在Android使用opengles实现Winograd卷积算法
测试用数据
输入:

卷积核为:
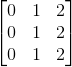
padding为SAME
使用opengles的imageArray存储输入输出数据,纹理格式为rgba16f,为将纹理坐标与输入矩阵坐标一一对应,所以需要先将输入进行补零操作。先将输入矩阵拉平为一个一维向量,再对这个一维向量每个数字后补3个零,然后传入到一个5x5的gl纹理上,这样纹理坐标就与输入坐标一一对应了。
对卷积核先做预计算,然后将卷积预计算得到的 GgGt矩阵用纹理存储
private void transferKernelToGgGt(float[][][][] mKennels) {
int kennel_amount = mKennels.length;
int kennel_channel = mKennels[0].length;
float[][][][] GgGt = new float[kennel_amount][kennel_channel][4][4];
float[][] G = new float[][]{{1, 0, 0}, {0.5f, 0.5f, 0.5f}, {0.5f, -0.5f, 0.5f}, {0, 0, 1}};
float[][] Gt = Numpy.transpose(G);
for (int a = 0; a < kennel_amount; a++) {
for (int c = 0; c < kennel_channel; c++) {
GgGt[a][c] = Numpy.dot(Numpy.dot(G, mKennels[a][c]), Gt);
}
}
int align_c = Utils.alignBy4(kennel_channel);
float[][][] GgGt_align = new float[kennel_amount][align_c / 4][16 * 4 + 4]; // depth == 0 处 最后一列第一个为 bias
for (int a = 0; a < kennel_amount; a++) {
for (int c = 0; c < kennel_channel; c++) {
for (int h = 0; h < 4; h++) {
for (int w = 0; w < 4; w++) {
GgGt_align[a][c / 4][(w + h * 4) * 4 + c % 4] = GgGt[a][c][h][w];
}
}
}
}
// 添加bias项
for (int a = 0; a < kennel_amount; a++) {
GgGt_align[a][0][16 * 4] = 0.01f * a;
}
// 传输到纹理
for (int a = 0; a < kennel_amount; a++) {
float[][] kennel = GgGt_align[a];
int depth = kennel.length;
for (int c = 0; c < depth; c++) {
Render.transferToTextureArrayFloat(FloatBuffer.wrap(kennel[c]), mKennelTex, 0, a, c, 17, 1, 1);
}
}
}每个卷积核GgGt矩阵都只用纹理的一行存储,存储shape为16x1,如果需要在卷积时加入bias,可再加一列存储bias,并将存储shape改为17x1。
所有卷积核的GgGt均存储再一张纹理上,按卷积核顺序,在纹理上由上到下依次排列。
输出为5x5,可以将其转化为3x3个2x2的输出(将5x5补零为6x6),以便应用Winograd算法。每个shader只处理一个2x2的输出,以便进行并行计算。
shader的主要逻辑
// 卷积数据数据坐标
int conv_x0 = pad_w + start_x;
int conv_y0 = pad_h + start_y;
int conv_x1 = conv_x0 + 1;
int conv_y1 = conv_y0 + 1;
int conv_x2 = conv_x1 + 1;
int conv_y2 = conv_y1 + 1;
int conv_x3 = conv_x2 + 1;
int conv_y3 = conv_y2 + 1;
for (int c = 0; c < in_depth; c++) {
// 从输入纹理读取数据
vec4 data00 = imageLoad(input_image, ivec3(conv_x0, conv_y0, c));
vec4 data01 = imageLoad(input_image, ivec3(conv_x1, conv_y0, c));
vec4 data02 = imageLoad(input_image, ivec3(conv_x2, conv_y0, c));
vec4 data03 = imageLoad(input_image, ivec3(conv_x3, conv_y0, c));
vec4 data10 = imageLoad(input_image, ivec3(conv_x0, conv_y1, c));
vec4 data11 = imageLoad(input_image, ivec3(conv_x1, conv_y1, c));
vec4 data12 = imageLoad(input_image, ivec3(conv_x2, conv_y1, c));
vec4 data13 = imageLoad(input_image, ivec3(conv_x3, conv_y1, c));
vec4 data20 = imageLoad(input_image, ivec3(conv_x0, conv_y2, c));
vec4 data21 = imageLoad(input_image, ivec3(conv_x1, conv_y2, c));
vec4 data22 = imageLoad(input_image, ivec3(conv_x2, conv_y2, c));
vec4 data23 = imageLoad(input_image, ivec3(conv_x3, conv_y2, c));
vec4 data30 = imageLoad(input_image, ivec3(conv_x0, conv_y3, c));
vec4 data31 = imageLoad(input_image, ivec3(conv_x1, conv_y3, c));
vec4 data32 = imageLoad(input_image, ivec3(conv_x2, conv_y3, c));
vec4 data33 = imageLoad(input_image, ivec3(conv_x3, conv_y3, c));
// 提取公共计算
vec4 d00_20_sub = data00 - data20;
vec4 d01_21_sub = data01 - data21;
vec4 d02_22_sub = data02 - data22;
