Word2Vec (Part 1): NLP With Deep Learning with Tensorflow (Skip-gram)
Tensorflow上其实本来已经有word2vec的代码了,但是我第一次看的时候也是看得云里雾里,还是看得不太明白。并且官方文档中只有word2vec的skip-gram实现,所以google了一下,发现了这两篇好文章,好像也没看到中文版本,本着学习的态度,决定翻译一下,一来加深一下自己的理解,二来也可以方便一下别人。第一次翻译,如有不当,欢迎指出。
原文章地址:
Word2Vec (Part 1): NLP With Deep Learning with Tensorflow (Skip-gram)
Word2Vec (Part 2): NLP With Deep Learning with Tensorflow (CBOW)
文章如下:
下面我将写一写关于将词转化为向量的两种常用的技术:Skip-gram模型与CBOW模型。这两个都是学习词上下文的非监督学习方法。
文章的大致结构如下:
首先讨论一下Word2vec技术的动机,
然后我将会研究一下Skip-gram与CBOW模型运作的细节,
最后我会给出一些有助于理解代码的技术细节。
文章代码基于5_word2vec.ipynb(由python编写)
对Word2Vec的介绍
Word2Vec是一种有效的技术,以无监督的方式从大型文本预料库中获取知识。鉴于Web(或wiki)拥有大量的文本,自然语言处理可以以无监督的方式处理可用数据将非常有益。我们还应该理解到,给数据标注标签是一个非常繁琐和费力的任务,需要耗费大量的人力物力。而有关于这些技术的进一步阅读,可以参照Mikolov等人的文章Efficient Estimation of Word Representations in Vector Space和Distributed Representations of Words and Phrases and their Compositionality
词向量
那么Word2Vec是如何帮助我们处理NLP任务的呢?这是通过学习一个词汇的向量空间,并且相似的词汇将会相互靠近。打个比方,cat 将会和 kitten 很接近,dog 距离kitten 会远些,距离 iphone 则会更加远。通过学习词的数值表示,我们还可以进行很多向量操作得到一些有趣的结果。比如 kitten - cat + dog 得到的结果将会与 puppy 十分接近。
下面是一个学习好的词向量空间用T-SNE可视化的例子。可以看到相似的词汇彼此之间十分接近。

Skip-gram模型: 一个学习词向量的方法
概要
接下来我们看看Word2Vec是如何运行的。skip-gram的主要思想是基于每个词的上下文训练模型,因此相似的词将会有相似的数值表达(相似的词向量)。比如,当我们看到如下的句子:cat climbed the tree ,对于我们的模型来说,如果看到 cat 这个词,说明我们预计很快会看到 climbed 与 tree 这两个词。充分地重复过后,我们的模型将会学习到给定词汇的向量表示。
现在我们来理解一下如何通过学习词的上下文来帮助我们学习到好的词向量。我们将在下列两个句子重复上述过程, cat climbed a tree 和 kitten climbed a tree ,如果我们使用(input : cat, output : tree) 和 (input : kitten, output : tree) 来训练模型的话,最终我们会使得模型理解到, cat 和 kitten 都与 tree 有关,因此 cat 与 kitten 在向量空间中会十分接近。
模型
现在我们来看看我们怎么样使得Skip-gram模型运行。
我们先定义如下的符号:
V - 词汇表的大小(语料库当中唯一词的数量)
P - 投影层或向量层
D - 向量空间的维度
b - 单个Batch的大小
我们假设的模型是简单的逻辑回归(Softmax)模型。因此高级的框架如下所示。下面给出了两个图,左边的是概念框架,右边的是实现框架。虽然框架不同,但是它们没有对功能做任何改变。
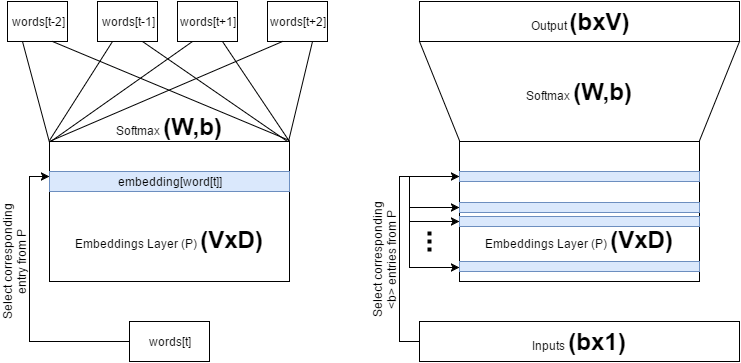
下面我们来说说两个架构有什么不同。为了方便说明,我们假设处理的句子为 The dog barked at the mailman 。我们可以将第一个模型可视化为一个正在对数据 (Softmax层的权重(weights)和偏差(biases)。换句化说,概念模型训练对同一个输入同时训练多个输出。然而这实际上很难实现。因此我们通常把元组input:'dog',output:['the','barked','at','the','mailman']) 进行训练的模型,它们共享 (input:'dog',output:['the','barked','at','the','mailman']) 拆分成为单个的二元组,如 (input:'dog', output:'the'),(input:'dog', output:'barked'),...,(input:'dog', output:'mailman') ,也就是右边图片的做法。
数据收集
考虑如下句子,The dog barked at the mailman 。首先我们先选中 dog 这个词为目标词, 然后我们定义窗口大小为 skip_window 也就是我们考虑目标单词上下文的个数(注意也就是考虑目标词前(或后)的词的个数)。比如我们选定 skip_window = 2 , 那么窗口内包含的词(也就是上下文)就是 ['The','dog','barked','at'] 。同样我们还定义 span 为窗口内词的总数(包括目标词本身,因此我们可以得到 span >= 2 * skip_window + 1 )。另外还定义 num_skips 为在 span 内对目标词选取作为输出词的数目。现在假定 skip_window=2 且 num_skips=2 , 我们可以得到(input, output)元组为 ('dog','barked'),('dog','the') 。
在这里我们不叙述如何生成batch,具体的算法可以参考5_word2vec.ipynb中的 read_data , build_dataset 与 generate_batch 函数。更多注释的版本可以参考( 5_word2vec.py 和 5_word2vec_cbow.py )
我们只要知道,上面的几个函数可以将文本转化为数值表示。换句话说,它会赋予每个唯一的词唯一的编号(ID)。比如,将 The dog barked at the mailman 放入函数中处理之后,将会输出 [1,2,3,1,4] ,其中id(‘the’)=1, id(‘dog’)=2等等。
