用caffe训练测试自己的图片
所有的操作是基于caffe的根目录/caffe-master/来操作的:
数据准备
我所用的图片是车牌识别中,0~9数字图片,在data下面新建一个number目录,用来存放训练图片(caffenumimg_train)与测试图片(caffenumimg_test),0~9分别有200张左右的训练图片和50张左右的测试图片
转换成lmdb格式文件
首先,在data/number/目录编写一个脚本create_filelist.sh文件,用来生成train.txt和test.txt清单文件。清单文件train.txt与test.txt主要用来记录训练图片与测试图片的目录与标签。
#!/usr/bin/env sh
DATA_TRAIN=data/number/caffenumimg_train
DATA_TEST=data/number/caffenumimg_test
MY=data/number
echo "Create train.txt..."
rm -rf $MY/train.txt
for i in 0 1 2 3 4 5 6 7 8 9
do
find $DATA_TRAIN/$i/ -name *.bmp | cut -d '/' -f1-5 | sed "s/$/ $i/">>$MY/train.txt
done
echo "Create test.txt..."
rm -rf $MY/test.txt
for i in 0 1 2 3 4 5 6 7 8 9
do
find $DATA_TEST/$i/ -name *.bmp | cut -d '/' -f1-5 | sed "s/$/ $i/">>$MY/test.txt
done
echo "All done"这段脚本的大致意思(生成test.txt与生成train.txt大体相同这里只介绍生成train.txt脚本的逻辑):
首先删除已经有的train.txt清单文件,然后遍历data/number/caffenumimg_train目录中的0~9文件夹,
读取所有的.bmp文件的目录,以/划分目录字段,截取1到5这几个字段,在字段结尾处加类别标签,保存到train.txt文件中。
然后,运行脚本
sh /data/number/create_filelist.sh得到如下图所示的结果:
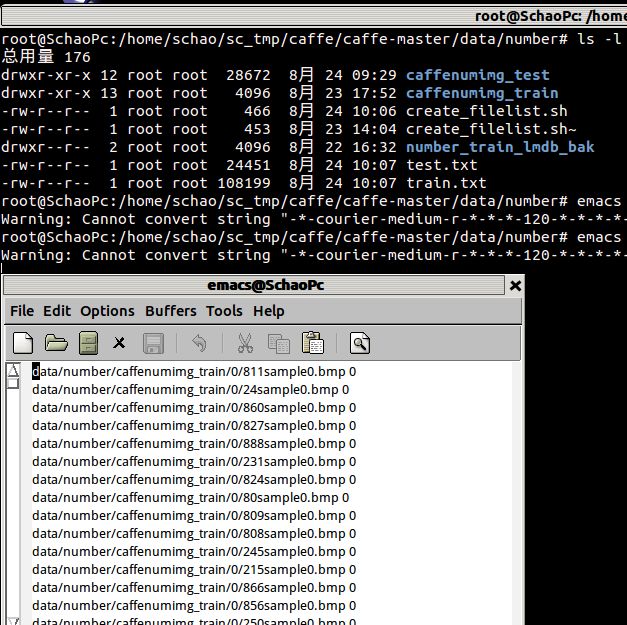
接着再编写一个脚本文件放到目录examples/number/,调用convert_imageset命令来转换lmdb数据格式:
#!/usr/bin/env sh
# Create the imagenet lmdb inputs
# N.B. set the path to the imagenet train + val data dirs
set -e
EXAMPLE=examples/number
DATA=data/number
TOOLS=build/tools
TRAIN_DATA_ROOT=./
TEST_DATA_ROOT=./
rm $EXAMPLE/number_train_lmdb -rf
rm $EXAMPLE/number_test_lmdb -rf
# Set RESIZE=true to resize the images to 256x256. Leave as false if images have
# already been resized using another tool.
RESIZE=true
if $RESIZE; then
RESIZE_HEIGHT=256
RESIZE_WIDTH=256
else
RESIZE_HEIGHT=0
RESIZE_WIDTH=0
fi
if [ ! -d "$TRAIN_DATA_ROOT" ]; then
echo "Error: TRAIN_DATA_ROOT is not a path to a directory: $TRAIN_DATA_ROOT"
echo "Set the TRAIN_DATA_ROOT variable in create_imagenet.sh to the path" \
"where the ImageNet training data is stored."
