基于LSTM对时间序列进行预测
本文的案例来自https://machinelearningmastery.com/time-series-prediction-lstm-recurrent-neural-networks-python-keras/
注:以下内容在该案例中进行了删改。
我们要在这篇文章中看到的问题是国际航空乘客预测问题。
这是一个问题,在一年一个月的时间里,任务是预测1000个国际航空公司的乘客数量。数据范围从1949年1月到1960年12月,或12年,有144个观察。
该数据集可从DataMarket网页免费下载,CSV文件名为 “ international-airline-passengers.csv”。
我们可以使用Pandas库轻松加载这个数据集。我们对这个日期不感兴趣,因为每个观测值都是以相同的时间间隔分开的。因此,当我们加载数据集时,我们可以排除第一列。
下载的数据集也有页脚信息,我们可以用skipfooter参数将pandas.read_csv()设置为3 来排除3页脚行。一旦加载,我们可以轻松绘制整个数据集。下面列出了加载和绘制数据集的代码。
import pandas
import matplotlib.pyplot as plt
dataset = pandas.read_csv('international-airline-passengers.csv', usecols=[1], engine='python', skipfooter=3)
plt.plot(dataset)
plt.show()长期的短期记忆网络
长期短期记忆网络(即LSTM网络)是使用反向传播时间训练并克服消失梯度问题的递归神经网络。
因此,它可以用来创建大型循环网络,反过来又可以用来解决机器学习中的难题序列问题,并获得最新的结果。
LSTM网络不是神经元,而是通过层连接的内存块。
一个块具有使其比传统神经元和最近序列的记忆更为智能的组件。一个块包含管理块的状态和输出的门。一个程序块按照一个输入序列进行操作,一个程序块内的每个门使用sigmoid激活单元来控制它们是否被触发,从而使状态的改变和信息的添加通过该块有条件地流动。
一个单元内有三种类型的门:
- 忘记门:有条件地决定从块中扔掉什么信息。
- 输入门:有条件地决定从输入中更新内存状态的值。
- 输出门:根据输入和块的内存有条件地决定输出什么。
每个单位就像一个迷你国家机器,其中单位的大门有训练过程中学习的权重。
您可以看到如何从一层LSTM中获得复杂的学习和记忆,不难想象高阶抽象如何与多个这样的层进行分层。
用于回归的LSTM网络
我们可以把这个问题称为回归问题。
也就是说,考虑到本月乘客人数(以千人计),下个月的乘客人数是多少?
我们可以写一个简单的函数来将我们的单列数据转换成两列数据集:第一列包含本月的(t)乘客计数,第二列包含下个月的(t + 1)乘客计数。
在我们开始之前,让我们先导入所有我们打算使用的函数和类。这假定安装了Keras深度学习库的工作SciPy环境。
import numpy
import matplotlib.pyplot as plt
import pandas
import math
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_errornumpy.random.seed(7)
# load the dataset
dataframe = pandas.read_csv('international-airline-passengers.csv', usecols=[1], engine='python', skipfooter=3)#原有两列,一列是时间,一列是乘客数量,这里利用usecols=[1],只取了乘客数量一列
dataset = dataframe.values #通过.values得到dataframe的值,返回shape是(144, 1)的数组形式
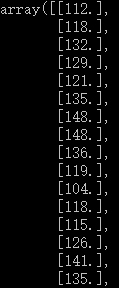
dataset = dataset.astype('float32') #把dataset里的所有数据从整型变为浮点型dataframe的导出结果:

最后dataset的输出结果为:
LSTM对输入数据的规模很敏感,特别是当使用sigmoid(默认)或tanh激活功能时。将数据重新调整到0到1的范围(也称为标准化)可能是一个很好的做法。我们可以使用scikit-learn库中的MinMaxScaler预处理类轻松地规范数据集。
scaler = MinMaxScaler(feature_range=(0, 1))
dataset = scaler.fit_transform(dataset)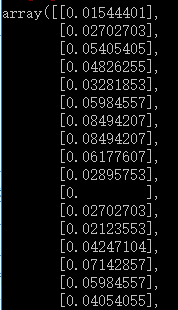
在对数据进行建模并在训练数据集上估计我们模型的技能之后,我们需要了解模型对于新的不可见数据的技巧。对于正常的分类或回归问题,我们会使用交叉验证来做到这一点。
对于时间序列数据,值的顺序很重要。我们可以使用的一个简单的方法是将有序数据集分解为训练和测试数据集。下面的代码计算分割点的索引,并将排在前面的67%的观测值数据作为训练数据集,我们可以使用这些观测值来训练我们的模型,后面剩下的33%用于测试模型。
# split into train and test sets
train_size = int(len(dataset) * 0.67)
test_size = len(dataset) - train_size
train, test = dataset[0:train_size,:], dataset[train_size:len(dataset),:]
print(len(train), len(test))
现在我们可以定义一个函数来创建一个新的数据集,如上所述。
该函数有两个参数:数据集(我们想要转换为数据集的NumPy数组)和look_back,这是以前的时间步数用作输入变量来预测下一个时间段,以前的时间步数默认为1。
这个默认值将创建一个数据集,其中X是给定时间(t)的乘客数量,Y是下一次(t + 1)的乘客数量。
它可以进行配置,我们将在下一节中构建一个不同形状的数据集。
# convert an array of values into a dataset matrix
def create_dataset(dataset, look_back=1):
dataX, dataY = [], []
for i in range(len(dataset)-look_back-1):#此处是否要去掉-1呢?待定中
a = dataset[i:(i+look_back), 0] #i:i+look_back代表用预测的时间点前的look_back点来作为输入,此处用 #前1个点作为输入
dataX.append(a)
dataY.append(dataset[i + look_back, 0])
return numpy.array(dataX), numpy.array(dataY)附录:
使用低频.csv进行预测时出现bug:
1、版本出错:
C:\Users\Administrator\Anaconda3\lib\site-packages\sklearn\preprocessing\data.py:377: DeprecationWarning: Passing 1d arrays as data is deprecated in 0.17 and will raise ValueError in 0.19. Reshape your data either using X.reshape(-1, 1) if your data has a single feature or X.reshape(1, -1) if it contains a single sample.
warnings.warn(DEPRECATION_MSG_1D, DeprecationWarning)
C:\Users\Administrator\Anaconda3\lib\site-packages\sklearn\preprocessing\data.py:377: DeprecationWarning: Passing 1d arrays as data is deprecated in 0.17 and will raise ValueError in 0.19. Reshape your data either using X.reshape(-1, 1) if your data has a single feature or X.reshape(1, -1) if it contains a single sample.
warnings.warn(DEPRECATION_MSG_1D, DeprecationWarning)
改进:讲一维数组变为二维数组

加一个[],使原先为一维数组的trainPredict变为二维数组即可