CS231n Spring 2019 Assignment 3—vanilla RNN/LSTM for image captioning
vanilla RNN/LSTM for image captioning
- Vanilla RNN
- Vanilla RNN: step forward/backward
- Vanilla RNN: forward/backward
- Word embedding: forward/backward
- RNN for image captioning
- Test-time sampling
- LSTM(Long Short Term Memory)
- LSTM: step forward/backward
- LSTM: forward/backward
- LSTM captioning model/test-time sampling
- 结果
- 链接
Assignment 3的前两个就是RNN_Captioning.ipynb和LSTM_Captioning.ipynb,这两个主要就是利用RNN(Recurrent Neural Network循环神经网络)来为图像打标注,因为里面涉及到词语,所以会设计到词嵌入(Word Embedding)的部分。这是我的Assignment 3
Vanilla RNN
这是我的RNN_Captioning.ipynb
Image Captioning主要是利用了Microsoft COCO数据集,作者已经定义好一些接口方便我们调用:
- cs231n.coco_utils
- decode_captions:传入caption,返回对应的caption_str,这里的caption就是对应每个单词的整数索引,而caption_str就是图片的词语描述了。
- cs231n.image_utils
- image_from_url:传入图片的url,得到图片。
Vanilla RNN: step forward/backward
这里主要要写单步的RNN前向/反向传播,只要知道了公式就很好写出来:
h t = t a n h ( x W x + h t − 1 W h + b ) h_{t}=tanh(xW_{x}+h_{t-1}W_{h}+b) ht=tanh(xWx+ht−1Wh+b)
而反向传播的时候知道上游梯度 d h t dh_{t} dht之后,根据 t a n h ′ ( x ) = 1 − t a n h 2 ( x ) tanh'(x)=1-tanh^{2}(x) tanh′(x)=1−tanh2(x),之后就跟线性层一样了(其实反向传播最好看着计算图一步一步写),具体看下面的代码部分:
def rnn_step_forward(x, prev_h, Wx, Wh, b):
"""
Run the forward pass for a single timestep of a vanilla RNN that uses a tanh
activation function.
The input data has dimension D, the hidden state has dimension H, and we use
a minibatch size of N.
Inputs:
- x: Input data for this timestep, of shape (N, D).
- prev_h: Hidden state from previous timestep, of shape (N, H)
- Wx: Weight matrix for input-to-hidden connections, of shape (D, H)
- Wh: Weight matrix for hidden-to-hidden connections, of shape (H, H)
- b: Biases of shape (H,)
Returns a tuple of:
- next_h: Next hidden state, of shape (N, H)
- cache: Tuple of values needed for the backward pass.
"""
next_h, cache = None, None
##############################################################################
# TODO: Implement a single forward step for the vanilla RNN. Store the next #
# hidden state and any values you need for the backward pass in the next_h #
# and cache variables respectively. #
##############################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
next_h = np.tanh(x.dot(Wx) + prev_h.dot(Wh) + b)
cache = (x, prev_h, Wx, Wh, b, next_h)
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
##############################################################################
# END OF YOUR CODE #
##############################################################################
return next_h, cache
def rnn_step_backward(dnext_h, cache):
"""
Backward pass for a single timestep of a vanilla RNN.
