Hadoop之——基于3台服务器搭建Hadoop3.x集群(实测完整版)
转载请注明出处:https://blog.csdn.net/l1028386804/article/details/93892479
一、 服务器规划

二、Hadoop集群环境的准备
搭建Hadoop集群环境之前,需要为搭建Hadoop集群环境做一些相关的准备工作,以达到正确安装Hadoop集群的目的。
1.添加hadoop用户身份
以root身份登录每台虚拟机服务器,在每台服务器上执行如下操作。
groupadd hadoop
useradd -r -g hadoop hadoop
passwd hadoop
Changing password for user hadoop.
New password: 新密码
Retype new password: 确认新密码
passwd: all authentication tokens updated successfully.
chown -R hadoop.hadoop /usr/local/
chown -R hadoop.hadoop /tmp/
chown -R hadoop.hadoop /home/
vim /etc/sudoers
找到
root ALL=(ALL) ALL
下面添加
hadoop ALL=(ALL) ALL2.关闭防火墙
以root身份登录虚拟机服务器,在每台服务器上执行如下命令:
#查看防火墙状态
service iptables status
#关闭防火墙
service iptables stop
#关闭防火墙开机启动
chkconfig iptables off
#查看防火墙状态
service iptables status3.设置静态IP
为每台服务器设置静态IP,这里以服务器binghe201(192.168.175.201)为例,修改配置文件“/etc/sysconfig/network-scripts/ifcfg-eth0”文件,如下:
DEVICE=eth0
TYPE=Ethernet
UUID=11e3b288-72da-4cc6-898d-ee2bf0b44d77
ONBOOT=yes
NM_CONTROLLED=yes
BOOTPROTO=static
IPADDR=192.168.175.201
NETMASK=255.255.255.0
BROADCAST=192.168.175.255
GATEWAY=192.168.175.2
DNS1=114.114.114.114
DNS2=8.8.8.8
DEFROUTE=yes
IPV4_FAILURE_FATAL=yes
IPV6INIT=no
NAME="System eth0"
HWADDR=00:0C:29:7F:45:21
PEERDNS=yes
PEERROUTES=yes
LAST_CONNECT=1561336045下面,分别列出每台服务器上“/etc/sysconfig/network-scripts/ifcfg-eth0”文件修改过的部分。
- binghe202(192.168.175.202)
BOOTPROTO=static
IPADDR=192.168.175.202
NETMASK=255.255.255.0
BROADCAST=192.168.175.255
GATEWAY=192.168.175.2
DNS1=114.114.114.114
DNS2=8.8.8.8- binghe203(192.168.175.203)
BOOTPROTO=static
IPADDR=192.168.175.203
NETMASK=255.255.255.0
BROADCAST=192.168.175.255
GATEWAY=192.168.175.2
DNS1=114.114.114.114
DNS2=8.8.8.8设置完静态IP之后,在每台服务器上执行如下命令重启网络。
service network restart4.设置主机名
设置主机名需要在文件“/etc/sysconfig/network”中进行配置。如果需要修改当前会话的主机名需要使用命令“hostname 主机名”的方式进行设置。
下面,分别列出每台服务器上“/etc/sysconfig/network”文件的配置和执行的命令。
- binghe201(192.168.175.201)
hostname binghe201
vim /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=binghe201- binghe202(192.168.175.202)
hostname binghe202
vim /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=binghe202- binghe203(192.168.175.203)
hostname binghe203
vim /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=binghe2035.设置主机名与IP地址的映射关系
在每台服务器上修改“/etc/hosts”文件,添加如下配置:
192.168.175.201 binghe201
192.168.175.202 binghe202
192.168.175.203 binghe2036.集群环境下配置SSH免密码登录
注意:配置SSH免密码登录,使用hadoop身份登录虚拟机服务器,进行相关的操作。
(1)生成SSH免密码登录公钥和私钥
在每台虚拟机服务器上执行如下命令,在每台服务器上分别生成SSH免密码登录的公钥和私钥。
ssh-keygen -t rsa
cat /home/hadoop/.ssh/id_rsa.pub >> /home/hadoop/.ssh/authorized_keys(2)设置目录和文件权限
在每台虚拟机服务器上执行如下命令,设置相应目录和文件的权限。
chmod 700 /home/hadoop/
chmod 700 /home/hadoop/.ssh
chmod 644 /home/hadoop/.ssh/authorized_keys
chmod 600 /home/hadoop/.ssh/id_rsa(3)将公钥拷贝到每台服务器
在每台虚拟机服务器上执行如下命令,将生成的公钥拷贝到每台虚拟机服务器上。
ssh-copy-id -i /home/hadoop/.ssh/id_rsa.pub binghe201
ssh-copy-id -i /home/hadoop/.ssh/id_rsa.pub binghe202
ssh-copy-id -i /home/hadoop/.ssh/id_rsa.pub binghe203执行完上面的命令之后,每台服务器之间都可以通过“ssh 服务器主机名”进行免密码登录了。
注意:执行每条命令的时候,都会提示类似如下信息。
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'binghe101,192.168.175.101' (RSA) to the list of known hosts.
