七月算法深度学习 第三期 学习笔记-第十节 深度学习与迁移学习
主要内容
o 图像识别与定位
1)思路1:视作回归
2)思路2:借助图像窗口
o 物体识别
1)边缘策略/选择性搜索 => R-CNN
2)R-CNN => Fast R-CNN
3)Fast R-CNN => Faster R-CNN
4)R-FCN简介
o 有监督到有监督的迁移学习
1)fine-tune 再优化
2)Multitask learning 多任务学习
o 有监督到无监督的迁移学习
1)域对抗学习
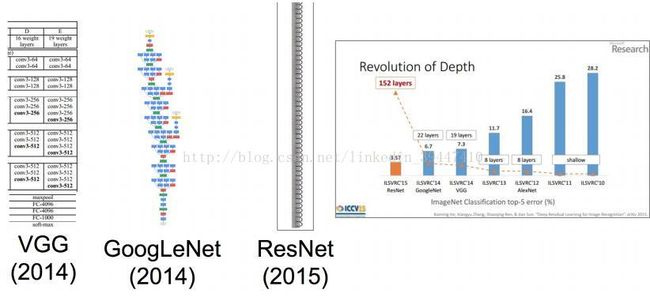
卷积神经网络
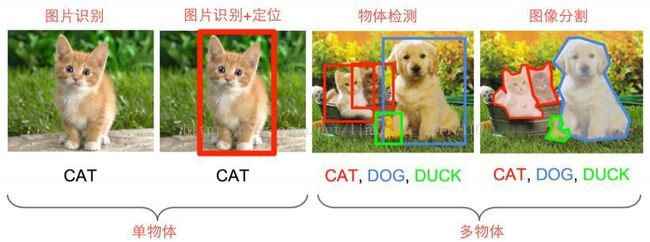
物体识别图像相关任务
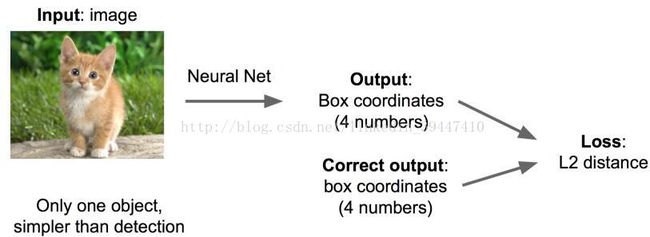
识别+定位

ImageNet包含了识别+定位两个任务

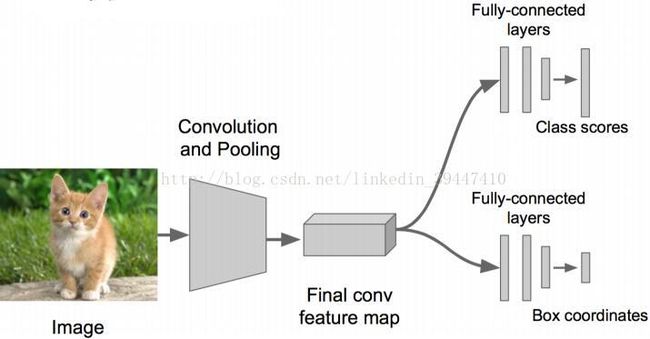
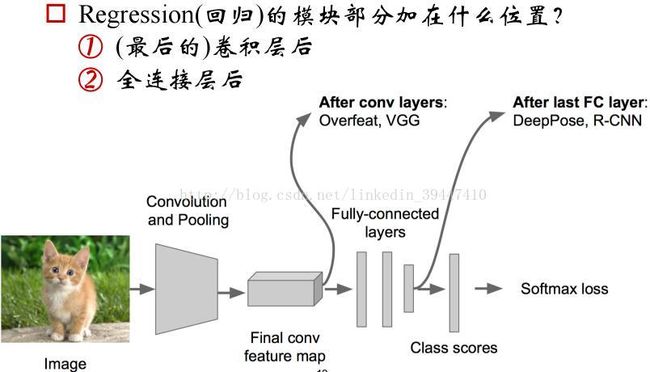
思路1:看作回归问题
4个数字,用L2 loss/欧⽒距离损失
o 步骤1: 先解决简单问题,搭一个识别图像的神经网络,然后在AlexNet VGG GoogleLenet ResNet上fine-tune一下

