Faster R-CNN改进篇(一): ION ● HyperNet ● MS CNN
一. 源起于Faster
深度学习于目标检测的里程碑成果,来自于这篇论文:
Ren, Shaoqing, et al. “Faster R-CNN: Towards real-time object detection with region proposal networks.” Advances in Neural Information Processing Systems. 2015.
也可以参考:【论文翻译】
虽然该文章前面已经讲过,但只给出了很小的篇幅,并没有作为独立的一篇展开,这里我们详细展开并讨论其 网络结构、应用领域 及 后续改进。
前面文章参考:【目标检测-RCNN系列】
二. 网络结构
Faster RCNN的网络结构图如下:
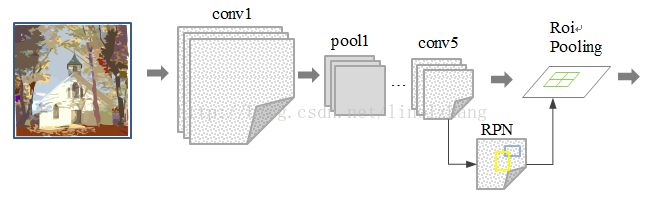
用的还是之前的图,其实对于这张图只需要记住一点:RPN网络,这是本文的核心贡献,RPN通过深度网络实现了 Proposal 功能,相较于之前的 SS(Selective Search)方法 和 EdgeBoxes 方法有很大提升。
RPN 我们来看原论文的图:

这张图虽然经典,但描述的并不太清楚,有些人可能看不明白,有几个关键点需要说明:
1)RPN 连接在 Conv5 之后
参考网络结构图,先理解 Conv5,Conv5是前面经过4次conv和pooling。
对于原图800*600的输入,Feature尺寸 变为[800/16,600/16] = [50,37.5],
Conv5的输出维度为 256,Feature维度 为 256。
2)Anchor 生成与排序
特征图采用滑窗方式遍历,每个特征像素点 对应K个 Anchor(即不同的Scale和Size),上述input对应的Anchor Count为 50*38*k(9) = 17100。
对应如此多的 Anchor,需要通过置信度剔除大多数Candidate,通常保留100-300个就足够了。
训练过程中通过IOU进行正负样本的选择,测试过程中置信度较低的被丢弃。
3)RPN 输出
如上图所示,输出分为两部分,2K Scores + 4K Reg,基于 256d 的 intermediate 层,通过两个网络,同时进行 分类 + 回归,Scores提供了作为前景、背景目标的概率(2位),Reg提供了4个坐标值,标识Box位置。
参考如下Caffe结构图,先通过3*3 的卷积核进行处理,然后1*1的卷积核进行降维,在 k=9 的情况下,每个像素对应生成 2*k = 18个 Scores 参数 和 4*k = 36个 Reg参数。
整体上 1*1 卷积生成的特征是 分类W*H*18 & 回归W*H*36,其中 ReShape 是方便 Softmax 用的,可以忽略掉。
Proposal层 根据 Softmax 输出(丢弃背景),结合对应 Anchor和Stride进行映射,将Box映射到原图,作为下一步 ROI Pooling 的输入。
4)RPN 结合方式
RPN 网络相对独立于卷积层,原文中通过 ImageNet 数据集进行预训练。
微调时,分别固定 RPN参数 和 卷积网络参数,对另外的网络部分进行微调,也就是说,虽然 Faster实现了端到端的处理,但并未实现全局的 Fine Turning。
5)ROI Pooling
提取到的 Proposal 作为输入送到 ROI Pooling 层,与 Conv5 特征图结合,即在特征图上标识出了 Proposal 的位置。

> Smooth L1 Loss
针对边框回归,可以描述为一种映射,即通过 变换函数 f,将原 Box A=(Ax, Ay, Aw, Ah) 变换为:
f(Ax, Ay, Aw, Ah) = (G'x, G'y, G'w, G'h) ,如下图所示:

