adaboost训练 之 弱分类器训练原理
二叉决策树介绍
二叉决策树由LeoBreiman和他的同事提出.他们称之为”分类和回归树(CART)”.OpenCV实现的就是”分类回归树”.简单地说,二叉决策树的每个结点表示对对象做判断的一个特征属性,将对象提供的属性值与该结点提供的属性值做对比,例如,判断一辆车是否是小汽车我们选择第一个结点为车子的轮子个数这个属性,如果有4个轮子表示有可能是的小汽车,如果没有则不可能是。这个结点的左右分支分别代表对比后的两种输出,左分支表示有可能是小汽车,右分支不可能。由于要判断是否是小汽车光通过有4相轮子,当然无法确定是小汽车,所以紧接着左分支有第二个结点通过是否有发动机来判断,是否是小汽车,如此下去直到所有的结点组合起来能判断是小汽车为止,也就是到达了叶子结点。所有二叉决策树的叶子结点存放得都是类别结果,在这个例子里就是“是小汽车”和“不是小汽车”。
在adaboost弱分类器中,弱分类器的二叉树结构大致如下,我们假设用三个haar特征:F1,F2,F3来判断输入图像是否人脸,其决策树的结构大致如下:
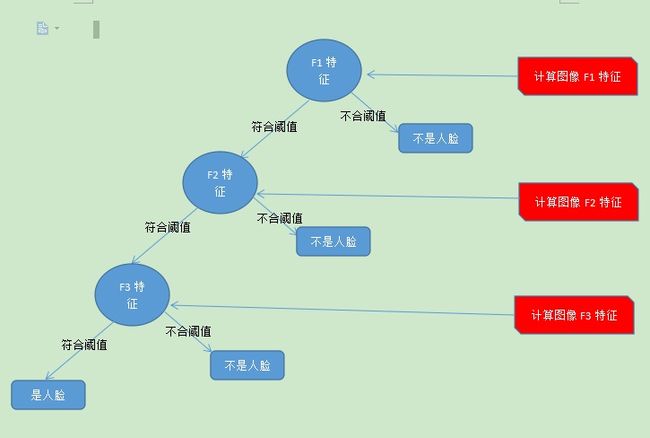
可以看出,在分类的时,每个非叶子节点都表示一次基于属性的判断,每个路径代表对属性判断的输出,每个叶子节点代表一种类别:是人脸或不是人脸,并作为最终判断的结果。
一个人脸弱分类器就是一个基本和上图类似的决策树,
用训练好的阈值来比较输入图片的特征值与当前特征值差距,当输入图片的特征值大于该阈值时才判定其为人脸,否则判为非人脸。最基本的弱分类器只包含一个Haar-like特征,也就是它的决策树只有一层,被称为树桩(stump)。
训练成的弱分类器的介绍
下面这个是我训练的分类器中的一个弱分类器,他的结构如下:::
1 /*这个弱分类器有1个特征,也就是有1个非叶子结点*/
2 /*需要2个rect来计算特征*/
4 1 12 9 0 -1 /*第一个rect对应Haar特征中白矩形框,左上角左标x==4与y==1,宽==12,高==9,0是无意义值,矩形框权重=-1*/
8 1 4 9 0 3 /*第二个rect对应Haar特征中黑矩形框,左上角左标x==8与y==1,宽==4,高==9,0是无意义值,矩形框权重=3*/
haar_x3 /*该特征名称*/
5.458947e-002 0 -1 /*该特征的阈值,左叶子结点序号,右叶子结点序号*/
-8.695291e-001 7.872277e-001 /*该特征的两个叶子结点的输出置信度,所谓输出置信度就是通过这个特征判断是否人脸的可能性*/弱分类器结构体介绍
定义弱分类器的结构体::::::::
typedef struct CvCARTClassifier{
CV_CLASSIFIER_FIELDS()
/* number of internal nodes */
int count; //count就是main主函数中的参数nsplits用于定义的是非叶子节点数,或者叫做中间节点数,也就是该分类器特征个数
/* internal nodes (each array of elements) */
int* compidx; //节点所采用的最优Haar特征序号
float* threshold; //节点所采用的最优Haar特征阈值
int* left; //非叶子节点的左子节点序号(叶子节点为负数,非叶子节点为正数)
int* right; //非叶子节点的右子节点序号(叶子节点为负数,非叶子节点为正数)
/* leaves (array of +1 elements) */
float* val;// 叶子节点输出置信度
} CvCARTClassifier;在训练中定义弱分类器结点的结构体:::::
typedef struct CvStumpClassifier
{
CV_CLASSIFIER_FIELDS()
int compidx; /*找到的最优特征序号*/
float lerror; /* impurity of the right node *//*分类负样本误差*/
float rerror; /* impurity of the left node *//*分类正样本误差*/
float threshold; /*当前特征阈值*/
float left; /*分类为负样本的置信度*/