o 步骤2: 在上述神经网络的尾部展开,成为classification + regression模式

o 步骤3: Regression(回归)部分用欧氏距离损失,使用SGD训练
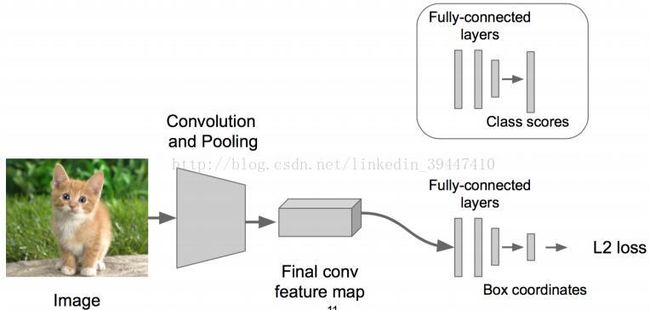
o 步骤4: 预测阶段把2个“头部”模块拼上,完成不同的功能
o 能否对主体有更细致的识别?提前规定好有K个组成部分,做成K个部分的回归
o 应用:如何识别人的姿势?每个人的组成部分是固定的,对K个组成部分(关节)做回归预测 => 首尾相接的线段
思路2: 图窗+识别与整合
o 类似刚才的classification + regression思路
o 咱们取不同的大小的“框”
o 让框出现在不同的位置
o 判定得分
o 按照得分高低对“结果框”做抽取和合并

o 实际应用时尝试各种大小窗口,甚至会在窗口上再做一些“回归”的事情

o 想办法克服一下过程中的“参数多”与“计算慢”
最初:
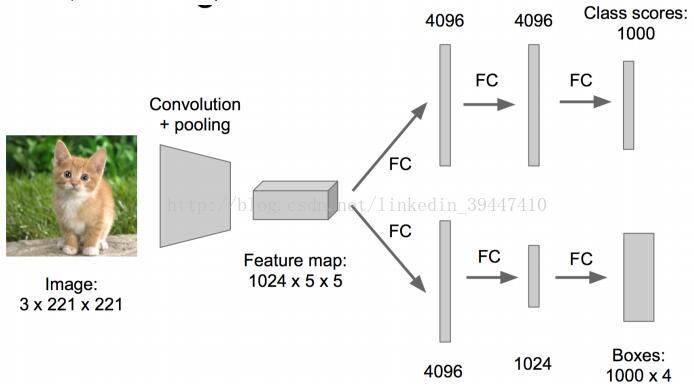
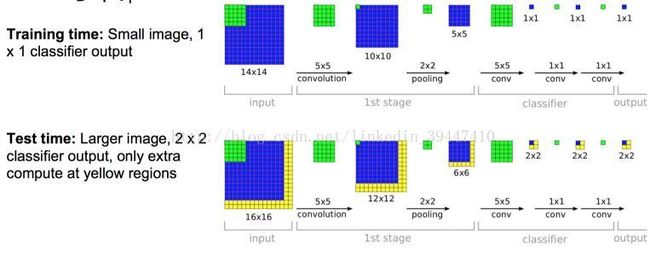
用多卷积核的卷积层 替换 全连接层
降低参数量
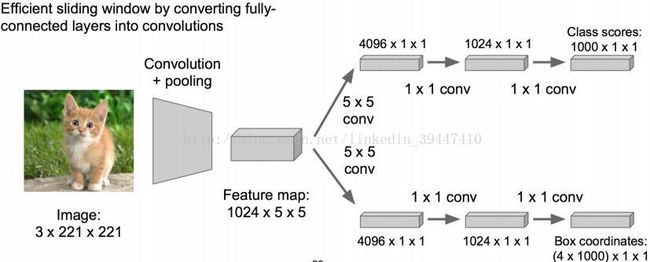
测试/识别 阶段的计算是可复用的(小卷积)
加速计算
物体识别:边缘策略
o 看做分类问题,有没有办法优化下?
1)为什么要先给定“框”,能不能找到“候选框”?
2)想办法先找到“可能包含内容的图框”