t 表示与Ground Truth之间的差异系数(ln 是为了减少w,h的误差比),公式描述为(其中红色框内 σ 为一般形式,=1 时与 Fast 一致):
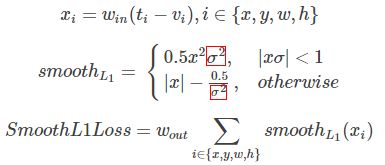
ωin 和 ωout 作为开关控制当前项是否起作用。
三. 应用领域
对于目标检测的研究分为两个方向,精度和效率,一方面以 Faster R-CNN为代表的RPN的方法在精度上不断刷新 mAP;另一方面,以SSD 和 YOLO v2 为代表的回归方法则是强调效率(或者说性价比),这两个方向在领域内都有着很大的应用场景。
Faster RCNN的代表特征是Region Proposal,通过 RPN 将检测分成两步,提供 Proposal 和 Location+Class,Proposal 越准确,后面的复合Loss里 Class所占比例就越大,分类自然就更加准确。而回归方法没有 Proposal过程,通过 Location+Class直接回归+分类,反向传播误差在Location上面大范围回归,降低了分类占比,因此分类准确度不好保证,特别是对于小目标,检测精度比较差。
检测精度是算法最核心的价值,即使是以效率为主的 回归方法 也会强调准确性,Faster 方法目前所实现的效率通常是 每秒3-5帧(GPU版本),这在非实时系统里面实际上也是足够使用的,比如在 农业上对于病虫害的检测,在医疗领域对于图像的后处理等等。
实时系统的应用是更为广阔的市场,这也是为什么说目前有相当多的人持续投入研究,比如 ADAS、机器人、无人机等,这些领域对于 实时性、准确性、成本控制的要求 带来了不断刷新纪录的研究成果。


四. 后续改进
关于 Faster RCNN 的改进比较多,我们将随时关注,保持更新。
可以参考数据集排名:【KITTI】 【PASCAL VOC 2012】【COCO】
Faster R-CNN 的三个组成部分思路包括:
1)基础特征提取网络
ResNet,IncRes V2,ResNeXt 都是显著超越 VGG 的特征网络,当然网络的改进带来的是计算量的增加。
2)RPN
通过更准确地 RPN 方法,减少 Proposal 个数,提高准确度。
3)改进分类回归层
分类回归层的改进,包括 通过多层来提取特征 和 判别。
@改进1:ION
论文:Inside outside net: Detecting objects in context with skip pooling and recurrent neural networks 【点击下载】
提出了两个方面的贡献:
1)Inside Net
所谓 Inside 是指在 ROI 区域之内,通过连接不同 Scale 下的 Feature Map,实现多尺度特征融合。
这里采用的是 Skip-Pooling,从 conv3-4-5-context 分别提取特征,后面会讲到。
多尺度特征 能够提升对小目标的检测精度。
2)Outside Net
所谓 Outside 是指 ROI 区域之外,也就是目标周围的 上下文(Contextual)信息。
作者通过添加了两个 RNN 层(修改后的 IRNN)实现上下文特征提取。
上下文信息 对于目标遮挡有比较好的适应。
来看结构图:
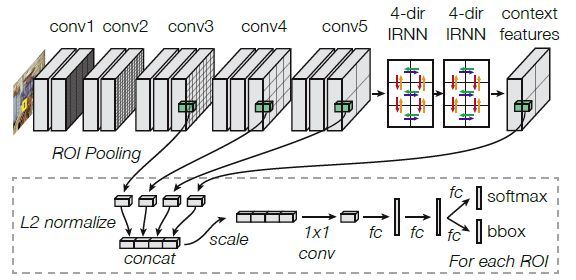
> 多尺度特征
本文不考虑 Region Proposal 的环节,只在 ROI 之后,从上图可以看到,分别从 3、4、5 层提取特征,然后再和 context得到的特征做一个连接(concat),这样做的依据是什么呢?作者给出了实验验证结果:

可以看到 Conv2 是用不到的,和我们理解的一致(尺度太大),而特征提取是 通过 L2 Norm + Scale + 1x1 Conv 得到,因为不同 Feature 之间的尺度不一致,Norm 是必须的,通过 归一化 和 Scale 进行特征提取后,送到 FC全连接层进行 分类和回归,如上图所示。
> Contextual 上下文
和前面的多尺度的思路一样,上下文也不是一个新的概念,生成上下文信息有很多种方法,来看下对比示意:

文中用的是 多维的概念,上图(d)(4-dir),如下图所示:
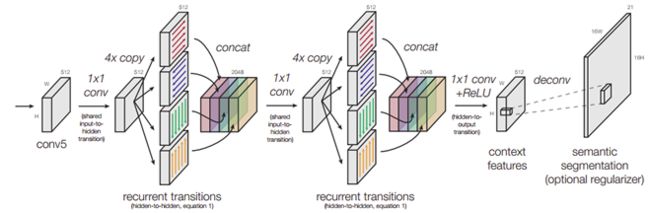
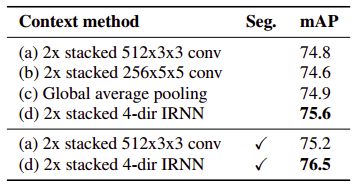
与传统的双向 RNN 不同,文中 通过上下左右四个方向,并且通过两次 IRNN 来增加非线性,更加有效的结合全局信息,看实验效果:
@改进2:多尺度之 HyperNet
论文:Hypernet: Towards accurate region proposal generation and joint object detection 【点击下载】
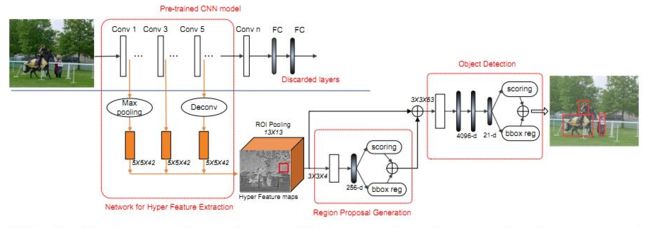
基于 Region Proposal 的方法,通过多尺度的特征提取来提高对小目标的检测能力,来看网络框图:
分为 三个主要特征 来介绍(对应上面网络拓扑图的 三个红色框):
1)Hyper Feature Extraction (特征提取)
多尺度特征提取是本文的核心点,作者的方法稍微有所不同,他是以中间的 Feature 尺度为参考,前面的层通过 Max Pooling 到对应大小,后面的层则是通过 反卷积(Deconv)进行放大。
多尺度 Feature ConCat 的时候,作者使用了 LRN进行归一化(类似于 ION 的 L2 Norm)。
抛开具体方法不表,对小目标检测来讲,这种多尺度的特征提取已经算是标配,下图证明采用 1、3、5 的效果要更优(层间隔大,关联性小)。
2)Region Proposal Generation(建议框生成)
作者设计了一个轻量级的 ConvNet,与 RPN 的区别不大(为写论文强创新^_^)。
一个 ROI Pooling层,一个 Conv 层,还有一个 FC 层。每个 Position 通过 ROI Pooling 得到一个 13*13 的 bin,通过 Conv(3*3*4)层得到一个 13*13*4 的 Cube,再通过 FC 层得到一个 256d 的向量。
后面的 Score+ BBox_Reg 与 Faster并无区别,用于目标得分 和 Location OffSet。
考虑到建议框的 Overlap,作者用了 Greedy NMS 去重,文中将 IOU参考设为 0.7,每个 Image 保留 1k 个 Region,并选择其中 Top-200 做 Detetcion。
通过对比,要优于基于 Edge Box 重排序的 Deep Box,从多尺度上考虑比 Deep Proposal 效果更好。
3)Object Detection(目标检测)
与 Fast RCNN基本一致,在原来的检测网络基础上做了两点改进:
a)在 FC 层之前添加了一个 卷积层(3*3*63),对特征有效降维;
b)将 DropOut 从 0.5 降到 0.25;
另外,与 Proposal一样采用了 NMS 进行 Box抑制,但由于之前已经做了,这一步的意义不大。
> 训练过程
采用了 联合训练(joint training)的方法,首先对 Proposal 和 Detection 分别训练,固定一个训练另一个,然后 joint 训练,即共享前面的卷积层训练一遍,具体可以参考原文给出的训练流程(这里不再赘述)。
> 效率改进
算法整体上和 Faster 运行效率相当,因为加入了多尺度的过程,理论上要比 Faster要慢,作者提出了提高效率的改进方法,将 Conv 层放在 ROI Pooling 层之前,如下图所示:

> 实验效果对比
通过对比可以看到 mAP 比 Faster 提高了 1%,主要是多尺度的功劳,其他可以忽略,这一点需要正视。

@改进3:多尺度之 MSCNN
论文:A Unified Multi-scale Deep Convolutional Neural Network for Fast Object Detection 【点击下载】
Caffe代码:【Github】
论文首先给出了不同的多尺度方法(参考下图讲解):
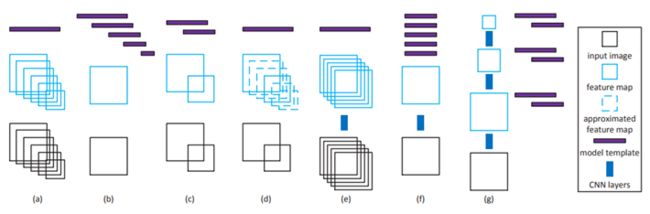
a)原图缩放,多个Scale的原图对应不同Scale的Feature;
该方法计算多次Scale,每个Scale提取一次Feature,计算量巨大。
b)一幅输入图像对应多个分类器;
不需要重复提取特征图,但对分类器要求很高,一般很难得到理想的结果。
c)原图缩放,少量Scale原图->少量特征图->多个Model模板;
相当于对 a)和 b)的 Trade-Off。
d)原图缩放,少量Scale原图->少量特征图->特征图插值->1个Model;
e)RCNN方法,Proposal直接给到CNN;
和 a)全图计算不同,只针对Patch计算。
f)RPN方法,特征图是通过CNN卷积层得到;
和 b)类似,不过采用的是同尺度的不同模板,容易导致尺度不一致问题。
g)上套路,提出我们自己的方法,多尺度特征图;
每个尺度特征图对应一个 输出模板,每个尺度cover一个目标尺寸范围。
> 拓扑图
套路先抛到一边,原理很简单,结合拓扑图(基于VGG的网络)来看:

上面是提供 多尺度 Proposal 的子图,黑色 Cube 是网络输出,其中 h*w 表示 filter尺寸,c是分类类别,b是Box坐标。
通过在不同的 Conv Layer 进行输出(conv4-3,conv5-3,conv6),对应不同尺度的 det 检测器,得到4个Branch Output。
PS:作者提到,conv4-3 Branch比价靠近Bottom,梯度影响会比后面的 Branch要大,因此多加入了一个缓冲层。
> Loss函数
再来看 Loss 函数,对于 训练样本 Si =(Xi,Yi),其中 Xi 表示输入图像,Yi={yi,bi}表示 类别标签+Box位置,M代表不同的Branch,训练样本S按照尺度划分到不同的Brach,每个Branch权值不同,用a来表示。
来看下面的公式:
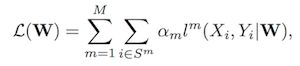
![]()

后面两个公式为最上面公式 子项的展开,公式2 中l(X,Y|W) 对应 分类Loss 和 Loc Loss的加权求和,公式3 Loc Loss 同样采用 Smooth L1 Loss,与Faster方法大致上没什么区别,此处不再展开。
> Sampling
样本的选择对于训练结果非常重要,本文采用多尺度训练,样本先划分到对应 Layer m,在对应Layer上 根据 IOU 划分为正负样本,S = {S+,S-},公式:
对应每个Ground Truth (S gt),计算与每个 Anchor Box 的 IOU,结果 o*>0.5 表示正样本,o*<0.2 归类为负样本,其余丢弃。为了保证正负样本的比例,作者提出三种方法 对负样本进行筛选:1)随机采样; 2)按Score排序,保留 Top n个强负样本(Hard Negative); 3)一般随机采样,另一半Score排序;
同样由于每个 Scale单独训练,可能会出现某个特定的 Scale 正样本不足,无法满足比例条件,即 S-/S+ >> λ,作者采用如下方法处理:
![]()
通过一个加权的 Cross Entropy 来进行比例调节,思路比较好理解。
> Training
作者 Argue 了多尺度训练的必要性,强调针对 KITTI 这种 Scale 差异比较大的数据集,有比较大的意义。引入了一个 Two-Stage 的训练过程,通过不同的参数来达到好的训练效果(具体参数和迭代次数可以参考原文章)。
> 检测网络
与 RPN 网络对应的是检测网络,检测网络与上面的 RPN网络共享一个 主干网络(trunk CNN layers),如下图所示:
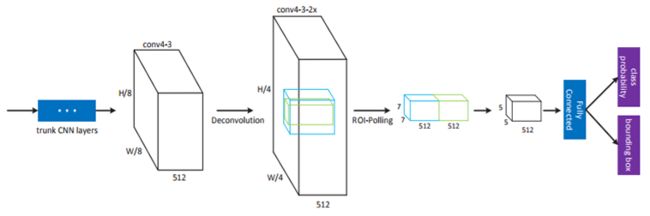
这上面有两点要说明:
1)通过在 conv4-3 后面添加一个 反卷积(Deconvolution),增加特征图的分辨率,提高了对小目标的检测精度;
2)加入 Object 的上下文(context)描述,对应上图的 蓝色 Cube,是对应Object(绿色cube)尺寸的1.5倍大小;
特征图 通过全连接层后,输出为一个分类(class probability)加一个位置(bounding box)。
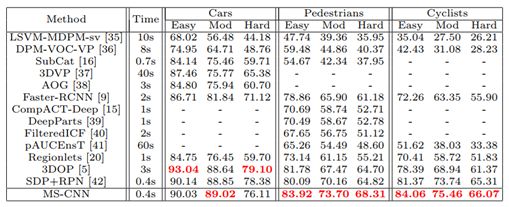
> 结果评估
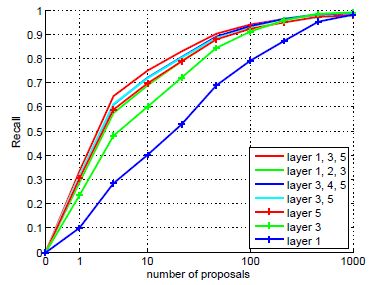
不同尺度上对目标 Recall 的影响:
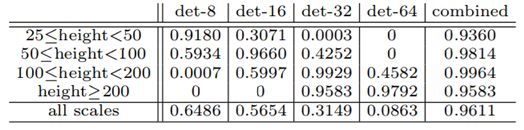
Input size 对 Proposal Recall 的影响:

比较 state-of-the-art 的 Detection 结果(看来是不错):