训练模型
现在我们有了(input, output)的二元组,接下来我们要利用它们来训练模型。下面我们将会解释如何利用tensorflow来实现skip-gram模型。
首先我们定义需要的 input, output 以及其它 Tensor 和参数值。
if __name__ == '__main__':
batch_size = 128
embedding_size = 128
skip_window = 1 # How many words to consider left and right.
num_skips = 2 # How many times to reuse an input to generate a label.
valid_size = 16 # Random set of words to evaluate similarity on.
valid_window = 100
# pick 8 samples from (0,100) and (1000,1100) each ranges. lower id implies more frequent
valid_examples = np.array(random.sample(range(valid_window), valid_size//2))
valid_examples = np.append(valid_examples,random.sample(range(1000,1000+valid_window), valid_size//2))
num_sampled = 64 # Number of negative examples to sample for sampeled_softmax.
graph = tf.Graph()
with graph.as_default(), tf.device('/cpu:0'):
# Input data.
train_dataset = tf.placeholder(tf.int32, shape=[batch_size])
train_labels = tf.placeholder(tf.int32, shape=[batch_size, 1])
valid_dataset = tf.constant(valid_examples, dtype=tf.int32)
# Variables.
embeddings = tf.Variable(tf.random_uniform([vocabulary_size, embedding_size], -1.0, 1.0))
softmax_weights = tf.Variable(tf.truncated_normal([vocabulary_size, embedding_size],
stddev=1.0 / math.sqrt(embedding_size)))
softmax_biases = tf.Variable(tf.zeros([vocabulary_size]))现在我们定义符号操作。 首先 embedding_lookup 用于查找 inputs 中相对应的 embeddings 。换句话说, embedding layer 的大小是VxD,其中包含词典中所有的词(V个)的词向量(D维)。为了训练单个实例的模型,你需要通过ID查找到给定输入单词的相应词向量( 这里的 train_dataset 包含 batch 中每个单词相对应的一组唯一的ID)。尽管可以手动执行该操作,但是由于tensorflow不允许使用 Tensors 进行索引查找,因此我们需要使用该函数。
embed = tf.nn.embedding_lookup(embeddings, train_dataset)接下来,我们使用 softmax 的一个更改版本来计算 loss 。因为正式文本的词典(V)可能非常大(接近50000),计算全部的 softmax loss 将会十分耗时。因此,我们从全部(V个)softmax units 中采样 num_sample 个作为 negative softmax units ,并且只使用它们计算 loss 。我们发现这是非常有效的对 full softmax 的近似,并且还提高了性能。
loss = tf.reduce_mean(tf.nn.sampled_softmax_loss(softmax_weights,
softmax_biases,
embed,
train_labels,
num_sampled,
vocabulary_size))现在我们使用一个高级梯度优化技术叫做 Adagrad ,它让我们“大海捞针”成为可能。它比标准的GD效果更好,因为 Adagrad 能胜任有多个变量 (
softmax_weights ,
softmax_biases 和
embed )需要优化的工作。要知道,所有这些变量的规模都达到 1,000,000 之大。
optimizer = tf.train.AdagradOptimizer(1.0).minimize(loss)这个代码段使用所学习的词向量来计算一个给定的 minibatch 与所有单词之间的相似度(余弦距离)。
# We use the cosine distance:
norm = tf.sqrt(tf.reduce_sum(tf.square(embeddings), 1, keep_dims=True))
normalized_embeddings = embeddings / norm
valid_embeddings = tf.nn.embedding_lookup(normalized_embeddings, valid_dataset)
similarity = tf.matmul(valid_embeddings, tf.transpose(normalized_embeddings))现在,所有需要的东西都已经定义好了,我们所要做的就是将数据喂给 placeholder 然后运行 optimizer 。optimizer 将会对参数(
softmax_weights ,
softmax_biases 和
embeds)最小化 loss 。然后我们还要运行 loss 操作来输出 average loss 。这一步十分重要,因为我们可以通过 average loss 来观察训练过程中有没有出现问题。
with tf.Session(graph=graph) as session:
tf.initialize_all_variables().run()
print('Initialized')
average_loss = 0
for step in range(num_steps):
batch_data, batch_labels = generate_batch(batch_size, num_skips, skip_window)