hadoop@binghe101's password:在“是否确认继续连接”的地方输入“yes”,提示输入密码的地方输入相应服务器的登录密码即可,后续使用“ssh 主机名”登录相应服务器就不用再输入密码了。
三、集群环境下的JDK安装
(1)安装JDK并配置系统环境便令
在每台服务器上执行安装JDK的操作,同样是将JDK安装在CentOS虚拟机的“/usr/local”目录下,即JAVA_HOME安装目录为“/usr/local/jdk1.8.0_212”。在文件“/etc/profile”中配置的系统环境变量如下:
JAVA_HOME=/usr/local/jdk1.8.0_212
CLASS_PATH=.:$JAVA_HOME/lib
PATH=$JAVA_HOME/bin:$PATH
export JAVA_HOME CLASS_PATH PATH(2)使系统环境变量生效
在每台服务器上执行如下命令使JDK系统环境变量生效。
source /etc/profile(3)验证JDK是否安装配置
具体验证方式如下:
-bash-4.1$ java -version
java version "1.8.0_212"
Java(TM) SE Runtime Environment (build 1.8.0_212-b10)
Java HotSpot(TM) 64-Bit Server VM (build 25.212-b10, mixed mode)可以看到输出了Java版本,说明JDK安装配置成功。
四、搭建并配置Zookeeper集群
安装配置完JDK后,就需要搭建Zookeeper集群了,根据对服务器的规划,现将Zookeeper集群搭建在“binghe201”、“binghe202”、“binghe203”三台服务器上。
注意:步骤1-4是在“binghe201”服务器上进行的操作。
1.下载Zookeeper
在“binghe201”上执行如下命令下载Zookeeper。
wget https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/zookeeper-3.5.5/apache-zookeeper-3.5.5-bin.tar.gz2.安装并配置Zookeeper系统环境变量
这里,将Zookeeper安装在虚拟机的“/usr/local”目录下,即ZOOKEEPER_HOME安装目录为“/usr/local/zookeeper-3.5.5”。
结合配置JDK后,文件“/etc/profile”文件中添加的内容如下:
JAVA_HOME=/usr/local/jdk1.8.0_212
ZOOKEEPER_HOME=/usr/local/zookeeper-3.5.5
CLASS_PATH=.:$JAVA_HOME/lib
PATH=$JAVA_HOME/bin:$ZOOKEEPER_HOME/bin:$PATH
export JAVA_HOME ZOOKEEPER_HOME CLASS_PATH PATH3.配置Zookeeper
首先,需要将“$ZOOKEEPER_HOME/conf”(“$ZOOKEEPER_HOME”为Zookeeper的安装目录)目录下的zoo_sample.cfg文件修改为zoo.cfg文件。具体命令如下:
cd /usr/local/zookeeper-3.5.5/conf/
mv zoo_sample.cfg zoo.cfg接下来修改zoo.cfg文件,修改后的具体内容如下:
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/usr/local/zookeeper-3.5.5/data
dataLogDir=/usr/local/zookeeper-3.5.5/dataLog
clientPort=2181
server.1=binghe201:2888:3888
server.2=binghe202:2888:3888
server.3=binghe203:2888:3888在Zookeeper的安装目录下创建“data”和“dataLog”两个文件夹。
mkdir -p /usr/local/zookeeper-3.5.5/data
mkdir -p /usr/local/zookeeper-3.5.5/dataLog切换到新建的data目录下,创建myid文件,具体内容为数字“1”,如下所示:
echo "1" >> /usr/local/zookeeper-3.5.5/data/myid将数字“1”写入到文件myid。
4.复制Zookeeper和系统环境变量到其他服务器
将“binghe201”上安装的Zookeeper和系统环境变量文件拷贝到“binghe202”和“binghe203”服务器,具体操作如下:
scp -r /usr/local/zookeeper-3.5.5/ binghe202:/usr/local/
scp -r /usr/local/zookeeper-3.5.5/ binghe203:/usr/local/
sudo scp /etc/profile binghe202:/etc
sudo scp /etc/profile binghe203:/etc注意:拷贝系统环境变量文件“/et/profile”文件的时候,如果提示要求输入密码,根据相应的提示输入密码即可。
5.修改myid文件内容
- 将“binghe202”服务器上Zookeeper的myid文件内容修改为数字2。