Inputs:
- dnext_h: Gradient of loss with respect to next hidden state, of shape (N, H)
- cache: Cache object from the forward pass
Returns a tuple of:
- dx: Gradients of input data, of shape (N, D)
- dprev_h: Gradients of previous hidden state, of shape (N, H)
- dWx: Gradients of input-to-hidden weights, of shape (D, H)
- dWh: Gradients of hidden-to-hidden weights, of shape (H, H)
- db: Gradients of bias vector, of shape (H,)
"""
dx, dprev_h, dWx, dWh, db = None, None, None, None, None
##############################################################################
# TODO: Implement the backward pass for a single step of a vanilla RNN. #
# #
# HINT: For the tanh function, you can compute the local derivative in terms #
# of the output value from tanh. #
##############################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
x, prev_h, Wx, Wh, b, next_h = cache
dx = np.dot((1 - next_h ** 2) * dnext_h, Wx.T)
dprev_h = np.dot((1 - next_h ** 2) * dnext_h, Wh.T)
dWx = np.dot(x.T, (1 - next_h ** 2) * dnext_h)
dWh = np.dot(prev_h.T, (1 - next_h ** 2) * dnext_h)
db = np.sum((1 - next_h ** 2) * dnext_h, axis=0)
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
##############################################################################
# END OF YOUR CODE #
##############################################################################
return dx, dprev_h, dWx, dWh, db
Vanilla RNN: forward/backward
这里就不仅仅只写一步了,要争对整个squence做每一时步(timestep)的传播,这就要参考计算图了,否则就容易写错,特别是反向传播(下面的LSTM更是如此),计算图如图所示:
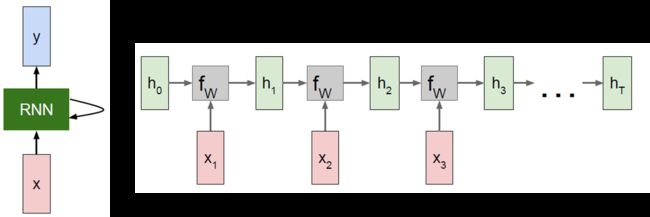
这里的输入 x x x的shape是(N, T, D),这里的N就是minibatch,T就是一个序列squence的时步,其实也就是一个squence里面词语的个数(因为对于image captioning就是一个词语作为一个输入,所以一个词语就对应一个时步,刚开始我还不理解),D表示一个词语用一个D维特征向量来描述。反向传播的时候特别注意上游梯度不仅包括 d h dh dh还有 h t h_{t} ht到 h t − 1 h_{t-1} ht−1的梯度,看code:
def rnn_forward(x, h0, Wx, Wh, b):
"""
Run a vanilla RNN forward on an entire sequence of data. We assume an input
sequence composed of T vectors, each of dimension D. The RNN uses a hidden
size of H, and we work over a minibatch containing N sequences. After running
the RNN forward, we return the hidden states for all timesteps.
Inputs:
- x: Input data for the entire timeseries, of shape (N, T, D).
- h0: Initial hidden state, of shape (N, H)
- Wx: Weight matrix for input-to-hidden connections, of shape (D, H)
- Wh: Weight matrix for hidden-to-hidden connections, of shape (H, H)
- b: Biases of shape (H,)
Returns a tuple of:
- h: Hidden states for the entire timeseries, of shape (N, T, H).
- cache: Values needed in the backward pass
"""
h, cache = None, None
##############################################################################
# TODO: Implement forward pass for a vanilla RNN running on a sequence of #
# input data. You should use the rnn_step_forward function that you defined #
# above. You can use a for loop to help compute the forward pass. #
##############################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
N, T, D = x.shape
N, H = h0.shape
h = np.zeros((N, T, H))
cache = []
for time_step in range(x.shape[1]):
h[:,time_step,:], cache_step = rnn_step_forward(x[:,time_step,:], h0, Wx, Wh, b)
h0 = h[:,time_step,:]
cache.append(cache_step)
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
##############################################################################
# END OF YOUR CODE #
##############################################################################
return h, cache
def rnn_backward(dh, cache):
"""
Compute the backward pass for a vanilla RNN over an entire sequence of data.
Inputs:
- dh: Upstream gradients of all hidden states, of shape (N, T, H).
NOTE: 'dh' contains the upstream gradients produced by the
individual loss functions at each timestep, *not* the gradients
being passed between timesteps (which you'll have to compute yourself
by calling rnn_step_backward in a loop).
