CVPR2019-目标检测分割技术进展
CVPR 2019 没有出现像Faster RCNN,YOLO这种开创性的工作,基于现有方案和框架的改进为主,技术进步着实有些缓慢,或许也代表方案逐步趋于成熟。
本文重点介绍如下几个改进方法:GA-RPN GIOU FSAF Mask Score RCNN
1. GA-RPN
GA-RPN由港中文、商汤和亚马逊联合提出,COCO Challenge 2018 检测任务,在极高的 baseline 上涨了1个点。
论文:Region Proposal by Guided Anchoring【paper】
先来讲候选框生成,传统的Selective Search方法提取像素一致区域,改进的EdgeBoxes利用边缘特征闭合,可以认为具有这种通用特征的区域是最有可能存在目标的区域。
这种传统方法的缺点是速度慢,很难整合到CNN网络,于是Fatser-RCNN通过暴力的 滑窗机制实现Candidate选取,也就是RPN,参考:https://blog.csdn.net/linolzhang/article/details/54344350
候选框选取机制很大程度上代表了最终检测效果的好坏,无效候选框对应大量没有价值的负样本。
- 对于 one-stage 来讲,可以通过 focal loss 一定程度上解决采样不均衡的问题,但的确只是一定程度;
- 对于 two-stage方法来讲,RPN机制保证了比 one-stage 更好的效果,3×3的Anchor 包含了大量尺度、ratio不合理的样本,虽然按照1:3的比例做样本过滤,但通常基于随机策略或按照一定的简单规则,筛选能力有限。
思想其实很简单,很多人都能想的到,理想的 Anchor 可以通过特征语义来辅助生成,也就是接下来要讲的 Guided Anchoring ,先看框架图(原文):
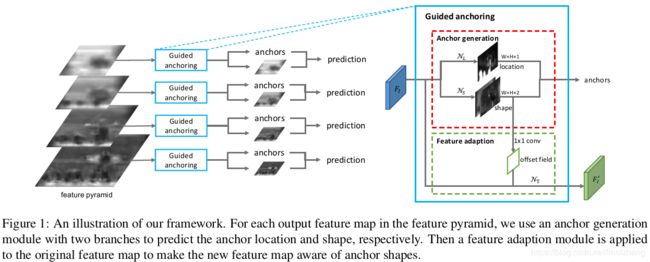
框架整体采用了特征金字塔,处理不同尺度的问题。右侧的 Anchor 生成过程(蓝色框),输入是一张特征图Fi,输出是调整后的特征图 Fi'。
Anchor生成(对应红框)借鉴了Anchor-Free的思想,能生成任意尺寸的Candidate,改进的思路是 将Box生成过程分成两部分,中心点生成 和 尺寸生成,中心点对应1个 Channel 特征图(理解为显著性区域),尺寸对应2个Channel的特征图,实现两个不同度量维度的解耦。
生成流程描述:
1)中心点生成
特征图对应一个2分类结果,表示该点是否作为目标中心,如图所示:
- Center Region(绿色部分)是作为正样本,标识目标中心,可以理解为 RPN选择 对应 IOU>0.7 的情况;
- Outside Region(灰色部分)作为负样本,可以理解为 RPN选择 对应 IOU<0.3 的情况;
- Ignore Region(黄色部分)0.3

2)尺寸生成
形状预测目标是得到对应中心的 w、h,传统直接预测的方法问题是w、h的尺度太高,通过将其映射到 [0,1],可以有效降低回归搜索空间。
通过下面的公式,实现从 dw、dh 到 w、h的映射,因此尺寸生成模块只需要预测 dw、dh 即可。
