卡尔曼滤波 -- 从推导到应用(一)
前言
卡尔曼滤波器是在估计线性系统状态的过程中,以最小均方误差为目的而推导出的几个递推数学等式,也可以从贝叶斯推断的角度来推导。
本文将分为两部分:
第一部分,结合例子,从最小均方误差的角度,直观地介绍卡尔曼滤波的原理,并给出较为详细的数学推导。
第二部分,通过两个例子给出卡尔曼滤波的实际应用。其中将详细介绍一个匀加速模型,并直观的对比系统状态模型的建立对滤波的影响。
第一部分
先看一个对理解卡尔曼滤波能起到作用的的笑话:
一片绿油油的草地上有一条曲折的小径,通向一棵大树.一个要求被提出:从起点沿着小径走到树下.
“很简单.” A说,于是他丝毫不差地沿着小径走到了树下.
现在,难度被增加了:蒙上眼。
“也不难,我当过特种兵。” B说,于是他歪歪扭扭地走到了树旁。“唉,好久不练,生疏了。” (只凭自己的预测能力)
“看我的,我有 DIY 的 GPS!” C说,于是他像个醉汉似地歪歪扭扭的走到了树旁。“唉,这个 GPS 没做好,漂移太大。”(只依靠外界有很大噪声的测量)
“我来试试。” 旁边一也当过特种兵的拿过 GPS, 蒙上眼,居然沿着小径很顺滑的走到了树下。(自己能预测+测量结果的反馈)
“这么厉害!你是什么人?”“卡尔曼 ! ”
“卡尔曼?!你就是卡尔曼?”众人大吃一惊。
“我是说这个 GPS 卡而慢。”
此段引用自 highgear 的 《授之以渔:卡尔曼滤波器...大泄蜜...》 (点击可跳转到该网页)
这个小笑话很有意思的指出了卡尔曼滤波的核心,预测+测量反馈,记住这种思想。
-----------------------------------------------------------分割线-----------------------------------------------------------------------
在介绍卡尔曼滤波前,简单说明几个在学卡尔曼过程中要用到的概念。即什么是协方差,它有什么含义,以及什么叫最小均方误差估计,什么是多元高斯分布。如果对这些有了了解,可以跳过,直接到下面的分割线。
均方误差:它是"误差"的平方的期望值(误差就是每个估计值与真实值的差),也就是多个样本的时候,均方误差等于每个样本的误差平方再乘以该样本出现的概率的和。
方差:方差是描述随机变量的离散程度,是变量离期望值的距离。
注意两者概念上稍有差别,当你的样本期望值就是真实值时,两者又完全相同。最小均方误差估计就是指估计参数时要使得估计出来的模型和真实值之间的误差平方期望值最小。
两个实变量之间的协方差:
![]()
它表示的两个变量之间的总体误差,当Y=X的时候就是方差。下面说说我对协方差的通俗理解,先抛去公式中的期望不谈,即假设样本X,Y发生的概率就是1,那么协方差的公式就变成了:
![]()
这就是两个东西相乘,马上联想到数值图像里的相关计算。如果两个变量的变化趋势一致,也就是说如果其中一个大于自身的期望值,另外一个也大于自身的期望值,那么两个变量之间的协方差就是正值。如果两个变量的变化趋势相反,即其中一个大于自身的期望值,另外一个却小于自身的期望值,那么两个变量之间的协方差就是负值。协方差矩阵只不过就是元素多了组成了矩阵,其中协方差矩阵的对角线就是方差,具体公式形式请见wiki。
其实,这种相乘的形式也有点类似于向量投影,即两个向量的内积。再远一点,联想到傅里叶变换里频谱系数的确定,要确定一个函数f(x)在某个频率w上的频谱,就是
高斯分布:概率密度函数图像如下图,四条曲线的方差各不相同,方差决定了曲线的胖瘦高矮。(图片来源:维基百科)
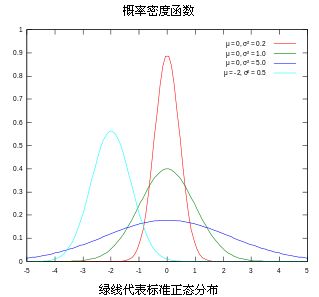
多元高斯分布:就是高斯分布的低维向高维的扩展,图像如下。

对应多元高斯分布的公式也请自行谷歌,以前高斯公式中的方差也变成了协方差,对应上面三张图的协方差矩阵分别如下:

注意协方差矩阵的主对角线就是方差,反对角线上的就是两个变量间的协方差。就上面的二元高斯分布而言,协方差越大,图像越扁,也就是说两个维度之间越有联系。
-----------------------------------------------------------分割线---------------------------------------------------------------------
这部分每讲一个数学性的东西,接着就会有相应的例子和直观的分析帮助理解。
首先假设我们知道一个线性系统的状态差分方程为
![]()
其中x是系统的状态向量,大小为n*1列。A为转换矩阵,大小为n*n。u为系统输入,大小为k*1。B是将输入转换为状态的矩阵,大小为n*k。随机变量w为系统噪声。注意这些矩阵的大小,它们与你实际编程密切相关。
看一个具体的匀加速运动的实例。
有一个匀加速运动的小车,它受到的合力为 ft , 由匀加速运动的位移和速度公式,能得到由 t-1 到 t 时刻的位移和速度变化公式:

该系统系统的状态向量包括位移和速度,分别用 xt 和 xt的导数 表示。控制输入变量为u,也就是加速度,于是有如下形式:
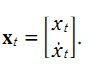
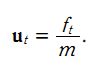
所以这个系统的状态的方程为:

这里对应的的矩阵A大小为 2*2 ,矩阵B大小为 2*1。
貌似有了这个模型就能完全估计系统状态了,速度能计算出,位移也能计算出。那还要卡尔曼干嘛,问题是很多实际系统复杂到根本就建不了模。并且,即使你建立了较为准确的模型,只要你在某一步有误差,由递推公式,很可能不断将你的误差放大A倍(A就是那个状态转换矩阵),以至于最后得到的估计结果完全不能用了。回到最开始的那个笑话,如果那个完全凭预测的特种兵在某一步偏离了正确的路径,当他站在错误的路径上(而他自己以为是正确的)做下一步预测时,肯定走的路径也会错了,到最后越走越偏。
既然如此,我们就引进反馈。从概率论贝叶斯模型的观点来看前面预测的结果就是先验,测量出的结果就是后验。
测量值当然是由系统状态变量映射出来的,方程形式如下:

注意Z是测量值,大小为m*1(不是n*1,也不是1*1,后面将说明),H也是状态变量到测量的转换矩阵。大小为m*n。随机变量v是测量噪声。
同时对于匀加速模型,假设下车是匀加速远离我们,我们站在原点用超声波仪器测量小车离我们的距离。
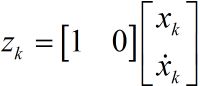
也就是测量值直接等于位移。可能又会问,为什么不直接用测量值呢?测量值噪声太大了,根本不能直接用它来进行计算。试想一个本来是朝着一个方向做匀加速运动的小车,你测出来的位移确是前后移动(噪声影响),只根据测量的结果,你就以为车子一会往前开一会往后开。
对于状态方程中的系统噪声w和测量噪声v,假设服从如下多元高斯分布,并且w,v是相互独立的。其中Q,R为噪声变量的协方差矩阵。
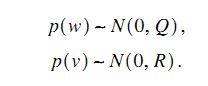
看到这里自然要提个问题,为什么噪声模型就得服从高斯分布呢?请继续往下看。
对于小车匀加速运动的的模型,假设系统的噪声向量只存在速度分量上,且速度噪声的方差是一个常量0.01,位移分量上的系统噪声为0。测量值只有位移,它的协方差矩阵大小是1*1,就是测量噪声的方差本身。
那么:

Q中,叠加在速度上系统噪声方差为0.01,位移上的为0,它们间协方差为0,即噪声间没有关联。
理论预测(先验)有了,测量值(后验)也有了,那怎么根据这两者得到最优的估计值呢?首先想到的就是加权,或者称之为反馈。
我们认定![]() 是预测(先验)值,
是预测(先验)值,![]() 是估计值,
是估计值,![]() 为测量值的预测,在下面的推导中,请注意估计和预测两者的区别,不混为一谈。由一般的反馈思想我们得到估计值:
为测量值的预测,在下面的推导中,请注意估计和预测两者的区别,不混为一谈。由一般的反馈思想我们得到估计值:
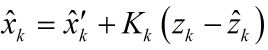
![]()
其中,![]() 称之为残差,也就是预测的和你实际测量值之间的差距。如果这项等于0,说明预测和测量出的完全吻合。这种反馈递推的形式又让我联想到数值分析里用来求解线性方程组时的一种迭代方法,Gauss-Seidel迭代法,有兴趣的可以看看。
称之为残差,也就是预测的和你实际测量值之间的差距。如果这项等于0,说明预测和测量出的完全吻合。这种反馈递推的形式又让我联想到数值分析里用来求解线性方程组时的一种迭代方法,Gauss-Seidel迭代法,有兴趣的可以看看。
现在的关键就是求取这个K。这时最小均方误差就起到了作用,顺便在这里回答为什么噪声必须服从高斯分布,在进行参数估计的时候,估计的一种标准叫最大似然估计,它的核心思想就是你手里的这些相互间独立的样本既然出现了,那就说明这些样本概率的乘积应该最大(概率大才出现嘛)。如果样本服从概率高斯分布,对他们的概率乘积取对数ln后,你会发现函数形式将会变成一个常数加上样本最小均方误差的形式。因此,看似直观上很容易理解的最小均方误差理论上来源就出于那里(详细过程还请自行谷歌,请原谅,什么都讲的话就显得这边文章没有主次了)。
先看估计值和真实值间误差的协方差矩阵,提醒一下协方差矩阵的对角线元素就是方差,求这个协方差矩阵,就是为了利用他的对角线元素的和计算得到均方差.
![]()
这里请注意ek是向量,它由各个系统状态变量的误差组成。如匀加速运动模型里,ek便是由位移误差和速度误差,他们组成的协方差矩阵。表示如下:
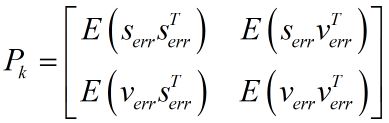
其中,Serr代表位移误差,Verr代表速度误差,对角线上就是各自的方差。
把前面得到的估计值代入这里能够化简得:
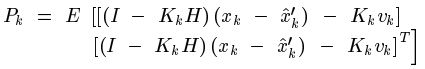 (1)式
(1)式
同理,能够得到预测值和真实值之间误差的协方差矩阵:
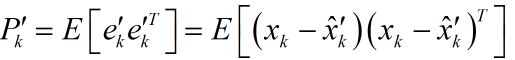
注意到系统状态x变量和测量噪声之间是相互独立的。于是展开(1)式可得:
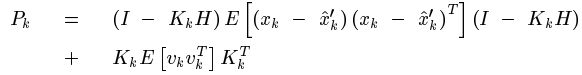
最后得到:
![]()
继续展开:
![]()
接下来最小均方差开始正式登场了,回忆之前提到的,协方差矩阵的对角线元素就是方差。这样一来,把矩阵P的对角线元素求和,用字母T来表示这种算子,他的学名叫矩阵的迹。
![]()
最小均方差就是使得上式最小,对未知量K求导,令导函数等于0,就能找到K的值。
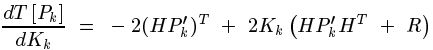
![]()
注意这个计算式K,转换矩阵H式常数,测量噪声协方差R也是常数。因此K的大小将与预测值的误差协方差有关。不妨进一步假设,上面式子中的矩阵维数都是1*1大小的,并假设H=1,![]() 不等于0。那么K可以写成如下:
不等于0。那么K可以写成如下:
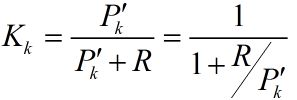
所以![]() 越大,那么K就越大,权重将更加重视反馈,如果
越大,那么K就越大,权重将更加重视反馈,如果![]() 等于0,也就是预测值和真实值相等,那么K=0,估计值就等于预测值(先验)。
等于0,也就是预测值和真实值相等,那么K=0,估计值就等于预测值(先验)。
将计算出的这个K反代入Pk中,就能简化Pk,估计协方差矩阵Pk的:
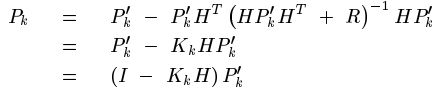
因此递推公式中每一步的K就计算出来了,同时每一步的估计协方差也能计算出来。但K的公式中好像又多了一个我们还未曾计算出来的东西![]() ,他称之为预测值和真实值之间误差的协方差矩阵。它的递推计算如下:
,他称之为预测值和真实值之间误差的协方差矩阵。它的递推计算如下:
请先注意到预测值的递推形式是: ![]()
![]()
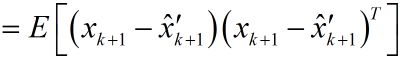

由于系统状态变量和噪声之间是独立,故可以写成:
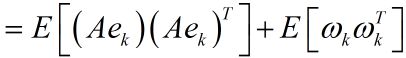
![]()
由此也得到了![]() 的递推公式。因此我们只需设定最初的
的递推公式。因此我们只需设定最初的![]() ,就能不断递推下去。
,就能不断递推下去。
这里总结下递推的过程,理一下思路:
首先要计算预测值、预测值和真实值之间误差协方差矩阵。
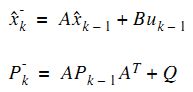
有了这两个就能计算卡尔曼增益K,再然后得到估计值,
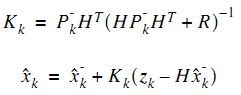
最后还要计算估计值和真实值之间的误差协方差矩阵,为下次递推做准备。
![]()
至此,卡尔曼滤波的理论推导到此结束。还有一些如实际应用中状态方程建立不正确,预测结果会怎样等这样的细节问题,以及一些总结留到第二部分讨论。
(转载请注明作者和出处:http://blog.csdn.net/heyijia0327 未经允许请勿用于商业用途)