# 所以后来调用rnn_step_backward()的时候需要两方面的梯度
# 说实话其实就是对dh的来源没有弄明白
Returns a tuple of:
- dx: Gradient of inputs, of shape (N, T, D)
- dh0: Gradient of initial hidden state, of shape (N, H)
- dWx: Gradient of input-to-hidden weights, of shape (D, H)
- dWh: Gradient of hidden-to-hidden weights, of shape (H, H)
- db: Gradient of biases, of shape (H,)
"""
dx, dh0, dWx, dWh, db = None, None, None, None, None
##############################################################################
# TODO: Implement the backward pass for a vanilla RNN running an entire #
# sequence of data. You should use the rnn_step_backward function that you #
# defined above. You can use a for loop to help compute the backward pass. #
##############################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
# x, prev_h, Wx, Wh, b, next_h = cache
N, T, H = dh.shape
D = cache[0][0].shape[1]
dx = np.zeros((N, T, D))
# dh0 = np.zeros((N, H))
dWx = np.zeros((D, H))
dWh = np.zeros((H, H))
db = np.zeros((H))
dprev_h = np.zeros((N, H))
for time_step in range(T-1,-1,-1):
dx[:,time_step,:], dprev_h, dWx1, dWh1, db1 = rnn_step_backward(dh[:,time_step,:]+dprev_h, cache[time_step])
dWx += dWx1
dWh += dWh1
db += db1
dh0 = dprev_h
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
##############################################################################
# END OF YOUR CODE #
##############################################################################
return dx, dh0, dWx, dWh, db
Word embedding: forward/backward
就像我们使用one-hot编码量化图片的标签一样,词嵌入就是实数元素的特征向量来描述词汇,这样能够显示出词语之间的相关性,如果用one-hot编码,每个词之间都是正交的,不能看出词语语义之间的相似性。而词嵌入就是先把word转化为整数的idx,再把idx转化为D维的特征向量,这里的代码都和短和magic,不建议花很多时间去学习编这样的代码(我写的时候也是根据hint凑出来的):
def word_embedding_forward(x, W):
"""
Forward pass for word embeddings. We operate on minibatches of size N where
each sequence has length T. We assume a vocabulary of V words, assigning each
word to a vector of dimension D.
Inputs:
- x: Integer array of shape (N, T) giving indices of words. Each element idx
of x muxt be in the range 0 <= idx < V.
- W: Weight matrix of shape (V, D) giving word vectors for all words.
Returns a tuple of:
- out: Array of shape (N, T, D) giving word vectors for all input words.
- cache: Values needed for the backward pass
"""
out, cache = None, None
##############################################################################
# TODO: Implement the forward pass for word embeddings. #
# #
# HINT: This can be done in one line using NumPy's array indexing. #
##############################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
out = W[x]
cache = (x, W)
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
##############################################################################
# END OF YOUR CODE #
##############################################################################
return out, cache
def word_embedding_backward(dout, cache):
"""
Backward pass for word embeddings. We cannot back-propagate into the words
since they are integers, so we only return gradient for the word embedding
matrix.
HINT: Look up the function np.add.at
Inputs:
- dout: Upstream gradients of shape (N, T, D)
- cache: Values from the forward pass
Returns:
- dW: Gradient of word embedding matrix, of shape (V, D).
"""
dW = None
##############################################################################
# TODO: Implement the backward pass for word embeddings. #
# #
# Note that words can appear more than once in a sequence. #
# HINT: Look up the function np.add.at #
##############################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
x, W = cache
N, T = x.shape
V, D = W.shape
dW = np.zeros((V, D))
# np.add.at(a, indices, b)
# dW x dout
# np.add.at([V,D],[N,T],[N,T,D]) actually dout.shape[0]=len[x]
# which is equal to this command:
# for index, indice in enumerate(x):
# a[indice] += b[index]
np.add.at(dW, x, dout)
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
##############################################################################
# END OF YOUR CODE #
##############################################################################
return dW
RNN for image captioning
Temporal Affine layer和Temporal Softmax loss中相应的函数已经为我们编好了,但需要自己看一遍理解一下。
这一部分就是根据上面编好的函数,包括layers.py里面的部分函数,来进行image captioning:
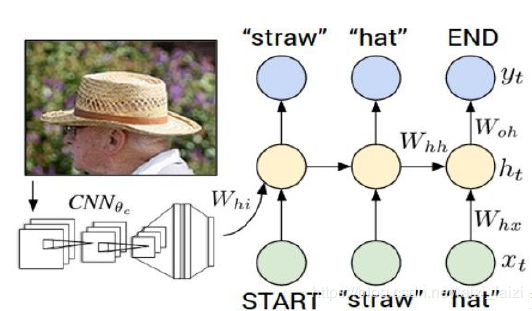
其实我感觉这个过程和教程中介绍的character-level language model非常像,只不过
- 这里把单个字符换成了单个词语,也就是word-level,参数空间变大了
- 这里的初始隐藏状态向量 h 0 h0 h0由图片经卷积后的特征向量来提供
根据提示写code
def loss(self, features, captions):
"""
Compute training-time loss for the RNN. We input image features and
ground-truth captions for those images, and use an RNN (or LSTM) to compute
loss and gradients on all parameters.