在“binghe202”上执行如下命令:
-bash-4.1$ echo "2" > /usr/local/zookeeper-3.5.5/data/myid
-bash-4.1$ cat /usr/local/zookeeper-3.5.5/data/myid
2可以看到Zookeeper文件的内容被成功修改为数字2了。
- 将“binghe203”服务器上Zookeeper的myid文件内容修改为数字3。
在“binghe203”服务器上执行如下命令:
-bash-4.1$ echo "3" > /usr/local/zookeeper-3.5.5/data/myid
-bash-4.1$ cat /usr/local/zookeeper-3.5.5/data/myid
3可以看到Zookeeper文件的内容被成功修改为数字3了。
6.使环境变量生效
分别在“binghe201”、“binghe202”和“binghe203”上执行如下操作,使系统环境变量生效。
source /etc/profile五、搭建并配置Hadoop集群
注意:1-5步是在“binghe201”服务器上执行的操作。
1.下载Hadoop
在“binghe201”上执行如下命令下载Hadoop。
wget mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.2.0/hadoop-3.2.0.tar.gz2.解压并配置系统环境变量
(1)解压Hadoop
输入如下命令对Hadoop进行解压。
tar -zxvf hadoop-3.2.0.tar.gz(2)配置Hadoop系统环境变量
同样,Hadoop的系统环境变量也需要在“/etc/profile”文件中进行相应的配置,通过如下命令打开“/etc/profile”文件并进行相关设置。
sudo vim /etc/profile上述命令可能要求输入密码,根据提示输入密码即可。
在“/etc/profile”文件中添加如下配置:
HADOOP_HOME=/usr/local/hadoop-3.2.0
PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export HADOOP_HOME PATH
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native结合之前配置的JDK和Zookeeper系统环境变量,整体配置信息如下:
JAVA_HOME=/usr/local/jdk1.8.0_212
ZOOKEEPER_HOME=/usr/local/zookeeper-3.5.5
HADOOP_HOME=/usr/local/hadoop-3.2.0
CLASS_PATH=.:$JAVA_HOME/lib
PATH=$JAVA_HOME/bin:$ZOOKEEPER_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export JAVA_HOME ZOOKEEPER_HOME HADOOP_HOME CLASS_PATH PATH
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native(3)使系统环境变量生效
source /etc/profile(4)验证Hadoop系统环境变量是否配置成功
具体验证方式如下所示:
hadoop version
Hadoop 3.2.0
Source code repository https://github.com/apache/hadoop.git -r e97acb3bd8f3befd27418996fa5d4b50bf2e17bf
Compiled by sunilg on 2019-01-08T06:08Z
Compiled with protoc 2.5.0
From source with checksum d3f0795ed0d9dc378e2c785d3668f39
This command was run using /usr/local/hadoop-3.2.0/share/hadoop/common/hadoop-common-3.2.0.jar也就是在命令行输入“hadoop version”命令,可以看到输出了Hadoop的版本号“Hadoop 3.2.0”,说明Hadoop系统环境变量配置成功。
3.修改Hadoop配置文件
Hadoop集群环境的搭建流程基本和Zookeeper集群的搭建流程相同,除了要解压安装包和配置系统环境变量外,还需要对自身框架进行相关的配置。
(1)配置hadoop-env.sh
在hadoop-env.sh文件中,需要指定JAVA_HOME的安装目录,具体如下:
cd /usr/local/hadoop-3.2.0/etc/hadoop/
vim hadoop-env.sh
export JAVA_HOME=/usr/local/jdk1.8.0_212(2)配置core-site.xml
具体配置信息如下:
fs.defaultFS
hdfs://ns/
hadoop.tmp.dir
/usr/local/hadoop-3.2.0/tmp
ha.zookeeper.quorum
binghe201:2181,binghe202:2181,binghe203:2181
(3)配置hdfs-site.xml