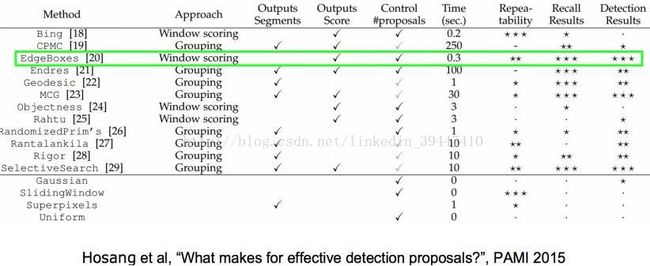
物体识别:选择性搜索
o 关于“候选图框”识别,有什么办法?
1)自下而上融合成“区域”
2)将“区域”扩充为“图框”
R-CNN
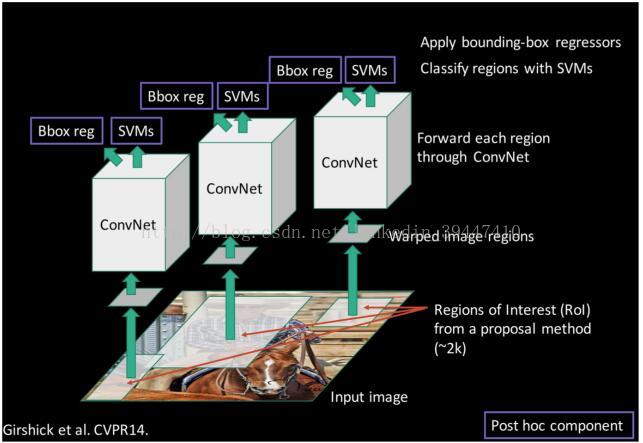
o 步骤1:找一个预训练好的模型(Alexnet,VGG) 针对你的场景做fine-tune
o 步骤2:fine-tuning模型,比如20个物体类别+1个背景
o 步骤3:抽取图片特征
1)用“图框候选算法”抠出图窗
2)Resize后用CNN做前向运算,取第5个池化层做特征
3)存储抽取的特征到硬盘/数据库上
o 步骤4:训练SVM识别是某个物体或者不是(2分类)
o 步骤5:bbox regression
R-CNN => Fast-rcnn
o 针对R-CNN的改进1 :共享图窗计算,从而加速
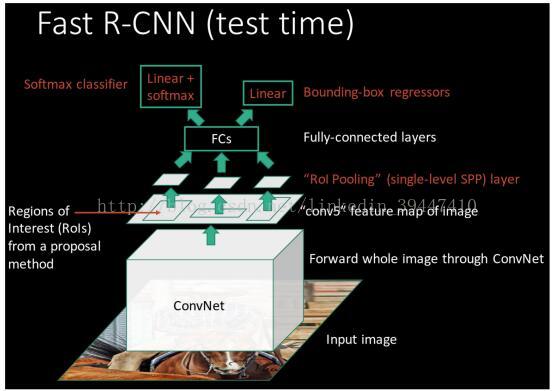
o 针对R-CNN的改进2:直接做成端到端的系统
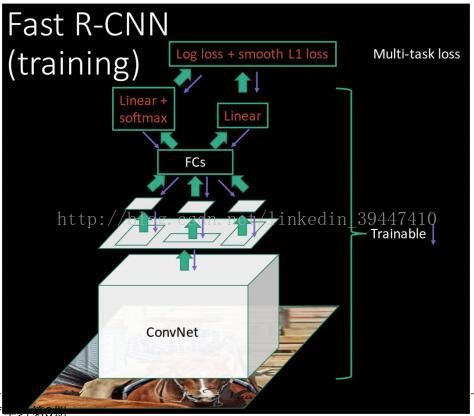
o 关于RIP:Region of Interest Pooling
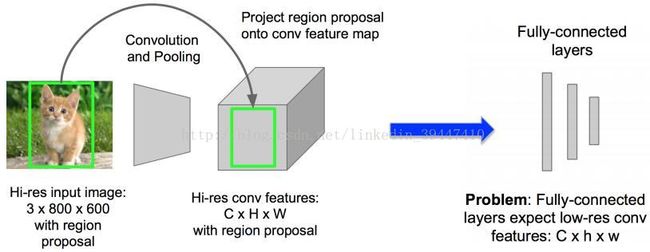
o 维度不匹配怎么办:划分格子grid => 下采样
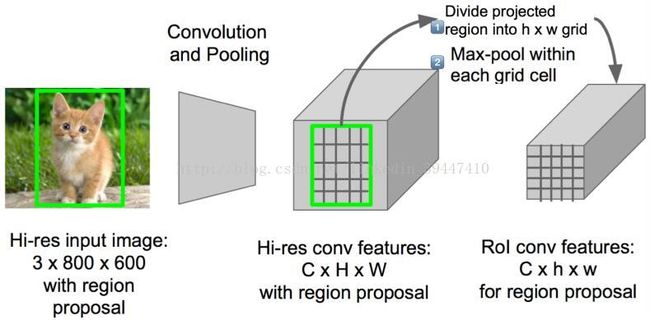
o RIP:Region of Interest Pooling :映射关系显然是可以还原回去的
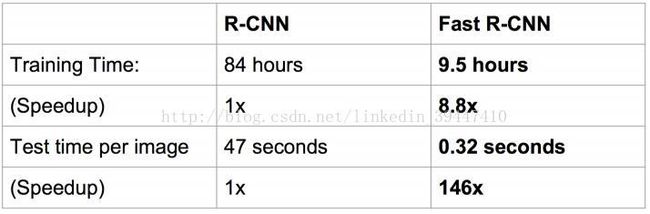
速度对比:
Fast => Faster-rcnn
o Region Proposal(候选图窗)一定要另外独立做吗?RPN
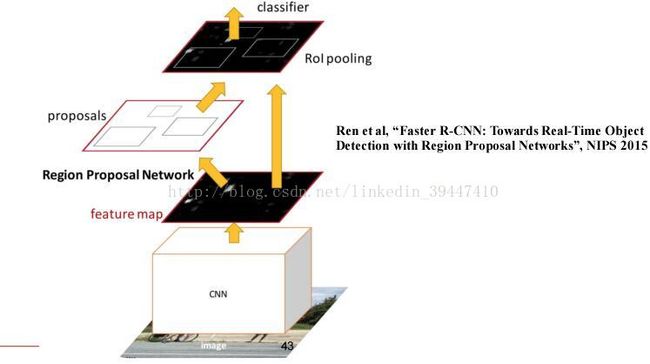
关于RPN: Region Proposal Network