Inputs:
- features: Input image features, of shape (N, D)
- captions: Ground-truth captions; an integer array of shape (N, T) where
each element is in the range 0 <= y[i, t] < V
Returns a tuple of:
- loss: Scalar loss
- grads: Dictionary of gradients parallel to self.params
"""
# Cut captions into two pieces: captions_in has everything but the last word
# and will be input to the RNN; captions_out has everything but the first
# word and this is what we will expect the RNN to generate. These are offset
# by one relative to each other because the RNN should produce word (t+1)
# after receiving word t. The first element of captions_in will be the START
# token, and the first element of captions_out will be the first word.
captions_in = captions[:, :-1]
captions_out = captions[:, 1:]
# You'll need this
mask = (captions_out != self._null)
# Weight and bias for the affine transform from image features to initial
# hidden state
W_proj, b_proj = self.params['W_proj'], self.params['b_proj']
# Word embedding matrix
W_embed = self.params['W_embed']
# Input-to-hidden, hidden-to-hidden, and biases for the RNN
Wx, Wh, b = self.params['Wx'], self.params['Wh'], self.params['b']
# Weight and bias for the hidden-to-vocab transformation.
W_vocab, b_vocab = self.params['W_vocab'], self.params['b_vocab']
loss, grads = 0.0, {}
############################################################################
# TODO: Implement the forward and backward passes for the CaptioningRNN. #
# In the forward pass you will need to do the following: #
# (1) Use an affine transformation to compute the initial hidden state #
# from the image features. This should produce an array of shape (N, H)#
# (2) Use a word embedding layer to transform the words in captions_in #
# from indices to vectors, giving an array of shape (N, T, W). #
# (3) Use either a vanilla RNN or LSTM (depending on self.cell_type) to #
# process the sequence of input word vectors and produce hidden state #
# vectors for all timesteps, producing an array of shape (N, T, H). #
# (4) Use a (temporal) affine transformation to compute scores over the #
# vocabulary at every timestep using the hidden states, giving an #
# array of shape (N, T, V). #
# (5) Use (temporal) softmax to compute loss using captions_out, ignoring #
# the points where the output word is using the mask above. #
# #
# In the backward pass you will need to compute the gradient of the loss #
# with respect to all model parameters. Use the loss and grads variables #
# defined above to store loss and gradients; grads[k] should give the #
# gradients for self.params[k]. #
# #
# Note also that you are allowed to make use of functions from layers.py #
# in your implementation, if needed. #
############################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
#forward
# (1) image features to initial hidden state
init_hs, ih_cache = affine_forward(features, W_proj, b_proj) # (N, H)
# (2) word embedding indices to vectors
wordvec, w_cache = word_embedding_forward(captions_in, W_embed) # (N, T-1, W)
# (3) use RNN or LSTM input word vector to hidden state
if self.cell_type == 'rnn':
hidden_state, rnn_cache = rnn_forward(wordvec, init_hs, Wx, Wh, b) # (N, T-1, H)
elif self.cell_type == 'lstm':
hidden_state, lstm_cache = lstm_forward(wordvec, init_hs, Wx, Wh, b) # (N, T-1, H)
else:
raise ValueError('Invalid cell_type "%s"' % self.cell_type)
# (4) temporal affine hidden state to scores
scores, s_cache= temporal_affine_forward(hidden_state, W_vocab, b_vocab) # (N, T-1, V)
# (5) temporal softmax loss use captions_out and mask above
loss, dscores= temporal_softmax_loss(scores, captions_out, mask) # (N, T-1, V)
#backward
dhidden_state, grads['W_vocab'], grads['b_vocab'] = temporal_affine_backward(dscores, s_cache)
if self.cell_type == 'rnn':
dwordvec, dinit_hs, grads['Wx'], grads['Wh'], grads['b'] = rnn_backward(dhidden_state, rnn_cache)
elif self.cell_type == 'lstm':
dwordvec, dinit_hs, grads['Wx'], grads['Wh'], grads['b'] = lstm_backward(dhidden_state, lstm_cache)
else:
raise ValueError('Invalid cell_type "%s"' % self.cell_type)
grads['W_embed'] = word_embedding_backward(dwordvec, w_cache)
dfeatures, grads['W_proj'], grads['b_proj'] = affine_backward(dinit_hs, ih_cache)
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
############################################################################
# END OF YOUR CODE #
############################################################################
return loss, grads
Test-time sampling
因为image captioning训练和测试阶段不一样,因为训练时有 label,每时刻的输入都是 ground-truth 的单词,其实这里用的是单词的索引caption;而预测只能把自己上时刻的输出(就是预测概率最大的那个单词)当做输入,在sample函数中要做的就是在RNN测试的前向传播的时候,把每步最大概率单词的索引放到caption变量中:
def sample(self, features, max_length=30):
"""
Run a test-time forward pass for the model, sampling captions for input
feature vectors.