具体配置信息如下:
dfs.nameservices
ns
dfs.ha.namenodes.ns
nn1,nn2
dfs.namenode.rpc-address.ns.nn1
binghe201:9000
dfs.namenode.http-address.ns.nn1
binghe201:9870
dfs.namenode.rpc-address.ns.nn2
binghe202:9000
dfs.namenode.http-address.ns.nn2
binghe202:9870
dfs.namenode.shared.edits.dir
qjournal://binghe201:8485;binghe202:8485;binghe203:8485/ns
dfs.journalnode.edits.dir
/usr/local/hadoop-3.2.0/journaldata
dfs.ha.automatic-failover.enabled
true
dfs.client.failover.proxy.provider.ns
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.ha.fencing.methods
sshfence
shell(/bin/true)
dfs.ha.fencing.ssh.private-key-files
/home/hadoop/.ssh/id_rsa
dfs.ha.fencing.ssh.connect-timeout
30000
(4)配置mapred-site.xml
具体配置信息如下:
mapreduce.framework.name
yarn
yarn.app.mapreduce.am.env
HADOOP_MAPRED_HOME=${HADOOP_HOME}
mapreduce.map.env
HADOOP_MAPRED_HOME=${HADOOP_HOME}
mapreduce.reduce.env
HADOOP_MAPRED_HOME=${HADOOP_HOME}
(5)配置yarn-site.xml
具体配置信息如下:
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
binghe203
(6)修改workers文件
这个文件主要是用来存放DataNode节点用的。在Hadoop3.0之前的版本中,这个文件叫作“slaves”。
具体配置信息如下:
binghe201
binghe202
binghe2034.将配置好的Hadoop拷贝到其他节点
将在“binghe101”上安装并配置好的Hadoop复制到其他服务器上,具体操作如下:
scp -r /usr/local/hadoop-3.2.0/ binghe202:/usr/local/
scp -r /usr/local/hadoop-3.2.0/ binghe203:/usr/local/5.将配置好的Hadoop系统环境变量拷贝到其他节点
sudo scp /etc/profile binghe202:/etc/
sudo scp /etc/profile binghe203:/etc/6.使系统环境变量生效
在所有服务器上执行如下命令,使系统环境变量生效,并验证Hadoop系统环境变量是否配置成功。
source /etc/profile
hadoop version可以看到,输入“hadoop version”命令之后,命令行输出了如下信息:
Hadoop 3.2.0
Source code repository https://github.com/apache/hadoop.git -r e97acb3bd8f3befd27418996fa5d4b50bf2e17bf
Compiled by sunilg on 2019-01-08T06:08Z
Compiled with protoc 2.5.0
From source with checksum d3f0795ed0d9dc378e2c785d3668f39
This command was run using /usr/local/hadoop-3.2.0/share/hadoop/common/hadoop-common-3.2.0.jar说明,Hadoop系统环境变量配置成功。
六、启动Zookeeper集群
在三台服务器上分别执行如下命令启动Zookeeper进程。
zkServer.sh start在每台服务器上查看是否存在Zookeeper进程。
- “binghe201”服务器
-bash-4.1$ jps
1476 QuorumPeerMain
1514 Jps- “binghe202”服务器
-bash-4.1$ jps
1507 Jps
1462 QuorumPeerMain- “binghe203”服务器
-bash-4.1$ jps
1460 QuorumPeerMain
1498 Jps可以看到每天服务器上都启动了Zookeeper进程。
查看每台服务器上Zookeeper的运行模式,具体如下所示。
- “binghe201”服务器
-bash-4.1$ zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper-3.5.5/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost.