exit 1
fi
if [ ! -d "$TEST_DATA_ROOT" ]; then
echo "Error: TEST_DATA_ROOT is not a path to a directory: $TEST_DATA_ROOT"
echo "Set the TEST_DATA_ROOT variable in create_imagenet.sh to the path" \
"where the ImageNet validation data is stored."
exit 1
fi
echo "Creating train lmdb..."
GLOG_logtostderr=1 $TOOLS/convert_imageset \
--resize_height=$RESIZE_HEIGHT \
--resize_width=$RESIZE_WIDTH \
--shuffle \
$TRAIN_DATA_ROOT\
$DATA/train.txt \
$EXAMPLE/number_train_lmdb
echo "Creating val lmdb..."
GLOG_logtostderr=1 $TOOLS/convert_imageset \
--resize_height=$RESIZE_HEIGHT \
--resize_width=$RESIZE_WIDTH \
--shuffle \
$TEST_DATA_ROOT\
$DATA/test.txt \
$EXAMPLE/number_test_lmdb
echo "Done."在caffe中,作者为我们提供了这样一个文件:convert_imageset.cpp,存放在根目录下的tools文件夹下。编译之后,生成对应的可执行文件放在 build/tools/ 下面,这个文件的作用就是用于将图片文件转换成caffe框架中能直接使用的db文件。
该文件的使用格式:
convert_imageset [FLAGS] ROOTFOLDER/LISTFILE DB_NAMEFLAGS: 图片参数组,具体有以下几个参数:
-gray: 是否以灰度图的方式打开图片。程序调用opencv库中的imread()函数来打开图片,默认为false
-shuffle: 是否随机打乱图片顺序。默认为false
-backend:需要转换成的db文件格式,可选为leveldb或lmdb,默认为lmdb
-resize_width/resize_height: 改变图片的大小。在运行中,要求所有图片的尺寸一致,因此需要改变图片大小。 程序调用opencv库的resize()函数来对图片放大缩小,默认为0,不改变
-check_size: 检查所有的数据是否有相同的尺寸。默认为false,不检查
-encoded: 是否将原图片编码放入最终的数据中,默认为false
-encode_type: 与前一个参数对应,将图片编码为哪一个格式:‘png’,’jpg’……
ROOTFOLDER/: 图片存放的绝对路径,从linux系统根目录开始 如上述脚本文件的TRAIN_DATA_ROOT
LISTFILE: 图片文件列表清单,一般为一个txt文件,一行一张图片,如上述截图k所示train.txt与test.txt
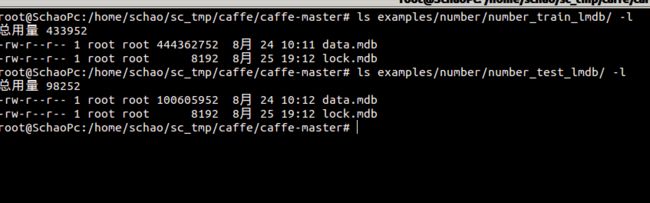
DB_NAME: 最终生成的db文件存放目录,如下截图所示的number_train_lmdb
运行成功后在 examples/number/下面生成两个文件夹number_test_lmdb和number_train_lmdb,分别用于保存训练图片与测试图片转换后的lmdb文件:
计算均值并保存
图片减去均值再训练,会提高训练速度和精度。因此,一般都会有这个操作。
caffe程序提供了一个计算均值的文件compute_image_mean.cpp,我们直接使用就可以了:
sudo build/tools/compute_image_mean examples/number/img_train_lmdb examples/number/mean.binaryproto创建模型并编写配置文件
模型就用程序自带的caffenet模型,位置在 models/bvlc_reference_caffenet/目录下, 将需要的两个配置文件solver.prototxt和train_val.prototxt,复制到examples/number/目录
修改solver.prototxt,指定网络配置的目录
net: "examples/number/train_val.prototxt"
test_iter: 20
test_interval: 40
base_lr: 0.01
lr_policy: "step"
gamma: 0.1
stepsize: 1000
display: 100
max_iter: 8000
momentum: 0.9
weight_decay: 0.0005
snapshot: 1000
snapshot_prefix: "examples/number/caffenet_train"
solver_mode: CPU每个参数的含义见http://blog.csdn.net/lanxuecc/article/details/52064799
这里进一步记录 我所看到的关于这些参数的含义:
net: "examples/number/train_val.prototxt"设置深度网络模型。每一个模型就是一个net,需要在一个专门的配置文件中对net进行配置,每个net由许多的layer所组成。每一个layer的具体配置方式后续会具体讲述!