At each timestep, we embed the current word, pass it and the previous hidden
state to the RNN to get the next hidden state, use the hidden state to get
scores for all vocab words, and choose the word with the highest score as
the next word. The initial hidden state is computed by applying an affine
transform to the input image features, and the initial word is the
token.
For LSTMs you will also have to keep track of the cell state; in that case
the initial cell state should be zero.
Inputs:
- features: Array of input image features of shape (N, D).
- max_length: Maximum length T of generated captions.
Returns:
- captions: Array of shape (N, max_length) giving sampled captions,
where each element is an integer in the range [0, V). The first element
of captions should be the first sampled word, not the token.
"""
N = features.shape[0]
captions = self._null * np.ones((N, max_length), dtype=np.int32)
# Unpack parameters
W_proj, b_proj = self.params['W_proj'], self.params['b_proj']
W_embed = self.params['W_embed']
Wx, Wh, b = self.params['Wx'], self.params['Wh'], self.params['b']
W_vocab, b_vocab = self.params['W_vocab'], self.params['b_vocab']
###########################################################################
# TODO: Implement test-time sampling for the model. You will need to #
# initialize the hidden state of the RNN by applying the learned affine #
# transform to the input image features. The first word that you feed to #
# the RNN should be the token; its value is stored in the #
# variable self._start. At each timestep you will need to do to: #
# (1) Embed the previous word using the learned word embeddings #
# (2) Make an RNN step using the previous hidden state and the embedded #
# current word to get the next hidden state. #
# (3) Apply the learned affine transformation to the next hidden state to #
# get scores for all words in the vocabulary #
# (4) Select the word with the highest score as the next word, writing it #
# (the word index) to the appropriate slot in the captions variable #
# #
# For simplicity, you do not need to stop generating after an token #
# is sampled, but you can if you want to. #
# #
# HINT: You will not be able to use the rnn_forward or lstm_forward #
# functions; you'll need to call rnn_step_forward or lstm_step_forward in #
# a loop. #
# #
# NOTE: we are still working over minibatches in this function. Also if #
# you are using an LSTM, initialize the first cell state to zeros. #
###########################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
# print(self._start) # a int number:1
# print(self._null) # a int number:0
# image features to initial hidden state
init_hs, _ = affine_forward(features, W_proj, b_proj) # (N, H)
x = np.array([self._start for i in range(N)])
prev_h = init_hs
prev_c = np.zeros_like(prev_h)
for t in range(max_length):
captions[:, t] = x
x_embedded, _ = word_embedding_forward(x, W_embed) # (N, W)
if self.cell_type == 'rnn':
next_h, _ = rnn_step_forward(x_embedded, prev_h, Wx, Wh, b) # (N, H)
prev_h = next_h
elif self.cell_type == 'lstm':
next_h, next_c, _ = lstm_step_forward(x_embedded, prev_h, prev_c, Wx, Wh, b)
prev_h = next_h
prev_c = next_c
scores, _ = affine_forward(next_h, W_vocab, b_vocab)
x = scores.argmax(axis=1)
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
############################################################################
# END OF YOUR CODE #
############################################################################
return captions
LSTM(Long Short Term Memory)
LSTM比Vanilla RNN更加优秀的地方:
- RNN会有训练的时候不稳定的情况,主要是由于反向传播中参数矩阵 W W W会累乘,如果他的梯度大于1或小于1分别会造成梯度爆炸和梯度消失的情况
- LSTM比RNN多引入了很多门,而且有cell state,可以帮助长时间记忆。如人在记忆的时候,RNN就是光用脑袋记,而LSTM就多了一支笔来帮助你记忆,你记忆的内容肯定会更加长,现在用循环神经网络一般都用LSTM了。
这是我的LSTM_Captioning.ipynb
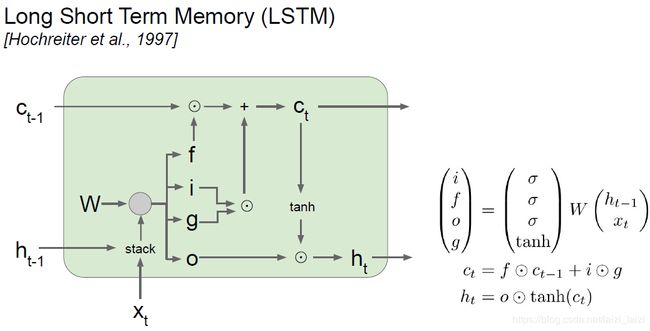
LSTM: step forward/backward
前向传播看着结构示意图就可以很容易写出来,主要要分出i,f,o,g四个门。反向传播的时候不要忘记 C t − 1 C_{t-1} Ct−1上面那条路的上游梯度不仅有来自于 d n e x t c dnext_c dnextc的,还有下面的 d h t dh_{t} dht也会有,我在写的时候就是没找出来,所以看着计算图写反向传播是非常配对的一个操作。
def lstm_step_forward(x, prev_h, prev_c, Wx, Wh, b):
"""
Forward pass for a single timestep of an LSTM.