Mode: follower- “binghe202”服务器
-bash-4.1$ zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper-3.5.5/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost.
Mode: leader- “binghe203”服务器
-bash-4.1$ zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper-3.5.5/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost.
Mode: follower可以看到,在“binghe202”服务器上运行的Zookeeper为“leader”,在“binghe201”和“binghe203”服务器上运行的Zookeeper为“follower”,说明:Zookeeper集群搭建并启动成功。
七、启动Hadoop集群
启动搭建的精简版的Hadoop集群,同样需要启动journalnode进程、格式化HDFS、格式化ZKFC、启动HDFS和启动YARN。具体操作步骤如下(注意:需要严格按照以下步骤启动Hadoop集群)。
1.启动并验证journalnode进程
(1)启动journalnode进程
在“binghe201”服务器上执行如下命令启动journalnode进程。
hdfs --workers --daemon start journalnode注意:在Hadoop 3.0以前是输入如下命令启动journalnode进程。
hadoop-daemons.sh start journalnode(2)验证journalnode进程是否启动成功
在三台服务器上分别执行“jps”命令查看是否存在journalnode进程,以此确认journalnode进程是否启动成功。
- “binghe201”服务器
-bash-4.1$ jps
1476 QuorumPeerMain
1669 Jps
1640 JournalNode- “binghe202”服务器
-bash-4.1$ jps
1633 Jps
1462 QuorumPeerMain
1594 JournalNode- “binghe203”服务器
-bash-4.1$ jps
1585 JournalNode
1460 QuorumPeerMain
1624 Jps可以看到,三台服务器均启动了journalnode进程,说明journalnode进程启动成功。
2.格式化HDFS
在“binghe201”服务器上执行如下命令格式化HDFS。
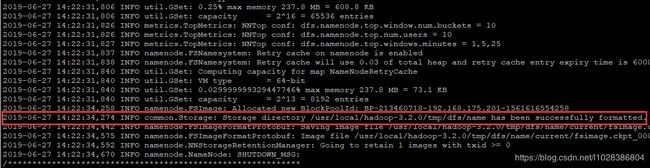
hdfs namenode -format格式化成功之后,会输出“common.Storage: Storage directory /usr/local/hadoop-3.2.0/tmp/dfs/name has been successfully formatted.”信息,并在HADOOP_HOME(/usr/local/hadoop-3.2.0/)目录下自动创建tmp目录。具体如图所示。
3.格式化ZKFC
在“binghe201”服务器上执行如下命令格式化ZKFC。
hdfs zkfc -formatZK格式化成功之后,会输出“ha.ActiveStandbyElector: Successfully created /hadoop-ha/ns in ZK.”信息。具体如图所示。

4.启动NameNode并验证
(1)启动NameNode
在“binghe201”服务器上执行如下命令启动NameNode。
hdfs --daemon start namenode注意:在Hadoop3.0以前的版本启动NameNode是输入如下的命令:
hadoop-daemon.sh start namenode(2)验证NameNode是否启动成功
在“binghe201”服务器上输入“jps”命令查看是否存在NameNode进程,以此确认NameNode是否启动成功,具体如下:
-bash-4.1$ jps
1892 Jps
1476 QuorumPeerMain
1640 JournalNode
1852 NameNode从输出结果可以看出,存在“NameNode”进程,说明NameNode启动成功。
5.同步元数据信息
在“binghe202”服务器上执行如下命令进行元数据信息的同步操作。
hdfs namenode -bootstrapStandby
同步元数据信息的时候输出了“common.Storage: Storage directory /usr/local/hadoop-3.2.0/tmp/dfs/name has been successfully formatted.”信息,说明同步元数据信息成功。