float right; /*分类为正样本的置信度*/
} CvStumpClassifier;adaboost训练弱分类器的原理
其实,一个弱分类器就是上述多个特征以CART的形式组成在一起,而训练一个最优弱分类器过程就是寻找能使弱分类器对所有样本判读误差最小的几个特征的各自合适阈值的过程。说起来有点拗口,分开来说就是针对样本的所有特征中的每个特征寻找一个合适的阈值来分类正负样本,使对于所有正负样本分类得最准确,也就是判读(分类)误差最小。再在这所有特征中找到分类最准的那几个特征,例如上述的F1,F2,F3,每个特征和他们的阈值就是上述的一个结点,几个结点以CART的形式组织在一起就是弱分类器。
首先分析下adaboost训练单个弱分类器结点的函数逻辑,也就是训练弱分类器桩的函数,见opencv中函数cvCreateMTStumpClassifier。
1、在进入cvCreateMTStumpClassifier函数前,对于每个特征 f,计算所有训练样本的特征值,并将其排序。
2、遍历排序好的特征,针对每个特征,再遍历所有实际样本这个特征的值。以当前样本的特征值为阈值,计算用这个阈值将所有样本分为人脸与非人脸后的误差。
3、计算误差的方式:
opencv中计算误差方式有四种”misclassification error”,”gini error”,”entropy error”,”least sum of squares error”,这里以第一种来说明:
代码:::
/* misclassification error
* err = MIN( wpos, wneg );
*/
#define ICV_DEF_FIND_STUMP_THRESHOLD_MISC( suffix, type ) \
ICV_DEF_FIND_STUMP_THRESHOLD( misc_##suffix, type, \
wposl = 0.5F * ( wl + wyl ); \
wposr = 0.5F * ( wr + wyr ); \
curleft = 0.5F * ( 1.0F + curleft ); \
curright = 0.5F * ( 1.0F + curright ); \
curlerror = MIN( wposl, wl - wposl ); \
currerror = MIN( wposr, wr - wposr ); \
)接上述第二点,当遍历到第i个样本时,设其当前特征的阈值为P,则所有样本中当前特征值大于P的为正样本,小于等于P的为负样本。我们设小于等于P的也就是被分成负样本中的正样本权重和为wposl,则其中负样本权重和为wl - wposl。我们设大于P的也就是被分成正样本中的正样本和为wposr,则其中负样本权重和为wr - wposr。
设当前分成负样本的分类误差为curlerror 。设当前分成正样本的分类误差为currerror。
最终的分类误差为:
e = curlerror + currerror = min(wposl, wl - wposl) + min(wposr, wr - wposr)。
这样就解释了上述计算误差代码。
4、找到使上述e最小的阈值,训练了弱分类器的一个结点。
找到有合理阈值使e最小的几个结点,然后在cvCreateCARTClassifier函数中就组成了弱分类器,这样弱分类器就训练成功了!!!!!
感谢::::::
http://blog.csdn.net/lsxpu/article/details/7976609?spm=5176.100239.blogcont9312.32.irEvjR
http://www.cnblogs.com/YCwavelet/p/3545525.html?spm=5176.100239.blogcont9312.33.irEvjR
http://blog.csdn.net/naruto0001/article/details/8029193
http://blog.csdn.net/liaojiacai/article/details/50370571
http://blog.sina.com.cn/s/blog_5f853eb10100s9ez.html
http://blog.csdn.net/zouxy09/article/details/7922923