The input data has dimension D, the hidden state has dimension H, and we use
a minibatch size of N.
Note that a sigmoid() function has already been provided for you in this file.
Inputs:
- x: Input data, of shape (N, D)
- prev_h: Previous hidden state, of shape (N, H)
- prev_c: previous cell state, of shape (N, H)
- Wx: Input-to-hidden weights, of shape (D, 4H)
- Wh: Hidden-to-hidden weights, of shape (H, 4H)
- b: Biases, of shape (4H,)
Returns a tuple of:
- next_h: Next hidden state, of shape (N, H)
- next_c: Next cell state, of shape (N, H)
- cache: Tuple of values needed for backward pass.
"""
next_h, next_c, cache = None, None, None
#############################################################################
# TODO: Implement the forward pass for a single timestep of an LSTM. #
# You may want to use the numerically stable sigmoid implementation above. #
#############################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
A = x.dot(Wx) + prev_h.dot(Wh) + b # (N, 4H)
H = prev_h.shape[1]
i = sigmoid(A[:,0:H]) # (N, H)
f = sigmoid(A[:,H:2*H]) # (N, H)
o = sigmoid(A[:,2*H:3*H]) # (N, H)
g = np.tanh(A[:,3*H:4*H]) # (N, H)
next_c = f * prev_c + i * g
next_h = o * np.tanh(next_c)
cache = (x, prev_h, prev_c, Wx, Wh, i, f, o, g, next_c)
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
##############################################################################
# END OF YOUR CODE #
##############################################################################
return next_h, next_c, cache
def lstm_step_backward(dnext_h, dnext_c, cache):
"""
Backward pass for a single timestep of an LSTM.
Inputs:
- dnext_h: Gradients of next hidden state, of shape (N, H)
- dnext_c: Gradients of next cell state, of shape (N, H)
- cache: Values from the forward pass
Returns a tuple of:
- dx: Gradient of input data, of shape (N, D)
- dprev_h: Gradient of previous hidden state, of shape (N, H)
- dprev_c: Gradient of previous cell state, of shape (N, H)
- dWx: Gradient of input-to-hidden weights, of shape (D, 4H)
- dWh: Gradient of hidden-to-hidden weights, of shape (H, 4H)
- db: Gradient of biases, of shape (4H,)
"""
dx, dprev_h, dprev_c, dWx, dWh, db = None, None, None, None, None, None
#############################################################################
# TODO: Implement the backward pass for a single timestep of an LSTM. #
# #
# HINT: For sigmoid and tanh you can compute local derivatives in terms of #
# the output value from the nonlinearity. #
#############################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
x, prev_h, prev_c, Wx, Wh, i, f, o, g, next_c = cache
dnext_c_hat = dnext_c + o * dnext_h * (1 - np.tanh(next_c)**2) # don't forget
# from computational graph to calculate gradient will clear
dprev_c = f * dnext_c_hat
df = f * (1-f) * prev_c * dnext_c_hat
di = i * (1-i) * g * dnext_c_hat
dg = (1-g**2) * i * dnext_c_hat
do = o * (1-o) * np.tanh(next_c) * dnext_h
dA = np.concatenate((np.concatenate((di, df), axis=1), np.concatenate((do, dg), axis=1)), axis=1)
dx = dA.dot(Wx.T)
dWx = x.T.dot(dA)
dWh = prev_h.T.dot(dA)
dprev_h = dA.dot(Wh.T)
db = np.sum(dA, axis=0)
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
##############################################################################
# END OF YOUR CODE #
##############################################################################
return dx, dprev_h, dprev_c, dWx, dWh, db
LSTM: forward/backward
这个和RNN的forward/backward的思想是类似的,这不过这里多了个cell state,其初始值和初始上游梯度都为0就可以了,又因为他是一个中间值,不会引出去求loss,所以他没有每一时步上的由loss来的上游梯度,只有从上一个cell state传到下一个cell state的梯度。
def lstm_forward(x, h0, Wx, Wh, b):
"""
Forward pass for an LSTM over an entire sequence of data. We assume an input
sequence composed of T vectors, each of dimension D. The LSTM uses a hidden
size of H, and we work over a minibatch containing N sequences. After running
the LSTM forward, we return the hidden states for all timesteps.