o 关于Faster R-CNN的整个训练过程

速度/准度对比 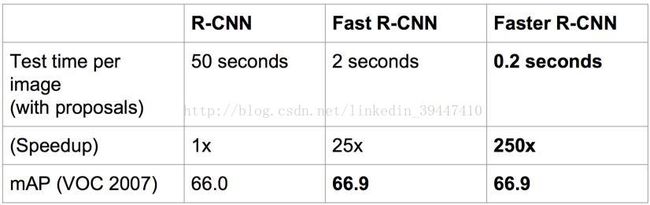
部分代码与训练数据
R-CNN
(Cafffe + MATLAB): https://github.com/rbgirshick/rcnn (非常慢,参考)
Fast R-CNN
(Caffe + MATLAB): https://github.com/rbgirshick/fast-rcnn (非端到端)
Faster R-CNN
(Caffe + MATLAB): https://github.com/ShaoqingRen/faster_rcnn
(Caffe + Python): https://github.com/rbgirshick/py-faster-rcnn
SSD
(Caffe + Python)https://github.com/weiliu89/caffe/tree/ssd
R-FCN
(Caffe + Matlab) https://github.com/daijifeng001/R-FCN
(Caffe + Python) https://github.com/Orpine/py-R-FCN
有监督到有监督:fine-tune
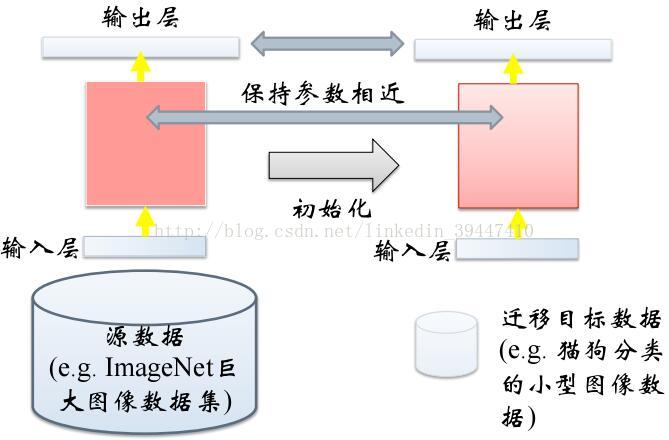
Layer Transfer