![]()
训练过程中,最大化变化的 Anchor 与 GT 的重合度,通过 max IOU 作为训练目标。
![]()
3)特征调整
由于可变的Anchor的问题,考虑根据Anchor大小适配不同尺度的特征(参考图1绿框),映射到不同的感受野,对应RPN采用的是 ROI Pooling,本文采用的是 变形Conv(不了解的可以自行搜索一下)。
首先通过形状预测分支shape通过1*1 conv,获取offset field(参考图1绿框),然后根据该offset field进行3x3的 变形卷积得到调整后的特征图 Fi'。基于特征图 Fi' 进行分类和bounding box回归。
数据训练:
定义多参数 Loss,其中 λ1、λ2 为调节参数。
![]()
结果:

2. GIOU
提出一种 Loss 度量方案,通过 IoU Loss 代替 L1 Smooth Loss,取得了不错的效果。
论文:Generalized Intersection over Union: A Metric and A Loss for Bounding Box Regression【paper】【github】
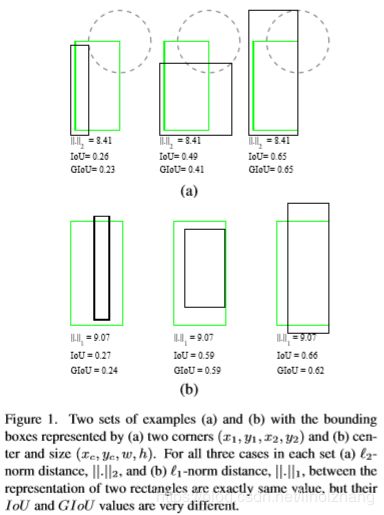
上图给出了在L1和L2一致的情况下,对应IoU是不同的,什么意思呢?既然Box和Ground Truth之间的差异是用IoU来衡量,那 最好的办法就是直接用 IoU作为Loss。
但是这里有两个问题,决定了IoU并不适合做Loss函数:
- 当两个Box不重合时,IoU为0,也就是说两个box的距离远近其结果是一样的,无法通过梯度来优化;
- IoU只能反映交并情况,无法衡量轴对齐,如下图在IoU相等的情况下,图一明显比后面收敛的更好。
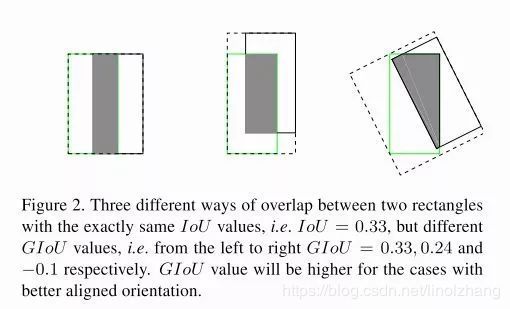
基于上面两个问题,在IoU的基础上做了扩展,提出了GIoU,公式:

其中C是指AB的最小包围盒,因此GIoU的定义是 IoU - 包围盒空余部分占比。我们来看Loss定义:
Loss = 1-GIoU = 1 - IoU + 包围盒空余部分占比 ,发现什么都没变,就加了一个包围盒的空余部分占比(记作Space),分析下这部分带来的变化:
- 当两个Box不重合时,IoU=0,不起任何作用,两个Box离得越近,Space越小(对应上面Loss越小),也就是说Space起到了拉近Box的作用;
- 当两个Box有交叠的时候,IoU开始起作用,从【没有交叉IoU=0】到【完全重叠IoU=1】,对应 Loss从1变为0,逐步收敛。那么这里Space的作用体现在哪儿呢?没错,加速轴对齐,对的越齐Space越小。
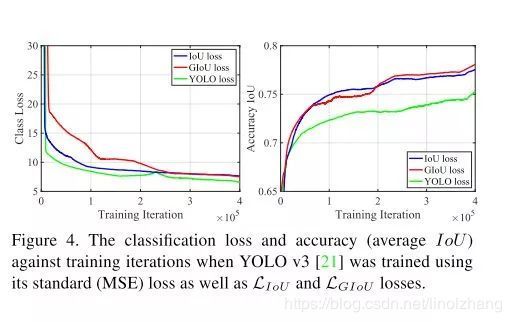
上图说明了 GIoU带来的效果提升,GIoU是一种Trcik方案,可以与任何检测框架结合,具体可以参考原文。
3. FSAF
来自CMU的一篇文章,提出了基于Single-Stage的特征层选择策略,在COCO上所有Single-Stage目标检测器中达到了SOT。