test_iter: 20这个要与train_val.prototxt文件中test layer中的batch_size结合起来理解。mnist数据中测试样本总数为2000多张,一次性执行全部数据效率很低,因此我们将测试数据分成几个批次来执行,每个批次的数量就是batch_size。假设我们设置batch_size为100,则需要迭代20次才能将2000个数据全部执行完。因此test_iter设置为20。执行完一次全部数据,称之为一个epoch
test_interval: 40测试间隔。也就是每训练40次,进行一次测试。
base_lr: 0.01
lr_policy: "step"
gamma: 0.1
stepsize: 1000这四行可以放在一起理解,用于学习率的设置。只要是梯度下降法来求解优化,都会有一个学习率,也叫步长。base_lr用于设置基础学习率,在迭代的过程中,可以对基础学习率进行调整。怎么样进行调整,就是调整的策略,由lr_policy来设置。
lr_policy可以设置为下面这些值,相应的学习率的计算为:
- fixed: 保持base_lr不变.
- step: 如果设置为step,则还需要设置一个stepsize, 返回 base_lr * gamma ^ (floor(iter / stepsize)),其中iter表示当前的迭代次数
- exp: 返回base_lr * gamma ^ iter, iter为当前迭代次数
- inv: 如果设置为inv,还需要设置一个power, 返回base_lr * (1 + gamma * iter) ^ (- power)
- multistep: 如果设置为multistep,则还需要设置一个stepvalue。这个参数和step很相似,step是均匀等间隔变化,而multistep则是根据 stepvalue值变化
- poly: 学习率进行多项式误差, 返回 base_lr (1 - iter/max_iter) ^ (power)
- sigmoid: 学习率进行sigmod衰减,返回 base_lr ( 1/(1 + exp(-gamma * (iter - stepsize))))
momentum :0.9momentum是冲量单元,作用是有助于训练过程中逃离局部最小值,使网络能够更快速地收敛。如果上一次梯度方向与这一次的负梯度方向是相同的,那这次下降的幅度就会加大,所以这样做能够达到加速收敛的过程。
具体可看:https://www.zhihu.com/question/24529483
weight_decay: 0.0005权重衰减项,防止过拟合的一个参数。
具体可看:https://www.zhihu.com/question/24529483
snapshot: 1000
snapshot_prefix: "examples/number/caffenet_train"快照。将训练出来的model和solver状态进行保存,snapshot用于设置训练多少次后进行保存,默认为0,不保存。snapshot_prefix设置保存路径。
还可以设置snapshot_diff,是否保存梯度值,默认为false,不保存。
也可以设置snapshot_format,保存的类型。有两种选择:HDF5 和BINARYPROTO ,默认为BINARYPROTO
solver_mode: CPU设置运行模式。默认为GPU,如果你没有GPU,则需要改成CPU,否则会出错。
下面看下网络模型的具体设置:
name: "CaffeNet" #网络名称
#训练数据层^^^^^
layer {
name: "data" #本层名称
type: "Data" #本层类型:表明是数据层
top: "data" #该层生成一个data blob
top: "label" #该层生成一个data blob
#这一层只有top没有bottom,表明这层输出数据和标签
include {
phase: TRAIN #表明这层属于训练阶段的层
}
transform_param {
mirror: true # 1表示开启镜像,0表示关闭,也可用ture和false来表示
crop_size: 227 # 表示剪裁一个 227*227的图块,在训练阶段随机剪裁,在测试阶段从中间裁剪
mean_file: "examples/number/mean.binaryproto" #指定均值文件
}
# mean pixel / channel-wise mean instead of mean image
# transform_param {
# crop_size: 227
# mean_value: 104
# mean_value: 117
# mean_value: 123
# mirror: true
# }
data_param {
source: "examples/number/number_train_lmdb" #数据库的目录名称,指定数据位置
batch_size: 100 #一次训练的样本数
backend: LMDB #数据存储的数据类型
}
}
#训练数据层vvvvv
#测试数据层^^^^^
layer {
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TEST #表明这层属于测试阶段
}
transform_param {
mirror: false
crop_size: 227
mean_file: "examples/number/mean.binaryproto" #就用训练的均值文件
}
