区块链相关论文研读2 - vChain,关于可验证的查询
这是在2019年7月发表在顶会SIGMOD上的论文,题目为《vChain: Enabling Verifiable Boolean Range Queries over Blockchain Databases》,来自香港浸会大学。这是一篇满是干货的论文,代表了区块链最新的研究动态。通篇读下来感觉特别烧脑但是又特别爽快,论文逻辑清晰,表述明确,非常值得去研读。
本人这段时间要大量阅读顶刊顶会论文,在阅读论文的同时跟大家分享所提炼出来的论文内容,达到加深理解以及共同探讨研究和学习的目的。关注本人的知乎或者专栏可以获得最新的更新通知哦 =-=
1 论文所解决的问题:
如果想查询区块链中的数据,一种可行的做法是先把区块链中所有的数据下载下来,然后在本地查询。但是,通常区块链中所存储的数据量很大,下载完整的数据到本地需要很大的存储空间和网络带宽。另一种做法是,通过第三方服务提供者(Service Provider,SP)查询,用户只需要告诉SP查询指令,并等待接收从SP返回的结果。虽然这种做法省去了用户的本地存储和网络带宽的要求,但是SP所传回的查询结果可能是被篡改或者不完整的。用户的要求是所得到的结果是符合查询条件,不被篡改的同时是完整的。“不被篡改”容易理解;而“完整的”指的是没有漏查。为了满足用户这个要求,论文提出了vChain框架,支持时间窗口查询和Boolean查询。
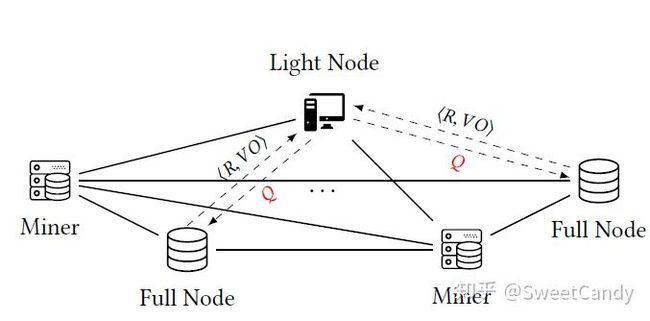
区块链网络
上图表示区块链的网络模型,其中有三种类型的节点,完整节点和矿工保存着区块链的完整数据集,轻节点只保存区块链数据的头部数据。轻节点可以通过向完整节点发送查询Q,完整节点向用户返回R和VO,R表示查询Q的结果,VO(verifiable object)是由服务提供者(Service Provider,SP)构造的用于让轻节点验证查询结果是否被是否漏查。
1.2 具体的问题定义是:
- 数据对象表示形式:一个区块中存储多个数据对象,一个对象被表示为
- 窗口查询:一个查询的格式为 ,其中ts表示时间段的开始时间,te表示时间段的结尾时间,[a, b]是多维的用于查询数字类型属性V的范围选择谓语。y表示Boolean表达式。也就是用户可以通过时间点查询,或者使用数字范围查询或者使用某一个字段查询。比如q=〈[2018-05, 2018-06], [10, +∞], send:1FFYc^receive:2DAAf〉,表示查询时间范围为[2018-05, 2018-06],数字V在[10, +∞]之间,且在W集合中满足谓语表达式send:1FFYc^receive:2DAAf的数据。其中send:1FFYc^receive:2DAAf表示既存在send:1FFYc也存在receive:2DAAf。
- 订阅查询:用户可以先提交查询,在未来如果区块链中有满足查询条件的数据,就向相应的订阅用户返回查询结果。
论文先通过讲最基础的解决方案来引出论文所提出的方法。下面是最基础的方案。
2. 基础方案 Merkle Hash Tree
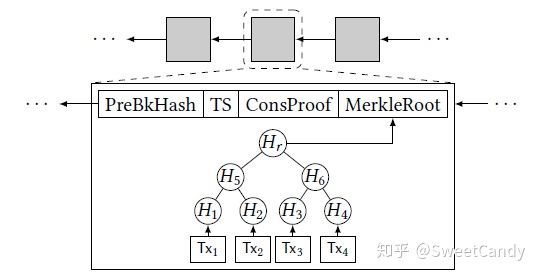
我们可以通过使用Merkle Tree来完成数据验证的问题。不过在引出问题之前,需要先明白什么是Merkle Tree。它的结构形如上图的二叉树。所有数据存在叶子节点中,非叶子节点存储的都是由两个子节点计算出的hash值。这样子就有一个明显的特点,那就是只要一个节点的数据改变了,其上层的节点也会改变。