论文:Feature Selective Anchor-Free Module for Single-Shot Object Detection 【paper】
来看论文的关键点:Feature Selective & Anchor-Free,貌似都很老套,一个一个分析吧。
所谓 Feature Selective 很早前就有方法做过尝试,通俗点的说,对于特征金字塔来讲,每个层的特征代表了不同尺度的Object,在对Object进行回归的时候,选择合适的Feature层,才能提升准确度。
来看基本结构图:
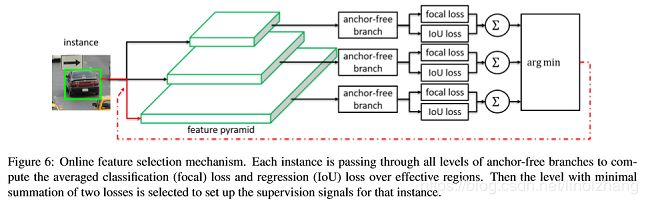
这是一个典型的Anchor-Free的结构图,通过Focal loss计算分类,通过IoU loss计算回归(前面已经讲过其优势)。结合前面的特征金字塔,这里面的关键在于argmin:
- 在训练时,获取最小的loss对应的特征层,也就是和ground truth最接近的;
- 在inference时,采用置信度最高的特征层对应的结果。
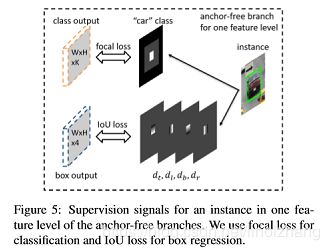
位置和形状是分开预测的,这也是今年的一个主流,当然GA-RPN预测的归一化的WH参数应该比这个更好一些,【减少预测参数、参数归一化 理论上是一个提升点】。
-
FSAF与Two-Stage框架结合:
FSAF是一个子框架,可以集成于ssd、yolo等single-stage框架下,也可以与Faster RCNN等two-stage检测框架结合,来看一个基于 RetinaNet 的例子:
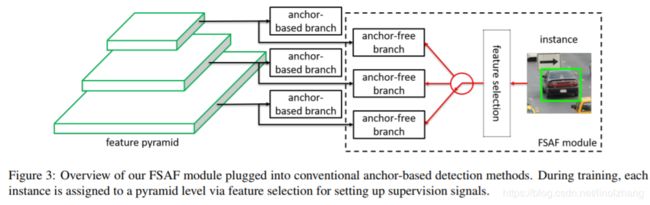
基于金字塔结构,在原来Anchor-based基础上,同时加入了Anchor Free分支(下图绿框),构建多任务学习,通过Anchor-Based 和 Anchor-Free共同学习,提升整体效果,来看进一步展开的结构图:
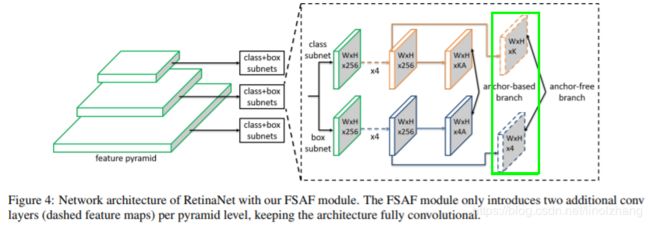
如上图所示,Anchor-Free添加的上面 WxHxK 个channel 作为分类(预测K个类别的概率),下面的 WxHx4 个channel 作为对应类别的回归,那么这里有两个问题:
1)为什么要添加这两个branch呢?
个人浅见是Multi-task有助于提升整体的准确度,这也在后面得到了证实。
2)2个分支和原来的Anchor-Based分支是如何一起工作的呢?
训练阶段把两个分支(Anchor-base 、Anchor-Free)的loss加权平均(貌似很好理解)。
推理阶段两个分支分别预测Box,预测得到的Box放在一起做 NMS。
实验结果:
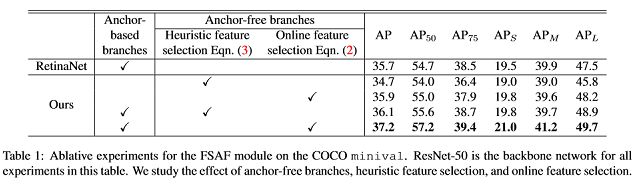
可以看到,在COCO数据集的表现很好,特别是和Anchor-Based方法结合之后,更多实验结果请参考原论文。
4. Mask Scoring RCNN
基于经典论文 Mask RCNN 扩展,加入了专门针对 Mask 的 Score分支,取得了不错的效果,因篇幅问题放到下一节讲解。