vec4 d03_23_sub = data03 - data23;
vec4 d10_20_add = data10 + data20;
vec4 d11_21_add = data11 + data21;
vec4 d12_22_add = data12 + data22;
vec4 d13_23_add = data13 + data23;
vec4 d20_10_sub = data20 - data10;
vec4 d21_11_sub = data21 - data11;
vec4 d22_12_sub = data22 - data12;
vec4 d23_13_sub = data23 - data13;
vec4 d10_30_sub = data10 - data30;
vec4 d11_31_sub = data11 - data31;
vec4 d12_32_sub = data12 - data32;
vec4 d13_33_sub = data13 - data33;
// 计算BtdB矩阵
vec4 BtdB00 = d00_20_sub - d02_22_sub;
vec4 BtdB01 = d01_21_sub + d02_22_sub;
vec4 BtdB02 = d02_22_sub - d01_21_sub;
vec4 BtdB03 = d01_21_sub - d03_23_sub;
vec4 BtdB10 = d10_20_add - d12_22_add;
vec4 BtdB11 = d11_21_add + d12_22_add;
vec4 BtdB12 = d12_22_add - d11_21_add;
vec4 BtdB13 = d11_21_add - d13_23_add;
vec4 BtdB20 = d20_10_sub - d22_12_sub;
vec4 BtdB21 = d21_11_sub + d22_12_sub;
vec4 BtdB22 = d22_12_sub - d21_11_sub;
vec4 BtdB23 = d21_11_sub - d23_13_sub;
vec4 BtdB30 = d10_30_sub - d12_32_sub;
vec4 BtdB31 = d11_31_sub + d12_32_sub;
vec4 BtdB32 = d12_32_sub - d11_31_sub;
vec4 BtdB33 = d11_31_sub - d13_33_sub;
for (int i = 0; i < 4; i++) {
int z_i = z_0 + i;
// 从卷积核纹理读取GgGt矩阵
vec4 GgGt00_0 = imageLoad(kernel_image, ivec3(0, z_i, c));
vec4 GgGt01_0 = imageLoad(kernel_image, ivec3(1, z_i, c));
vec4 GgGt02_0 = imageLoad(kernel_image, ivec3(2, z_i, c));
vec4 GgGt03_0 = imageLoad(kernel_image, ivec3(3, z_i, c));
vec4 GgGt10_0 = imageLoad(kernel_image, ivec3(4, z_i, c));
vec4 GgGt11_0 = imageLoad(kernel_image, ivec3(5, z_i, c));
vec4 GgGt12_0 = imageLoad(kernel_image, ivec3(6, z_i, c));
vec4 GgGt13_0 = imageLoad(kernel_image, ivec3(7, z_i, c));
vec4 GgGt20_0 = imageLoad(kernel_image, ivec3(8, z_i, c));
vec4 GgGt21_0 = imageLoad(kernel_image, ivec3(9, z_i, c));
vec4 GgGt22_0 = imageLoad(kernel_image, ivec3(10, z_i, c));
vec4 GgGt23_0 = imageLoad(kernel_image, ivec3(11, z_i, c));
vec4 GgGt30_0 = imageLoad(kernel_image, ivec3(12, z_i, c));
vec4 GgGt31_0 = imageLoad(kernel_image, ivec3(13, z_i, c));
vec4 GgGt32_0 = imageLoad(kernel_image, ivec3(14, z_i, c));
vec4 GgGt33_0 = imageLoad(kernel_image, ivec3(15, z_i, c));
vec4 m00_0 = BtdB00 * GgGt00_0;
vec4 m01_0 = BtdB01 * GgGt01_0;
vec4 m02_0 = BtdB02 * GgGt02_0;
vec4 m03_0 = BtdB03 * GgGt03_0;
vec4 m10_0 = BtdB10 * GgGt10_0;
vec4 m11_0 = BtdB11 * GgGt11_0;
vec4 m12_0 = BtdB12 * GgGt12_0;
vec4 m13_0 = BtdB13 * GgGt13_0;
vec4 m20_0 = BtdB20 * GgGt20_0;
vec4 m21_0 = BtdB21 * GgGt21_0;
vec4 m22_0 = BtdB22 * GgGt22_0;
vec4 m23_0 = BtdB23 * GgGt23_0;
vec4 m30_0 = BtdB30 * GgGt30_0;
vec4 m31_0 = BtdB31 * GgGt31_0;
vec4 m32_0 = BtdB32 * GgGt32_0;
vec4 m33_0 = BtdB33 * GgGt33_0;
//提取输出的公共计算
vec4 m01_11_21_0 = m01_0 + m11_0 + m21_0;
vec4 m02_12_22_0 = m02_0 + m12_0 + m22_0;
vec4 m11_21_31_0 = m11_0 - m21_0 - m31_0;
vec4 m12_22_32_0 = m12_0 - m22_0 - m32_0;
//合并为输出
result00[i] += sum(m00_0 + m10_0 + m20_0 + m01_11_21_0 + m02_12_22_0);
result01[i] += sum(m01_11_21_0 - m02_12_22_0 - m03_0 - m13_0 - m23_0);
result10[i] += sum(m10_0 - m20_0 - m30_0 + m11_21_31_0 + m12_22_32_0);
result11[i] += sum(m11_21_31_0 - m12_22_32_0 - m13_0 + m23_0 + m33_0);
}
}
测试结果:

输出结果为:

全部代码