现在我们引出使用Merkle Tree来验证数据的问题。轻节点保存着Merkle Tree的根节点数据,也就是根节点的hash值,轻节点想知道Tx4这个数据是否存在该Merkle tree中,并且要证明。
对于轻节点的要求,服务提供者应该怎么办呢?它将H5,H6,H3,Tx4这些数据发送给轻节点,跟它说Tx4在这个Merkle Tree中,你可以自个验证。轻节点收到之后,通过这些数据计算出Merkle Tree的根节点的hash值,然后跟自己原来所保存的根节点hash值对比,如果一样,表示验证通过。因为只要Merkle tree中的数据有一点改变,都会导致根节点的数据改变,这一点是由密码学安全保障的。
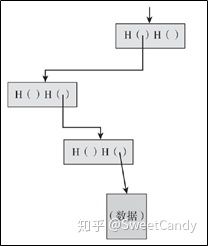
总结一下就是,服务提供者只需要向轻节点发送上图所示的数据即可完成验证的功能。这些数据是从Merkle Tree的根节点到保存数据的叶子节点的路径。轻节点使用它能够自个计算出Merke Tree的根节点的Hash值。
基础版本的方案存在三个主要缺点,一是轻节点查询的keys需要在建立Merkle Tree的时候建立好。如果想让它支持任意的属性查询的功能,需要很大的构建成本;二是Merkle Tree不支持属性集合的验证;三是在区块和区块之间,使用Merkle Tree不能做到聚集批量验证,无法做到效率优化。
在正式讲解论文的主要方案之前,本人建议了解一点密码学的基础知识,包括不对称加密技术,双线性配对(Bilinear Pairing),多重集(Multiset),Cryptographic Multiset Accumulator。不了解的话也没关系,但是需要知道下面几个函数的作用,这个很重要,直接影响到读者能否理解这篇论文,因为整篇论文都是基于这几个函数而展开的。
- KeyGen(1λ) → (sk, pk),产生公钥sk和密钥pk。
- Setup(X, pk) → acc(X),输入多重集X和公钥pk,计算出累加器的值acc(X)。具体怎么计算的可以暂时放下。
- ProveDisjoint(X1,X2, pk) → π,输入两个多重集(这两个多重集中的元素是没有交集的)和一个公钥,输出证明π。顾名思义,这个函数是用来生成两个多重集没有交集的证明。
- VerifyDisjoint(acc(X1), acc(X2), π, pk) → {0, 1},这个函数用来验证两个多重集X1和X2是否有交集,如果输出为1,表示没有交集。
读者暂时不需管上面四个函数具体如何实现的,它们的安全性是由密码学保证的。
3. Boolean类型的查询
所谓的Boolean类型的查询是很好理解的,就是轻节点提交的查询条件是一个返回值为True或者False的函数。比如一个查询条件为“Sedan”∧(“Benz”∨“BMW”),如果数据库中存在下面三个记录(1)Sedan,Benz (2)Hala, Benz (3)Sedan, BMW,那么第一个和第三个将满足查询条件。这一小节讲解论文如何实现Boolean类型的查询。
为了支持Boolean类型的查询,需要在区块头增加一个字段AttDigest,顾名思义就是属性的摘要,这个字段很有意思,第一它能够概括一个数据对象的属性W,能够证明一个对象是否满足轻节点所提交的查询(一个区块中有多个数据对象),因此,如果对象不满足查询条件,只需要返回这个AttDigest字段,而不需要返回整个数据对象给用户。第二,不管一个数据对象的属性W有多少个,AttDigest字段的大小都是固定的。第三,AttDigest支持聚合(Aggregatable)操作,这样的话就可以在同一个区块的不同对象之间以及不同区块的不同对象之间进行批量验证了。AttDigest字段的构造方法为:
