用caffe训练好的lenet_iter_10000.caffemodel测试单张mnist图片
接上个博客:http://blog.csdn.net/lanxuecc/article/details/52474476,前面已经生成了deploy.proto.txt。下面具体记录用lenet_iter_10000.caffemodel测试图片。
准备一张手写数字图片
![]()
注意在depoy.prototxt文件中指定正确的该图片的通道数。
准备一个均值文件
因为classify.py中的测试接口caffe.Classifier需要训练图片的均值文件作为输入参数,而实际lenet-5训练时并未计算均值文件,所以这里创建一个全0的均值文件输入。编写一个zeronp.py文件如下

执行
python zeronp.py生成均值文件 meanfile.npy。
这里注意宽高要与输入测试的图片宽高一致。这里参考:https://github.com/BVLC/caffe/issues/320
修改classify.py保存为classifymnist.py文件
#!/usr/bin/env python
"""
classify.py is an out-of-the-box image classifer callable from the command line.
By default it configures and runs the Caffe reference ImageNet model.
"""
import numpy as np
import os
import sys
import argparse
import glob
import time
import pandas as pd #插入数据分析包
import caffe
def main(argv):
pycaffe_dir = os.path.dirname(__file__)
parser = argparse.ArgumentParser()
# Required arguments: input and output files.
parser.add_argument(
"input_file",
help="Input image, directory, or npy."
)
parser.add_argument(
"output_file",
help="Output npy filename."
)
# Optional arguments.
parser.add_argument(
"--model_def",
default=os.path.join(pycaffe_dir,
"../examples/mnist/deploy.prototxt"), #指定lenet-5的deploy.prototxt模型位置
help="Model definition file."
)
parser.add_argument(
"--pretrained_model",
default=os.path.join(pycaffe_dir,
"../examples/mnist/lenet_iter_10000.caffemodel"), #指定lenet-5的caffemodel模型位置
help="Trained model weights file."
)
#######新增^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
parser.add_argument(
"--labels_file",
default=os.path.join(pycaffe_dir,
"../examples/mnist/synset_words.txt"), #指定输出结果对应的类别名文件
help="mnist result words file"
)
parser.add_argument(
"--force_grayscale",
action='store_true', #增加一个变量将输入图像强制转化为灰度图,因为lenet-5训练用的就是灰度图
help="Converts RGB images down to single-channel grayscale versions," +
"useful for single-channel networks like MNIST."
)
parser.add_argument(
"--print_results",
action='store_true', #输入参数要求打印输出结果
help="Write output text to stdout rather than serializing to a file."
)
#######新增vvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvv
parser.add_argument(
"--gpu",
action='store_true',
help="Switch for gpu computation."
)
parser.add_argument(
"--center_only",
action='store_true',
help="Switch for prediction from center crop alone instead of " +
"averaging predictions across crops (default)."
)
parser.add_argument(
"--images_dim",
default='28,28', #指定图像高与宽
help="Canonical 'height,width' dimensions of input images."
)
parser.add_argument(
"--mean_file",
default=os.path.join(pycaffe_dir,
'../examples/mnist/meanfile.npy'), #指定均值文件
help="Data set image mean of [Channels x Height x Width] dimensions " +
"(numpy array). Set to '' for no mean subtraction."
)
parser.add_argument(
"--input_scale",
type=float,
help="Multiply input features by this scale to finish preprocessing."
)
parser.add_argument(
"--raw_scale",
type=float,
default=255.0,
help="Multiply raw input by this scale before preprocessing."
)
parser.add_argument(
"--channel_swap",
default='2,1,0',
help="Order to permute input channels. The default converts " +
"RGB -> BGR since BGR is the Caffe default by way of OpenCV."
)
parser.add_argument(
"--ext",
default='jpg',
help="Image file extension to take as input when a directory " +
"is given as the input file."
)
args = parser.parse_args()
image_dims = [int(s) for s in args.images_dim.split(',')]
mean, channel_swap = None, None
if not args.force_grayscale:
if args.mean_file:
mean = np.load(args.mean_file).mean(1).mean(1)
if args.channel_swap:
channel_swap = [int(s) for s in args.channel_swap.split(',')]
if args.gpu:
caffe.set_mode_gpu()
print("GPU mode")
else:
caffe.set_mode_cpu()
print("CPU mode")
# Make classifier.
classifier = caffe.Classifier(args.model_def, args.pretrained_model,
image_dims=image_dims, mean=mean,
input_scale=args.input_scale, raw_scale=args.raw_scale,
channel_swap=channel_swap)
# Load numpy array (.npy), directory glob (*.jpg), or image file.
args.input_file = os.path.expanduser(args.input_file)
if args.input_file.endswith('npy'):
print("Loading file: %s" % args.input_file)
inputs = np.load(args.input_file)
elif os.path.isdir(args.input_file):
print("Loading folder: %s" % args.input_file)
inputs =[caffe.io.load_image(im_f)
for im_f in glob.glob(args.input_file + '/*.' + args.ext)]
else:
print("Loading image file: %s" % args.input_file)
inputs = [caffe.io.load_image(args.input_file, not args.force_grayscale)] #强制图片为灰度图
print("Classifying %d inputs." % len(inputs))
# Classify.
start = time.time()
scores = classifier.predict(inputs, not args.center_only).flatten()
print("Done in %.2f s." % (time.time() - start))
#增加输出结果打印到终端^^^^^^^^
# print
if args.print_results:
with open(args.labels_file) as f:
labels_df = pd.DataFrame([{'synset_id':l.strip().split(' ')[0], 'name': ' '.join(l.strip().split(' ')[1:]).split(',')[0]} for l in f.readlines()])
labels = labels_df.sort('synset_id')['name'].values
indices =(-scores).argsort()[:5]
predictions = labels[indices]
print predictions
print scores
meta = [(p, '%.5f' % scores[i]) for i,p in zip(indices, predictions)]
print meta
#增加输出结果打印到终端vvvvvvvvvvv
# Save
print("Saving results into %s" % args.output_file)
np.save(args.output_file, predictions)
if __name__ == '__main__':
main(sys.argv)修改完成后执行如下命令:
python classifymnist.py --print_results --force_grayscale --center_only --labels_file ../examples/mnist/synset_words.txt ../examples/mnist/4.jpg resultsfile得到结果如下::
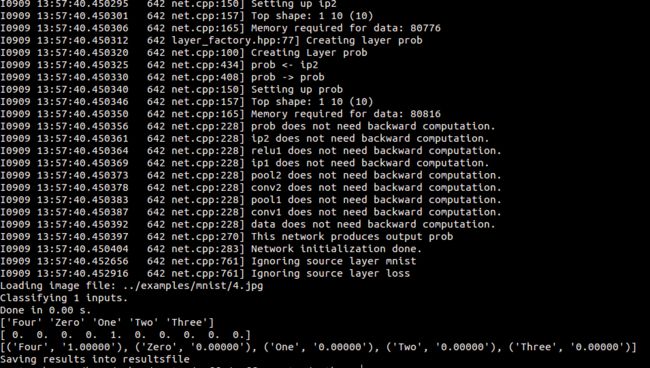
参考::::
http://www.cnblogs.com/denny402/p/5111018.html
https://github.com/BVLC/caffe/pull/2359/commits/dd3a5f9268ca3bdf19a17760bd6f568e21c1b521
http://blog.csdn.net/gzljss/article/details/45849013
http://blog.csdn.net/cqcyst/article/details/47364429
http://caffe.berkeleyvision.org/gathered/examples/feature_extraction.html