Multitask Learning:神经网络是多层次的结构,适合多任务学习
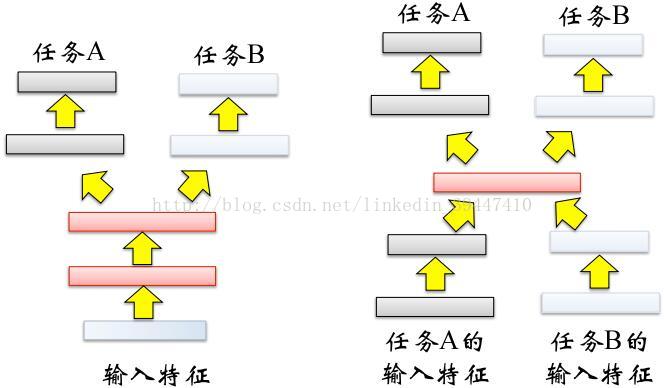
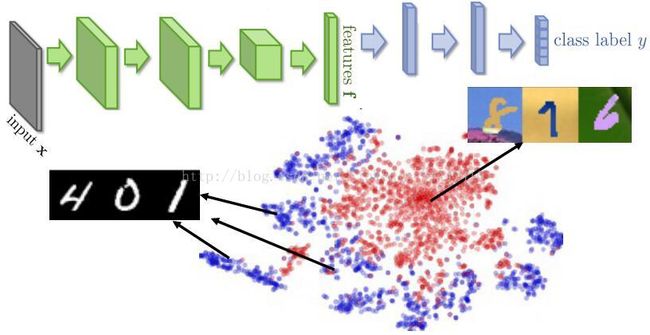
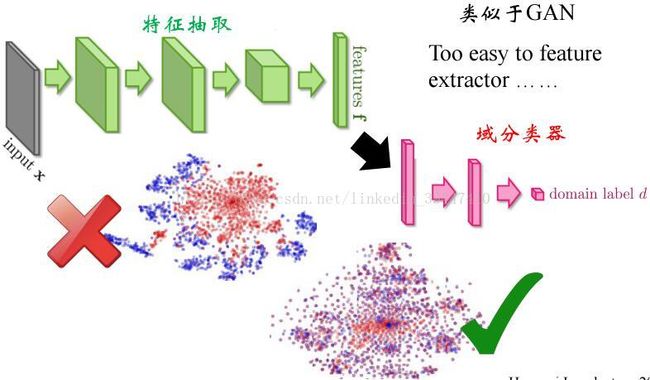
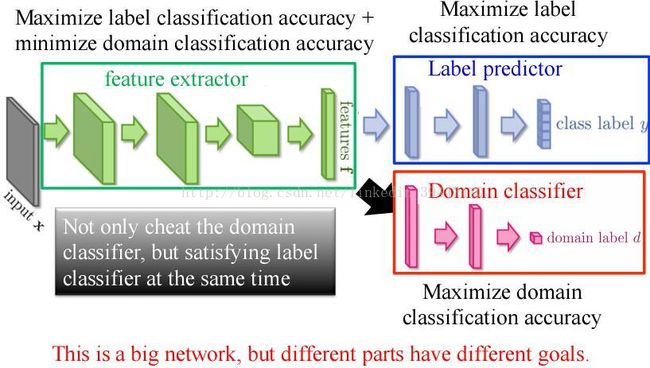
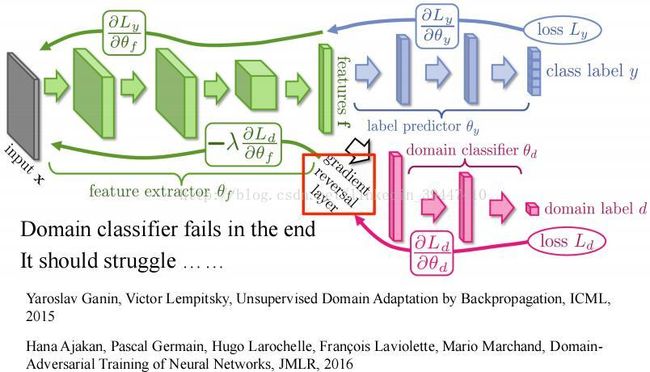
有监督到无监督:域对抗学习