python学习笔记
解释型语言,编译型语言
编译型语言:把源代码转化成目标机器的CPU指令,c,c++。编译型语言在运行程序之前,需要编译过程,把程序语言编译成机器语言的文件(.exe)。以后要运行时,不需要重新编译,直接使用编译的结果(.exe)。
解释语言:解释后转换成字节码(中间代码),运行在虚拟机上,解释器执行中间代码。Java,Python,c#。虚拟机屏蔽了不同CPU指令的差异性。解释型语言不需要编译,只有在执行程序的时候才把高级语言翻译成机器码。因此,每次执行时,解释器都要重新翻译一次,效率较低。部分解释器能够在运行时动态优化代码,可以大幅提升程序性能。
杨辉三角代码(迭代器生成前10行)
def triangles():
a = [0];
b = [1];
n = 0;
while n<10:
yield b;
a.extend(b);
b.append(0);
for i in range(len(a)):
b[i] = a[i]+b[i]
n = n+1;
a = [0];
return None;
for t in triangles():
print(t)
Python 的map函数和reduce函数
map函数接受两个参数,第一个是函数f,第二个是能够iterable的对象。map函数的作用就是将函数f作用在对象序列的每个元素上,然后把结果做为一个iterator返回。
reduce函数也接受两个参数,第一个是f,第二个是iteratble的对象。与map函数不同,reduce对于第一个参数,函数f,有更严格的要求。它要求这个f也必须接受两个参数,形如f(x,y)。有了这个要求,我们不难看出,reduce函数作用的iterable对象必须有两个及以上的元素,否则f接收不到足够的参数。从另一个方面也可以理解,若iterable对象只有一个元素,那还用得着reduce吗?reduce函数的作用相对来说复杂一些。通俗的说,它就是按照f方法把一个可以iterable的对象reduce成一个对象,这个对象的类型取决于函数f的返回类型。举个例子:我们要对序列[a,b,c,d,e]进行reduce,采用f方法。那么返回的结果就等价于:f(f(f(f(a,b),c),d),e);下面,我尝试用一段代码解释reduce函数
reduce(fn,array)
#等效于下面这种循环
result = fn(array[0],array[1])
for i in range(2, len(array)):
result=fn(result,array[i]);
return result;
关于几种编码方式的疑问总结
在计算机中,数字和字符都以二进制的形式存储。怎么把具体的字符转换成存储的二进制数字,这套规则对应的就是编码。计算机中存储的最小单位是字节byte,即8个二进制位,比如0000 0000。
utf-8,ascii 都是对应着不同字符集的编码方式。asc ii收录的字符集只有128个,utf-8收录的字符集远远超过asc ii,光是中文字符就有两万多个。
这里再简单介绍下utf-8是什么。utf-8是实现unicode的字符集的编码方式。unicode字符集是一个很大的字符集,里面包括了100多万个符号,每个符号的编码都不一样。由于符号太多,存储每个符号需要的字节就不好确定。比如,汉字存储至少需要两个字节,英文字母只需要1个字节,怎么去规定这些符号的存储方式就成了一个难题。为了解决这些难题,就诞生了utf-8,utf-16等一系列实现unicode字符集的编码方式。
因此,utf-8就是实现unicode字符的编码方式之一。ascii编码就是实现ascii字符的编码方式。
进程和线程
正则表达式
\s 表示空白符
\d 表示数字
\w 表示数字或字母
^表示字符串开头,$表示字符串结尾
[a-z]表示匹配括号内的任意一个字符
a|b 表示匹配a或b
+表示一个或者多个字符,*表示任意数量的字符,包括0个。{m}表示m个字符,{m,n}表示m~n个字符。. 表示任意字符。
爬虫基础架构
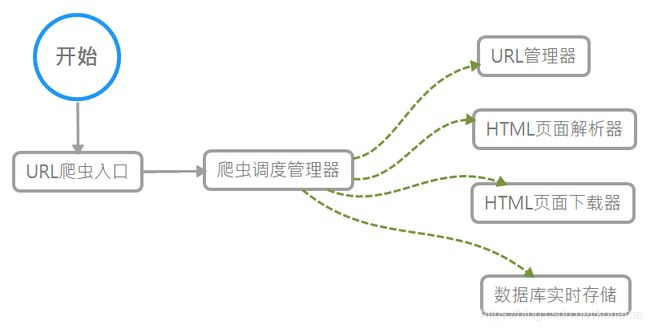
完成一个的爬虫抓取数据的过程需要如下几个步骤:
- 给定爬虫的URL入口,将该URL添加入URL管理器。
- 爬虫调度管理器询问URL管理器,是否有需要爬取的URL?若有,则返回一个需要爬取的URL。
- 爬虫调度管理器根据取得的URL,向HTML页面下载器发送下载请求。
- HTML页面下载器收到URL,开始向服务器发送http请求,这个请求可以自定义它的http头部信息。
- HTML页面下载器收到服务器返回的状态码和响应内容,读取响应内容,并返回给调度管理器。
- 爬虫调度管理器收到服务器的响应内容,传送给HTML页面解析器。
- HTML页面解析器开始解析文档,提取该页面中需要爬取的信息,把爬取的信息返回给爬虫调度管理器。同时,HTML解析器还会提取页面中的URL链接,返回给URL管理器。
- 爬虫调度管理器收到了爬取的信息,将它传送给数据库,存储起来。
- URL管理器收到了页面解析器返回的新URL,根据自定义的规则判断是否将该URL需要添加进待爬取的URL列表中。
- 重复步骤2,直到没有新的URL需要爬取为止。
PEP8 代码规范
缩进:使用4个空格代表每层的缩进,函数输入参数的缩进应该与函数内部区分开来
def long_name_function(
var1,var2,
var3,var4):
print(var1)
return
或
foo = long_name_function(
var1,var2,
var3,var4)
对于条件判断语句,根据and的位置确定缩进层次
if (one_thing and
another_thing):
do_something()
if (one_thing
and another_thing):
do_something()
对于带括号的多行参数,如下处理:
mylist = [
1,2,3,
4,5,6,
]
Python 特殊方法
在python中,特殊方法以双下划线开始,双下划线结束。类似于__init__()。特殊方法可以给你的类加上一些特性,比如迭代、切片、连乘等。
class Vector(x, y):
__init__(self):
self.x = x
self.y = y
#实现向量加法
__add__(self,other):
x = self.x + other.x
y = self.y + other.y
return Vector(x, y)
#实现向量乘法
__mul__(self, scalar):
return Vector(self.x*scalar, self.y*scalar)
除了上面说到的几个特殊方法外,python还有差不多80多个特殊方法,比如__len__方法可以用来求长度
装饰器
可变对象,不可变对象
当我们讨论可变对象和不可变对象时,都是针对python内置对象。对于自己定义的对象,需要自己添加它的属性和方法。python内置的不可变对象有(immutable)tuple,str,int。可变对象(mutable)有dict,list等。
在参数传递时,传递可变对象就是传引用,传递不可变对象就是传值。
hashable
对于一个对象,它如果是hashable,那么它在生存周期内是不可变的(需要hash函数),而且它可以和其他对象比较(需要比较方法,比较值相同的对象一定有相同的hash值)。
举个例子,字典,列表,在它的生存周期内是可变的,但它的hash值不变,所以它是不可hash的。