# mean pixel / channel-wise mean instead of mean image
# transform_param {
# crop_size: 227
# mean_value: 104
# mean_value: 117
# mean_value: 123
# mirror: false
# }
data_param {
source: "examples/number/number_test_lmdb"
batch_size: 50 #每批次处理50个图片
backend: LMDB
}
}
#测试数据层vvvvv
#第一个卷积层^^^^^
layer {
name: "conv1"
type: "Convolution" #表明这层是卷积层
bottom: "data" #表明这层前面一层也就是下面一层是数据层,该层使用的数据是由数据层提供的data blob
top: "conv1" #该层生成的数据是conv1
param {
lr_mult: 1 #weight learning rate(简写为lr)权值的学习率,1表示该值是solver.prototxt中base_lr的1倍
decay_mult: 1 #1表示该层的权重衰减是solver.prototxt中weight_decay的1倍
}
param {
lr_mult: 2 #bias learning rate偏移值的学习率,2表示该值是solver.prototxt中base_lr的2倍
decay_mult: 0 #偏移值的权重衰减为0
}
convolution_param {
num_output: 96 #卷积核的个数
kernel_size: 11 #卷积核的大小11×11,如果卷积核的长和宽不等,需要用 kernel_h 和 kernel_w 分别设定
stride: 4 #卷积核移动的步幅为4
weight_filler {
type: "gaussian" ##常见两种初始化方式:xavier和gaussian
#xavier算法,根据输入和输出的神经元的个数自动初始化权值比例
std: 0.01
}
bias_filler {
type: "constant"
value: 0 #偏置项的初始化。将偏移值初始化为“稳定”状态, 值全为0。
}
}
}
#第一个卷积层vvvvv
#激励层,具体作用见http://blog.sina.com.cn/s/blog_eb3aea990102v3um.html
layer {
name: "relu1"
type: "ReLU"
bottom: "conv1" #表明它输入数据来自第一个卷积层
top: "conv1" #表明它输出数据也放到第一个卷积层
}
#池化层
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX #池化方法,为MAX。目前可用的方法有 MAX, AVE, 或 STOCHASTIC
kernel_size: 3 #池化核大小为3*3
stride: 2 $池化核移动的步幅为2
}
}
#LRN层,具体作用http://blog.csdn.net/u014114990/article/details/47662189
layer {
name: "norm1"
type: "LRN"
bottom: "pool1"
top: "norm1"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}
#第二个卷积层
layer {
name: "conv2"
type: "Convolution"
bottom: "norm1"
top: "conv2"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 256
pad: 2 #扩充边缘,默认为0,不扩充。扩充的时候是左右、上下对称的,比如卷积核的大小为5*5,那么pad设置为2,则四个边缘都扩充2个像素,即宽度和高度都扩充了4个像素,这样卷积运算之后的特征图就不会变小。 也可以通过pad_h和pad_w来分别设定。
kernel_size: 5
group: 2
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 1
}
}
}
layer {
name: "relu2"
type: "ReLU"
bottom: "conv2"
top: "conv2"
}
layer {
name: "pool2"
type: "Pooling"
bottom: "conv2"
top: "pool2"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layer {
name: "norm2"
type: "LRN"
bottom: "pool2"
top: "norm2"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}
layer {
name: "conv3"
type: "Convolution"
bottom: "norm2"
top: "conv3"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 384
pad: 1
kernel_size: 3
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "relu3"
type: "ReLU"
bottom: "conv3"
top: "conv3"
}
layer {
name: "conv4"
type: "Convolution"