6.启动并验证备用NameNode
(1)启动备用NameNode
在“binghe202”服务器上执行如下命令启动备用NameNode。
hdfs --daemon start namenode
注意:在Hadoop3.0以前的版本启动NameNode是输入如下的命令:
hadoop-daemon.sh start namenode(2)验证备用NameNode是否启动成功
在“binghe202”服务器上输入“jps”命令查看是否存在NameNode进程,以此确认备用NameNode是否启动成功,具体如下:
-bash-4.1$ jps
1750 NameNode
1462 QuorumPeerMain
1816 Jps
1594 JournalNode从输出结果可以看出,存在“NameNode”进程,说明备用NameNode启动成功。
7.启动并验证DataNode
(1)启动DataNode
在“binghe201”服务器上执行如下命令启动DataNode。
hdfs --workers --daemon start datanode
注意:在Hadoop3.0以前的版本启动DataNode是输入如下的命令:
hadoop-daemons.sh start datanode(2)验证DataNode是否启动成功
在三台服务器分别输入“jps”命令,查看是否存在“DataNode”进程,以此确认DataNode是否启动成功。
- “binghe201”服务器
-bash-4.1$ jps
2145 DataNode
1476 QuorumPeerMain
2231 Jps
1640 JournalNode
1852 NameNode- “binghe202”服务器
-bash-4.1$ jps
1750 NameNode
1462 QuorumPeerMain
1962 DataNode
1594 JournalNode
2063 Jps- “binghe203”服务器
-bash-4.1$ jps
1585 JournalNode
1460 QuorumPeerMain
1703 DataNode
1771 Jps由输出结果可以看出,三台服务器中均启动了“DataNode”进程,说明DataNode启动成功。
8.启动并验证YARN
(1)启动YARN
在“binghe203”服务器上执行如下命令启动YARN。
start-yarn.sh(2)验证YARN是否启动成功
在三台服务器上执行“jps”命令来验证YARN是否启动成功。
- “binghe201”服务器
-bash-4.1$ jps
2464 Jps
2145 DataNode
1476 QuorumPeerMain
1640 JournalNode
2329 NodeManager
1852 NameNode- “binghe202”服务器
-bash-4.1$ jps
2147 NodeManager
1750 NameNode
1462 QuorumPeerMain
1962 DataNode
1594 JournalNode
2284 Jps- “binghe203”服务器
-bash-4.1$ jps
1585 JournalNode
2354 Jps
1460 QuorumPeerMain
1989 NodeManager
1703 DataNode
1883 ResourceManager由输出结果可以看出“ResourceManager”进程存在于“binghe203”服务器上;“NodeManager”进程存在于“binghe201”、“binghe202”和“binghe203”服务器上。说明YARN启动成功。
9.启动并验证ZKFC
(1)启动ZKFC
在“binghe201”服务器上执行如下命令启动ZKFC。
hdfs --workers --daemon start zkfc
注意:在Hadoop3.0以前的版本中,启动ZKFC需要使用如下命令:
hadoop-daemons.sh start zkfc (2)验证ZKFC是否启动成功
在“binghe201”和“binghe202”服务器上分别执行“jps”命令,查看是否存在“DFSZKFailoverController”进程。
- “binghe201”服务器
-bash-4.1$ jps
2145 DataNode
1476 QuorumPeerMain
1640 JournalNode
2329 NodeManager
1852 NameNode
2734 Jps
2670 DFSZKFailoverController- “binghe202”服务器
-bash-4.1$ jps
2147 NodeManager
2484 Jps
1750 NameNode
1462 QuorumPeerMain