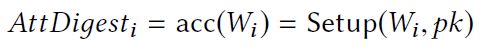

为了简化说明,这里只使用Boolean查询,查询条件为“Sedan”∧(“Benz”∨“BMW”)。只查询W属性集,并且一个区块中只有一个数据对象oi = 〈ti ,Wi 〉={“Van”, “Benz”}。
- 服务提供者生成ADS(Authenticated Data Structure)
有两种情况,第一种是,如果数据对象匹配查询条件,那么直接向轻节点发送该对象。第二种情况是数据对象不匹配查询条件,这时服务提供者需要构造不匹配证明,因为对象oi ={“Van”, “Benz”}中没有“Sedan”,所以调用函数ProveDisjoint({“Van”,“Benz”}, {“Sedan”}, pk) 生成证明π,该函数第一个参数表示数据对象的所有W属性,第二个字段表示跟数据对象不匹配的属性,该属性来自轻节点所提交的查询语句,第三个字段表示服务提供者的公钥了。
2. 轻节点验证查询结果
轻节点接收到查询结果之后,首先需要非篡改验证:需要自己根据所接收到的数据构建并计算出一个hash值,并与区块头的Merkle Tree的根节点的hash值对比,如果结果相等表示验证通过。对于与查询条件不匹配的数据对象,轻节点调用函数VerifyDisjoint(AttDigesti , acc({“Sedan”}), π, pk)来验证查询结果。第一个参数AttDigest表示保存在区块头中的字段。有一个问题,为什么轻节点调用了VerifyDisjoint函数就能够验证数据对象确实是不匹配的呢?要回答这个问题的话,本人觉得需要去查看这个函数是怎么实现的,只是需要注意,轻节点本地就拥有AttDigesti这个字段,不需要向服务提供者查询,因为他保存在区块头中,并且,AttDigest是如何构造的呢?它是由矿工在打包区块的时候调用函数AttDigesti = acc({“Van”, “Benz”})生成的(该函数的参数是当前区块所有的W属性,这里我们为了简化表述,只认为当前区块只有一个数据对象,且其W属性是Van和Benz)。从上面我们可以看出,服务提供者都向轻节点发送了哪些数据:(1)匹配查询条件的数据对象(2)不匹配查询条件的证明π值和“Sedan”,而Sedan来自于用户的查询语句中的,目的是告诉用户正是这个字段跟数据对象没有交集。
论文给出了一个具体的算法,思路跟上面所述一样,故不再累赘。

4 将Boolean类型查询拓展到范围查询
保存在区块链中的对象数据表示形式为
如何转换呢?
- 将数字转化成二进制的形式
- 将一个数字转化成二进制前缀元素,函数表示为trans(.),比如4可以表示为二进制100,所以trans(4) = {1∗, 10∗, 100}. 星号表示通配符。对于数组的话,比如(4,2)的二进制为(100, 010),前缀转化为
![]()
其中下标1和2表示数据维度。
所以,[0,7]范围内一个维度的二进制前缀树为下图所示:
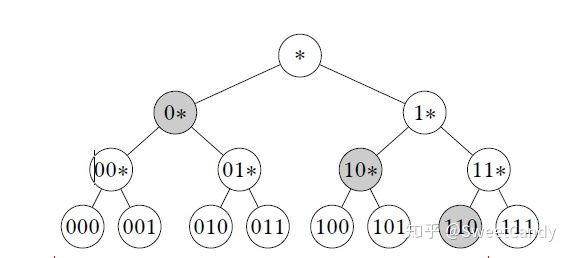
单维度的二进制前缀树
在前缀树中,如果我们要表示[a,b]的范围,那怎么办呢?思路是(1)在叶子节点找到a和b两点,a和b两叶子节点之间所有的叶子节点都是需要覆盖的节点。(2)在树中寻找最少的节点,使之恰好能够覆盖这些叶子节点。这些最少的节点包含非叶子节点。