Note that the initial cell state is passed as input, but the initial cell
state is set to zero. Also note that the cell state is not returned; it is
an internal variable to the LSTM and is not accessed from outside.
Inputs:
- x: Input data of shape (N, T, D)
- h0: Initial hidden state of shape (N, H)
- Wx: Weights for input-to-hidden connections, of shape (D, 4H)
- Wh: Weights for hidden-to-hidden connections, of shape (H, 4H)
- b: Biases of shape (4H,)
Returns a tuple of:
- h: Hidden states for all timesteps of all sequences, of shape (N, T, H)
- cache: Values needed for the backward pass.
"""
h, cache = None, None
#############################################################################
# TODO: Implement the forward pass for an LSTM over an entire timeseries. #
# You should use the lstm_step_forward function that you just defined. #
#############################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
N, T, D = x.shape
H = h0.shape[1]
h = np.zeros((N, T, H))
cache = []
prev_h = h0
prev_c = np.zeros((N, H))
for t in range(T):
h[:,t,:], next_c, cache_step = lstm_step_forward(x[:,t,:], prev_h, prev_c, Wx, Wh, b)
cache.append(cache_step)
prev_h = h[:,t,:]
prev_c = next_c
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
##############################################################################
# END OF YOUR CODE #
##############################################################################
return h, cache
def lstm_backward(dh, cache):
"""
Backward pass for an LSTM over an entire sequence of data.
Inputs:
- dh: Upstream gradients of hidden states, of shape (N, T, H)
- cache: Values from the forward pass
Returns a tuple of:
- dx: Gradient of input data of shape (N, T, D)
- dh0: Gradient of initial hidden state of shape (N, H)
- dWx: Gradient of input-to-hidden weight matrix of shape (D, 4H)
- dWh: Gradient of hidden-to-hidden weight matrix of shape (H, 4H)
- db: Gradient of biases, of shape (4H,)
"""
dx, dh0, dWx, dWh, db = None, None, None, None, None
#############################################################################
# TODO: Implement the backward pass for an LSTM over an entire timeseries. #
# You should use the lstm_step_backward function that you just defined. #
#############################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
N, T, H = dh.shape
D = cache[0][0].shape[1]
dx = np.zeros((N, T, D))
dWx = np.zeros((D, 4*H))
dWh = np.zeros((H, 4*H))
db = np.zeros((4*H))
dprev_h = np.zeros((N, H))
dprev_c = np.zeros((N, H))
for t in range(T-1,-1,-1):
dx[:,t,:], dprev_h, dprev_c, dWx1, dWh1, db1 = lstm_step_backward(dh[:,t,:]+dprev_h, dprev_c, cache[t])
dWx += dWx1
dWh += dWh1
db += db1
dh0 = dprev_h
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
##############################################################################
# END OF YOUR CODE #
##############################################################################
return dx, dh0, dWx, dWh, db
LSTM captioning model/test-time sampling
这个在上面RNN的代码里面已经提到了,看上面的代码就行了
结果
这里面的图有点多,主要是有train和val的image captioning的结果图,因为我们取了small data训练肯定过拟合,所以在val阶段的图片描述就不会很准确,具体见:
- RNN_Captioning.ipynb
- LSTM_Captioning.ipynb
链接
前后面的作业博文请见:
- 上一篇博文:PyTorch学习
- 下一篇博文:NetworkVisualization-PyTorch