bottom: "conv3"
top: "conv4"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 384
pad: 1
kernel_size: 3
group: 2
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 1
}
}
}
layer {
name: "relu4"
type: "ReLU"
bottom: "conv4"
top: "conv4"
}
layer {
name: "conv5"
type: "Convolution"
bottom: "conv4"
top: "conv5"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 256
pad: 1
kernel_size: 3
group: 2
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 1
}
}
}
layer {
name: "relu5"
type: "ReLU"
bottom: "conv5"
top: "conv5"
}
layer {
name: "pool5"
type: "Pooling"
bottom: "conv5"
top: "pool5"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
#前面都是一些pool层,conv层 ReLU层 LRN层的重复,不再赘述
#全连接层,参数含义与前面卷积层定义相同
layer {
name: "fc6"
type: "InnerProduct"
bottom: "pool5"
top: "fc6"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 4096
weight_filler {
type: "gaussian"
std: 0.005
}
bias_filler {
type: "constant"
value: 1
}
}
}
#激励层
layer {
name: "relu6"
type: "ReLU"
bottom: "fc6"
top: "fc6"
}
#dropout层,具体见http://blog.csdn.net/u012702874/article/details/45030991
layer {
name: "drop6"
type: "Dropout"
bottom: "fc6"
top: "fc6"
dropout_param {
dropout_ratio: 0.5
}
}
#又是一个全连接层
layer {
name: "fc7"
type: "InnerProduct"
bottom: "fc6"
top: "fc7"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 4096
weight_filler {
type: "gaussian"
std: 0.005
}
bias_filler {
type: "constant"
value: 1
}
}
}
#激励层
layer {
name: "relu7"
type: "ReLU"
bottom: "fc7"
top: "fc7"
}
#dropout层
layer {
name: "drop7"
type: "Dropout"
bottom: "fc7"
top: "fc7"
dropout_param {
dropout_ratio: 0.5
}
}
#全连接层
layer {
name: "fc8"
type: "InnerProduct"
bottom: "fc7"
top: "fc8"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 1000
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
#准确率结果层,测试时用,用来计算测试效果的准确率
layer {
name: "accuracy"
type: "Accuracy"
bottom: "fc8"
bottom: "label"
top: "accuracy"
include {
phase: TEST
}
}
#损失函数层
layer {
name: "loss"
type: "SoftmaxWithLoss"
bottom: "fc8"
bottom: "label"
top: "loss"
}感谢:::::::
http://blog.csdn.net/u012746763/article/details/51549184
http://blog.csdn.net/u012746763/article/details/51549267
http://stackoverflow.com/questions/30033096/what-is-lr-policy-in-caffe
http://blog.csdn.net/liuweizj12/article/details/52152911
http://www.cnblogs.com/denny402/p/5070928.html
http://www.cnblogs.com/Evence/p/5698621.html
http://www.cnblogs.com/xiaopanlyu/p/5793280.html
http://blog.csdn.net/strint/article/details/44163869