举一个例子,上图中我们需要表示[0, 6]范围,首先我们找到红线上的叶子节点是需要覆盖的,然后,我们确定{0∗, 10∗, 110}这三个点,使之恰好能够覆盖这些叶子节点。所以这三个灰色的节点就是我们想要的。对于数字4,trans(4) = {1∗, 10∗, 100},它是在[0, 6]范围内的,因为 。这个是一维的,二维的呢?比如查询范围[(0, 3), (6, 4)] 可以被转化为,这里需要注意的是,第一维度的最小值是0,最大值是6;第二维度的最小值是3,最大值是4。所以,很明显的,对于(4,2),分别表示第一维度为4,第二维度为2,是不在查询范围[(0, 3), (6, 4)] 内的,因为2不在第二维度(3,4)范围中。这是直观感受,我们可以通过 来得出它不在范围之内。
这样子就将数字类型的范围查询拓展到了非数字类型的查询。它有一个缺点,那就是,只有整数才能被转化。
5 批量认证
批量认证可以加快认证速度。这里分两类,一类是区块内部的批量认证,第二类是区块之间的。论文分别针对这两类设计了相应的索引,来加快认证速度。
- 批量认证索引1(区块内部)
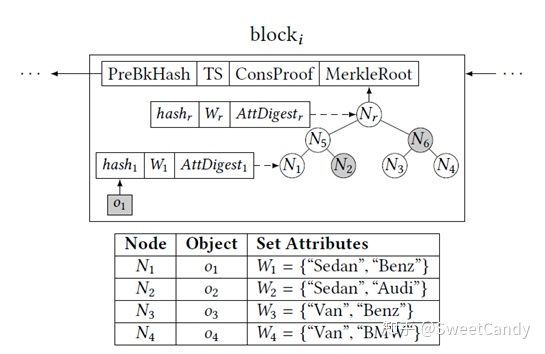
总体思想:父节点中的W集合是子节点集合的总和,所以当父节点的W集合不满足查询条件时,所有的子节点都不满足。这样子就可以节省了递归二叉树的时间。
细节:(1)作者把交集最大的两个叶子节点生成一个父节点,然后一层层往上生长,直到根节点。(2)在非叶子节点的W匹配查询条件,还需要递归直到叶子节点。
- 批量认证索引2(区块和区块之间)
这里用到了跳表这个数据结构,形如下图:
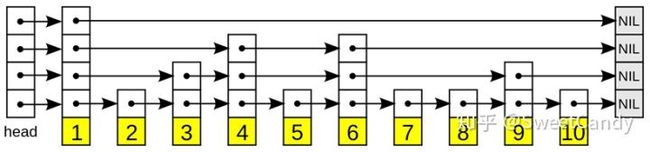
数据结构跳表

总体思路:上图红圈里面的 存储了前面(i,i-1,i-2)的所有W字段,跳跃步长为2, 存储了前面i到(i-4)所有W的字段,跳跃步长为4。存在包含关系。所以我们从右边红圈所示的队列最下端开始,判断对应的W是否匹配查询条件,如果不匹配,就表示其所跳过的区块都不匹配查询条件,因此就不需要继续往上遍历了。
6 可订阅的查询索引
这一节内容跟上面的内容没有太大关系。vChain系统提供了可以订阅的查询的功能。传统的数据库查询为,已经存在数据,我们提交查询,然后接收结果。这里面的可订阅查询服务的执行顺序相反。服务提供者先收集用户的查询语句,也就是注册查询,然后在未来如果有数据对象匹配这些查询条件,就将该数据对象发送给相应的用户。所有,分为两步来操作:
(1)服务提供者收集用户的查询语句,建立索引。
(2)当有数据对象到来,就通过索引查找所有满足条件的查询。
(3)将该数据对象发给对应的用户,同时发送不匹配的数据对象的不匹配证明。
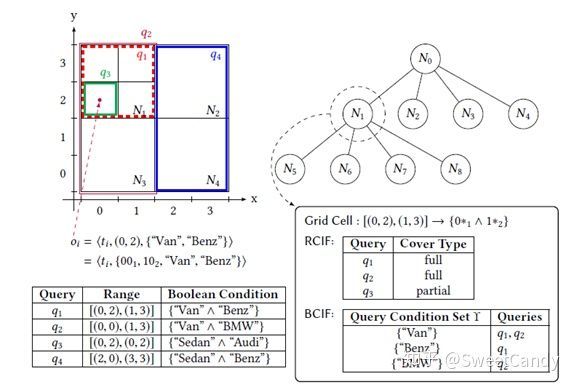
这里重点时怎么建立索引?具体为:
(1)建立一个四分树(Quadtrees),树中每一个节点都对应上图右下角的方框中的数据。Grid Cell表示该节点在左上角中的位置,这里[(0,2),(1,3)]的第一维度为0,1,第二维度为2,3,这是需要注意的地方,把它表示成二进制前缀的形式为 。RCIF表格中第一列时用户注册的查询,第二列表示该查询的查询范围是否覆盖当前树节点,这里时N1。BCIF表格存储的是上一个表格中完全覆盖当前节点的查询,这里只有q1和q2。
(2)当有新数据对象到来,只需要遍历四分树,查找RCIF表格所有full的查询,并且如果满足BCIF表格中的条件,就表示数据对象满足查询条件。
7 总结
论文提出了vChain,重点解决轻节点能够证明所收到的查询结果不被篡改,不被漏查的问题。提出了字段属性查询,数字类型的范围查询,并提出了在区块链场景上用于加快查询速度的索引。整篇文章的内容丰富,逻辑清晰,表达准确,个人觉得这是一篇值得研读的论文!
都看到这了,给个赞呗= =
关注一下呗,给一点鼓励