2439 DFSZKFailoverController
1962 DataNode
1594 JournalNode由输出结果可以看出,两台服务器均启动了“DFSZKFailoverController”进程,说明ZKFC启动成功。
八、启动Hadoop集群的另一种方式
这种方式要比每次启动单个进程并进行验证方便的多,只需要进行如下操作:
1.格式化HDFS
在“binghe201”服务器上执行如下命令格式化HDFS。
hdfs namenode -format2.复制元数据信息
将“binghe201”服务器上的“/usr/local/hadoop-3.2.0/tmp/”目录复制到服务器“binghe202”服务上的“/usr/local/hadoop-3.2.0”目录下。
在“binghe201”服务器上执行如下命令进行复制:
scp -r /usr/local/hadoop-3.2.0/tmp/ binghe202:/usr/local/hadoop-3.2.0/3.格式化ZKFC
在“binghe201”服务器上执行如下命令格式化ZKFC。
hdfs zkfc -formatZK4.启动HDFS
在“binghe201”服务器上执行启动HDFS的命令,具体如下所示:
start-dfs.sh5.启动YARN
在“binghe203”服务器上执行启动YARN的命令,具体如下所示:
start-yarn.sh九、 测试Hadoop HA的高可用性
使用浏览器方式验证和程序方式验证两种方式来验证Hadoop HA的高可用性。
1.浏览器方式验证
(1)浏览器访问NameNode
- 访问“binghe201”服务器上的NameNode
在浏览器中输入链接:http://192.168.175.201:9870 访问“binghe201”服务器上的NameNode
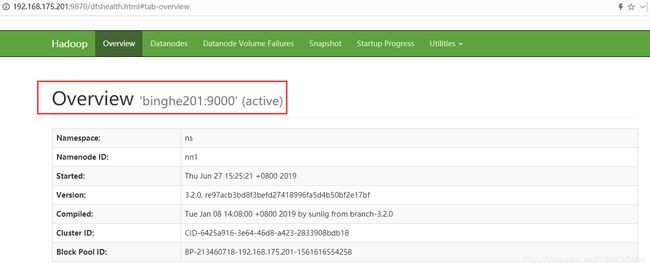
此时,“binghe201”服务器上的NameNode处于“active”状态。
- 访问“binghe202”服务器上的NameNode
在浏览器中输入链接:http://192.168.175.202:9870 访问“binghe202”服务器上的NameNode
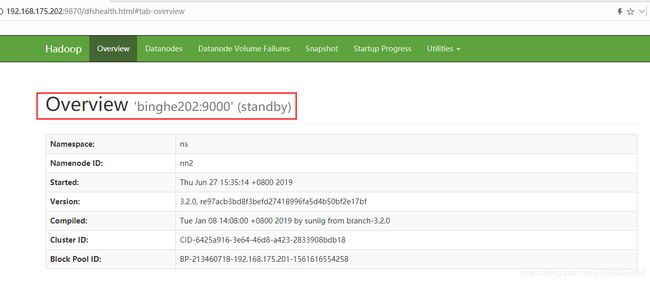
此时,“binghe202”服务器上的NameNode处于“standby”状态。
(2)停止“binghe201”上的NameNode后访问
- 停止“binghe201”上的NameNode进程
在“binghe201”服务器上执行如下命令停止NameNode进程。
hdfs --daemon stop namenode
注意:在Hadoop3.0之前的版本停止NameNode进程需要输入以下命令:
hadoop-daemon.sh stop namenode- 浏览器访问“binghe201”服务器上的NameNode
在浏览器中输入链接:http://192.168.175.201:9870 访问“binghe201”服务器上的NameNode
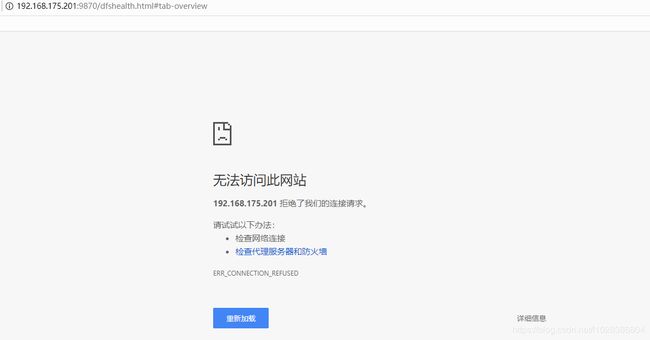
可以看到,由于停止了“binghe201”服务器上的NameNode进程,导致此服务器上的NameNode已无法访问。
- 浏览器访问“binghe202”服务器上的NameNode
在浏览器中输入链接:http://192.168.175.202:9870 访问“binghe202”服务器上的NameNode

可以看到,由于“binghe201”服务器上的NameNode无法访问,“binghe202”服务器上的NameNode自动切换为“active”状态。
(3)重启“binghe201”上的NameNode访问
首先,在“binghe201”服务器上执行如下命令启动NameNode进程。
hdfs --daemon start namenode
注意:在Hadoop3.0之前的版本启动NameNode进程需要输入以下命令:
hadoop-daemon.sh stop namenode接下来访问“binghe201”服务器上的NameNode
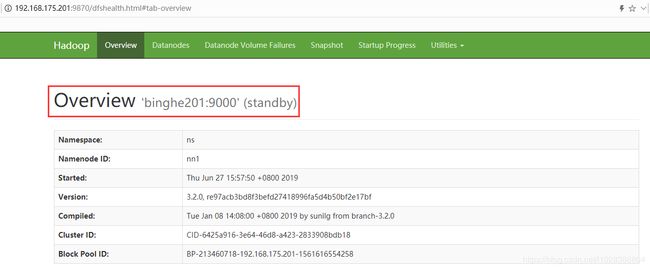
总结:正常启动NameNode进程后,“binghe201”服务器上的NameNode处于“active”状态,“binghe202”服务器上的NameNode处于“standby”状态;当停止“binghe201”服务器上的NameNode时,“binghe202”服务器上的NameNode自动切换为“active”状态,而重启“binghe201”服务器上的NameNode后,“binghe201”服务器上的NameNode此时会处于“standby”状态。说明:Hadoop HA搭建并配置成功了。
