import torch
import torch.nn as nn
import torch.optim as optim
import os
import logging
import pandas as pd
from torchtext.data import Iterator, BucketIterator, TabularDataset
from torchtext import data
from torchtext.vocab import Vectors
class FastText(nn.Module):
def __init__(self, vocab, vec_dim, label_size, hidden_size):
super(FastText, self).__init__()
#创建embedding
self.embed = nn.Embedding(len(vocab), vec_dim)
# 若使用预训练的词向量,需在此处指定预训练的权重
self.embed.weight.data.copy_(vocab.vectors)
self.embed.weight.requires_grad = True
self.fc = nn.Sequential(
nn.Linear(vec_dim, hidden_size),
nn.BatchNorm1d(hidden_size),
nn.ReLU(inplace=True),
nn.Linear(hidden_size, label_size)
)
def forward(self, x):
x = self.embed(x)
out = self.fc(torch.mean(x, dim=1))
return out
def train_model(net, train_iter, epoch, lr, batch_size):
print("begin training")
net.train() # 必备,将模型设置为训练模式
optimizer = optim.Adam(net.parameters(), lr=lr)
criterion = nn.CrossEntropyLoss()
for i in range(epoch): # 多批次循环
for batch_idx, batch in enumerate(train_iter):
# 注意target=batch.label - 1,因为数据集中的label是1,2,3,4,但是pytorch的label默认是从0开始,所以这里需要减1
data, target = batch.text, batch.label - 1
optimizer.zero_grad() # 清除所有优化的梯度
output = net(data) # 传入数据并前向传播获取输出
loss = criterion(output, target)
loss.backward()
optimizer.step()
# 打印状态信息
logging.info(
"train epoch=" + str(i) + ",batch_id=" + str(batch_idx) + ",loss=" + str(loss.item() / batch_size))
print('Finished Training')
def model_test(net, test_iter):
net.eval() # 必备,将模型设置为训练模式
correct = 0
total = 0
with torch.no_grad():
for i, batch in enumerate(test_iter):
# 注意target=batch.label - 1,因为数据集中的label是1,2,3,4,但是pytorch的label默认是从0开始,所以这里需要减1
data, label = batch.text, batch.label - 1
logging.info("test batch_id=" + str(i))
outputs = net(data)
# torch.max()[0]表示最大值的值,troch.max()[1]表示回最大值的每个索引
_, predicted = torch.max(outputs.data, 1) # 每个output是一行n列的数据,取一行中最大的值
total += label.size(0)
correct += (predicted == label).sum().item()
print('Accuracy of the network on test set: %d %%' % (100 * correct / total))
# test_acc += accuracy_score(torch.argmax(outputs.data, dim=1), label)
# logging.info("test_acc=" + str(test_acc))
def get_data_iter(train_csv, test_csv, fix_length):
TEXT = data.Field(sequential=True, lower=True, fix_length=fix_length, batch_first=True)
LABEL = data.Field(sequential=False, use_vocab=False)
train_fields = [("label", LABEL), ("title", None), ("text", TEXT)]
train = TabularDataset(path=train_csv, format="csv", fields=train_fields, skip_header=True)
train_iter = BucketIterator(train, batch_size=batch_size, device=-1, sort_key=lambda x: len(x.text),
sort_within_batch=False, repeat=False)
test_fields = [("label", LABEL), ("title", None), ("text", TEXT)]
test = TabularDataset(path=test_csv, format="csv", fields=test_fields, skip_header=True)
test_iter = Iterator(test, batch_size=batch_size, device=-1, sort=False, sort_within_batch=False, repeat=False)
vectors = Vectors(name=word2vec_dir)
TEXT.build_vocab(train, vectors=vectors)
vocab = TEXT.vocab
return train_iter, test_iter, vocab
if __name__ == "__main__":
logging.basicConfig(format='%(asctime)s:%(levelname)s: %(message)s', level=logging.INFO)
train_csv = "data/train.csv"
test_csv = "data/test.csv"
word2vec_dir = "data/glove.model.6B.300d.txt" # 训练好的词向量文件,写成相对路径好像会报错
net_dir = "model/ag_fasttext_model.pkl"
sentence_max_size = 50 # 每篇文章的最大词数量
batch_size = 64
epoch = 10 # 迭代次数
emb_dim = 300 # 词向量维度
lr = 0.001
hidden_size = 200
label_size = 4
train_iter, test_iter, vocab = get_data_iter(train_csv, test_csv, sentence_max_size)
# 定义模型
net = FastText(vocab=vocab, vec_dim=emb_dim, label_size=label_size, hidden_size=hidden_size)
# 训练
logging.info("开始训练模型")
train_model(net, train_iter, epoch, lr, batch_size)
# 保存模型
torch.save(net, net_dir)
logging.info("开始测试模型")
model_test(net, test_iter)