原博客地址:http://blog.csdn.net/evankaka
摘要:本文主要讲了笔者在使用sqoop过程中的一些实例
一、概述与基本原理
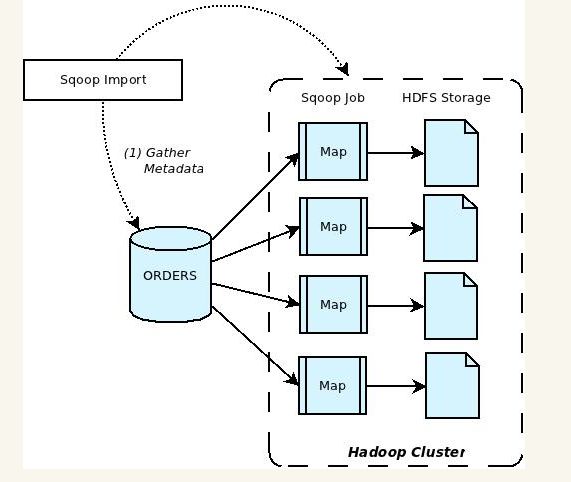
Apache Sqoop(SQL-to-Hadoop) 项目旨在协助 RDBMS 与 Hadoop 之间进行高效的大数据交流。用户可以在 Sqoop 的帮助下,轻松地把关系型数据库的数据导入到 Hadoop 与其相关的系统 (如Hbase和Hive)中;同时也可以把数据从 Hadoop 系统里抽取并导出到关系型数据库里。因此,可以说Sqoop就是一个桥梁,连接了关系型数据库与Hadoop。qoop中一大亮点就是可以通过hadoop的mapreduce把数据从关系型数据库中导入数据到HDFS。Sqoop架构非常简单,其整合了Hive、Hbase和Oozie,通过map-reduce任务来传输数据,从而提供并发特性和容错。Sqoop的基本工作流程如下图所示:
从关系数据库到Hive/hbase
从Hive/hbase到关系数据库
Sqoop在import时,需要制定split-by参数。Sqoop根据不同的split-by参数值来进行切分,然后将切分出来的区域分配到不同map中。每个map中再处理数据库中获取的一行一行的值,写入到HDFS中(由此也可知,导入导出的事务是以Mapper任务为单位)。同时split-by根据不同的参数类型有不同的切分方法,如比较简单的int型,Sqoop会取最大和最小split-by字段值,然后根据传入的num-mappers来确定划分几个区域。 比如select max(split_by),min(split-by) from得到的max(split-by)和min(split-by)分别为1000和1,而num-mappers为2的话,则会分成两个区域(1,500)和(501-100),同时也会分成2个sql给2个map去进行导入操作,分别为select XXX from table where split-by>=1 and split-by<500和select XXX from table where split-by>=501 and split-by<=1000。最后每个map各自获取各自SQL中的数据进行导入工作。
二、使用实例
接下来将以实例来说明如何使用
1、创建表
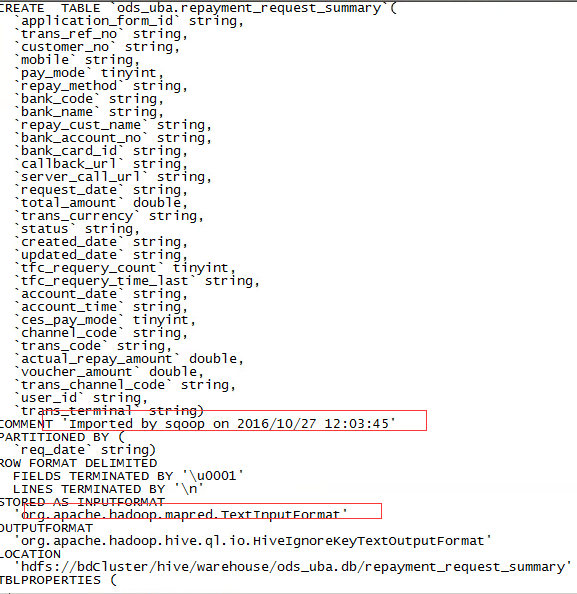
sqoop可以将MySQL表或其它关系型数据库的表结构自动映射到Hive表。映射后的表结构为textfile格式。先来看一个脚本
- #!/bin/sh
- . ~/.bashrc
-
- host='xx.xx.xx.xx'
- database='cescore'
- user='xxxx'
- password='xxxx'
- mysqlTable='yyyyyyy'
- hiveDB='ods_uba'
- hiveTable='yyyyyy'
-
- sqoop create-hive-table \
- --connect jdbc:mysql://${host}:3306/${database} --username ${user} --password ${password} \
- --table ${mysqlTable} \
- --hive-table ${hiveDB}.${hiveTable} \
- --hive-overwrite --hive-partition-key req_date \
-
- rm *.java
--connect 指明连接的类型,基本所有的关系型数据库都可以
--table 指明要源表的表名
--hive-table 指明要创建的Hive表名
--hive-overwrite 指明是否覆盖插入(将原来的分区数据全删除,再插入)
--hive-partition-key 指明分区的字段
我们可以到Hive去查看对应的表结构:
2、从mysql导数据到Hive
sqoop可以将数据从关系型数据库导到Hive或Hive导到关系型数据库,先来看一个从mydql导数据到Hive的实例,示例脚本如下
先来看一个脚本
- #!/bin/sh
- . ~/.bashrc
-
- host='xx.xx.xx.xx'
- database='xxxcc'
- user='xxxx'
- password='xxxx'
- mysqlTable='sys_approve_reject_code'
- hiveDB='ods_uba'
- hiveTable='sys_approve_reject_code'
- tmpDir='/user/hive/warehouse/ods_uba.db/'${hiveTable}
-
- sqoop import --connect jdbc:mysql://${host}:3306/${database} --username ${user} --password ${password} \
- --query "select * from "${database}"."${mysqlTable}" where 1 = 1 and \$CONDITIONS" \
- --hive-import --hive-table ${hiveDB}.${hiveTable} --target-dir ${tmpDir} --delete-target-dir --split-by approve_reject_code \
- --hive-overwrite \
- --null-string '\\N' --null-non-string '\\N'
一般情况下,如果Hive里的表不存在,也可以不用执行第一步的创建表的步骤,因为一般导数时,它如果发现hive表不存在,会自己帮你创建表,Hive表的数据结构就和mysql的一样。不过,这样要注意一个点,如果Hive表是你自己通过Hive的交互命令行建立起来的,并且存储格式设置为orc,那么使用sqoop导数据到这个表时是可以导入成功,但是会发现无法查询出来,或者查询乱码。只能设置成textfile才可以。