feed_dict = {train_dataset : batch_data, train_labels : batch_labels}
_, l = session.run([optimizer, loss], feed_dict=feed_dict)
average_loss += l
if step % 2000 == 0:
if step > 0:
average_loss = average_loss / 2000
# The average loss is an estimate of the loss over the last 2000 batches.
print('Average loss at step %d: %f' % (step, average_loss))
average_loss = 0现在每达到10000 steps 我们就通过 valid_dataset 中最相似的 top_k 个单词来评估我们的模型。
# note that this is expensive (~20% slowdown if computed every 500 steps)
if step % 10000 == 0:
sim = similarity.eval()
for i in range(valid_size):
valid_word = reverse_dictionary[valid_examples[i]]
top_k = 8 # number of nearest neighbors
nearest = (-sim[i, :]).argsort()[1:top_k+1]
log = 'Nearest to %s:' % valid_word
for k in range(top_k):
close_word = reverse_dictionary[nearest[k]]
log = '%s %s,' % (log, close_word)
print(log)
final_embeddings = normalized_embeddings.eval()实验结果
如果在之前过程之中没有出现错误,你应该能看到随着时间的推移,词相似度的提升。这里是我在第0步和第10000步的结果
==========================================================================================================
Average loss at step 0: 7.805069
Nearest to when: drummer, acceleration, compost, loan, severe, quicker, nite, pies,
Nearest to people: hr, infertile, detractors, programmability, capacitors, lounge, report, horn,
Nearest to american: department, corvettes, rejoining, lindy, laconic, wels, kojiki, bibliography,
Nearest to than: dallas, corrino, whispers, empowered, intakes, homer, salvage, fern,
...
Nearest to except: finite, altitudes, particular, helper, endeavoured, scenes, helaman, myocardium,
Nearest to report: occupants, costing, brooker, armas, adversaries, powering, hawkwind, people,
Nearest to professional: bronx, covalently, reappeared, inti, anthologies, alaska, described, midwestern,
Nearest to bbc: cruzi, galatia, football, grammaticus, tights, homilies, agonists, turbines,
==========================================================================================================
Average loss at step 100000: 3.359176
Nearest to when: if, before, while, although, where, after, though, because,
Nearest to people: children, students, players, individuals, men, adapting, women, americans,
Nearest to american: british, australian, german, french, italian, scottish, canadian, soccer,
Nearest to than: or, much, announcements, and, leningrad, spark, kish, while,
...
Nearest to except: especially, embodied, endeavoured, scenes, devonshire, every, indoors, example,
Nearest to report: sloop, woodbridge, costing, pit, occupants, atheism, jannaeus, uns,
Nearest to professional: anthologies, major, cumings, inti, reset, hollow, copyrighted, covalently,
Nearest to bbc: paper, galatia, fliers, flavia, earth, manufacturing, icosahedron, grammaticus,
==========================================================================================================以上就是skip-gram模型的内容,下次将会翻译CBOW模型的内容~敬请期待~