2.程序方式验证
以程序方式验证,还是运行Hadoop自带的wordcount程序,对文件中的单词进行计数,并输出统计结果。
(1)准备数据文件
在“binghe201”服务器上准备数据文件data.input,并写入测试的单词。具体如下:
vim data.input
hadoop mapreduce hive flume
hbase spark storm flume
sqoop hadoop hive kafka
spark hadoop storm(2)上传数据文件到HDFS
首先,在HDFS上创建目录“/data /input”,具体命令如下:
hadoop fs -mkdir -p /data/input在“binghe201”上执行如下命令将data.input文件上传到HDFS分布式文件系统中的“/data/hadoop/input”目录下,具体命令如下:
hadoop fs -put data.input /data/input接下来查看文件data.input是否上传成功,具体命令如下:
-bash-4.1$ hadoop fs -ls /data/input
Found 1 items
-rw-r--r-- 3 hadoop supergroup 96 2019-06-27 17:04 /data/input/data.input可以看到,data.input文件已经成功上传到HDFS分布式文件系统的“/data/hadoop/input”目录下。
(3)运行Hadoop MapReduce程序
具体执行命令如下:
hadoop jar /usr/local/hadoop-3.2.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.0.jar wordcount /data/input/data.input /data/output201注意:这里的输出目录是HDFS上的“/data/output201”目录。
(4)查看执行结果
首先,利用如下命令查看HDFS中是否产生了输出结果。
-bash-4.1$ hadoop fs -ls /data/output201
Found 2 items
-rw-r--r-- 3 hadoop supergroup 0 2019-06-27 17:16 /data/output201/_SUCCESS
-rw-r--r-- 3 hadoop supergroup 76 2019-06-27 17:16 /data/output201/part-r-00000可以看到在HDFS的“/data/output101”目录下产生了执行结果,接下来查看“part-r-00000”文件的内容,具体如下:
-bash-4.1$ hadoop fs -cat /data/output201/part-r-00000
flume 2
hadoop 3
hbase 1
hive 2
kafka 1
mapreduce 1
spark 2
sqoop 1
storm 2可以看到,正确地输出了每个单词和单词对应的数量。
(5)停止“binghe201”服务器上的NameNode进程
hdfs --daemon stop namenode
注意:在Hadoop3.0之前的版本停止NameNode进程需要输入以下命令:
hadoop-daemon.sh stop namenode(6)再次运行MapReduce程序
hadoop jar /usr/local/hadoop-3.2.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.0.jar wordcount /data/input/data.input /data/output202注意:这里的输出目录是HDFS上的“/data/output202”目录。
(7)再次查看执行结果
首先,利用如下命令查看HDFS中是否产生了输出结果。
-bash-4.1$ hadoop fs -ls /data/output202
Found 2 items
-rw-r--r-- 3 hadoop supergroup 0 2019-06-27 17:20 /data/output202/_SUCCESS
-rw-r--r-- 3 hadoop supergroup 76 2019-06-27 17:20 /data/output202/part-r-00000可以看到在HDFS的“/data/output102”目录下产生了执行结果,接下来查看“part-r-00000”文件的内容,具体如下:
-bash-4.1$ hadoop fs -cat /data/output202/part-r-00000
flume 2
hadoop 3
hbase 1
hive 2
kafka 1
mapreduce 1
spark 2
sqoop 1
storm 2说明集群搭建成功。