上面的sql是将表全量导入到Hive中,不进行分区操作,每次导数都会将原来的数据删除,因为这是一张字典表,所以需要这么做。来看看各字段的含义
--query 指明查询的sql语句,注意主里加了一个 and \$conditions ,这是必需的,如果有带where条件的话
--hive-table 指明目标表名
--target-dir 指明目标表的hdfs路径
--delete-target-dir 删除目标hfds路径数据
--split-by 指明shuffle的字段,一般是取主键
--hive-overwrite 先删除旧数据,再重新插入
--null-string --对null字符串和处理,映射成hive里的null
--null-non-string --对null非字符串和处理,映射成hive里的null
3、从phoenix导数据到Hive
下面再来看一个比较复杂的脚本,这里将从phoenix导数据,并将一天的数据分成24份
- #!/bin/sh
- . ~/.bashrc
-
- #导数据,注意要传入一个yyyy-mm-dd类型参数
- synData(){
- echo "您要统计数据的日期为:$statisDate"
- #生成每小时的查询条件
- for i in `seq 24`
- do
- num=$(echo $i)
- doSqoop $statisDate $num
- done
- }
-
- #sqoop导数据
- doSqoop(){
- echo "输入日期:$statisDate,输入序列号:$num"
- timeZone=$(printf "%02d\n" $(expr "$num" - "1"))
- partitionTime=$(echo "$statisDate-$timeZone")
- evtNOPre=$(echo $partitionTime | sed 's/\-//g')
- echo "分区字段:$partitionTime"
- where_qry=$(echo "evt_no like '$evtNOPre%'")
- echo $where_qry
-
- hiveDB='ods_uba'
- hiveTable='evt_log'
- tmpDir='/user/hive/warehouse/ods_uba.db/'${hiveTable}
-
- sqoop import -D mapreduce.map.memory.mb=3072 --driver org.apache.phoenix.jdbc.PhoenixDriver \
- --connect jdbc:phoenix:xxxxxxxx \
- --query "select * from uba.evt_log where $where_qry and \$CONDITIONS" \
- --hive-import --hive-table ${hiveDB}.${hiveTable} --target-dir ${tmpDir} --delete-target-dir --split-by evt_no \
- --hive-overwrite --hive-partition-key partition_time --hive-partition-value ${partitionTime} \
- --null-string '\\N' --null-non-string '\\N'
- rm *.java
-
- }
-
- #统计日期默认取昨天
- diffday=1
- statisDate=`date +"%Y-%m-%d" -d "-"${diffday}"day"`
- #首先判断是否有输入日期,以及输入日期是否合法,如果合法,取输入的日期。不合法报错,输入日期为空,取昨天
- if [ $# -eq 0 ]; then
- echo "您没有输入参数"
- synData $statisDate
- elif [ $# -eq 1 ]; then
- echo "您输入参数为: $1 "
- statisDate=$1
- if [ ${#statisDate} -eq 10 ];then
- synData $statisDate
- else
- echo "您输入日期不合法,请输入yyyy-mm-dd类型参数"
- fi
- else
- echo "您输入参数多于一个,请不要输入或只输入一个yyyy-mm-dd类型参数"
- fi
-D mapreduce.map.memory.mb=3072,这是一个非常有用的参数,一般如果数据量非常大,在抽数据时有可能报内存不足,这时可以通过调高这个参数。
--driver 这里指明了使用的驱动类型,注意要将对应的驱动连接包放到sqoop对应的lib目录下,要不会报错
--hive-partition-key 指明分区字段
--hive-partition-value 指明分区值
这里因为是每天抽数,所以按天进行分区,因为还将每天分成了24个小时,理论上讲设置成两个分区字段会好点,但是sqoop只支持设置一个分区字段,所以这里的分区字段会被设计成yyyy-mm-dd-hh的类型
4、从mysql到hbse
- sqoop import --connect jdbc:mysql://localhost/acmedb \
- --table ORDERS --username test --password **** \
- --hbase-create-table --hbase-table ORDERS --column-family mysql
- ----
--hbase-create-table: 指明使用sqoop创建hbse表
--hbase-table: hbase表
--column-family: --指明列族,将所有的mysql的列都放在这个列族下面