mobilenet V3算法理解与代码解析
MobileNetV3是通过结合硬件感知网络架构搜索(NAS)和NetAdapt算法设计改进而来,这里不讨论网络自动搜索,我们详细解读mobilenetV3的网络结构和代码实现。
1.depth-wise convolution (DWconv)
深度可分离卷积与普通卷积的区别在于:DWconv是按深度(channel数)逐层卷积获得一个个新的feature map,但是这些新的feature map并没有空间信息,因为卷积的时候根本没有考虑空间。为了将空间信息重新注入feature map,DWconv利用1×1卷积将这些新的feature map重新组合,由反向BP重新获取空间信息。为了让大家更好的理解,我们从知乎R.JD的文章中截取图片进行讲解。

首先,标准卷积过程从图中可见,输入12×12×3经过5×5×3的卷积得到8×8×1的feature,然后存在256个5×5×3的卷积,所以自然得到8×8×256的feature map。

我们再来看看DWconv,首先DWconv先将原来的输入12×12×3拆分成12×12×1的单层,这个过程需要用的conv中group参数,后面我们在代码中介绍。然后将5×5×3的kernel也拆分成5×5×1,这样逐层进行卷积可以获得3个8×8×1的feature,可见这3个feature并不具备空间信息。这样的操作只能维持通道数,并不能增加丰富空间信息。

现在我们已经获取了3个8×8×1的feature,利用3个1×1×1的卷积,可以将feature融合一个8×8×1的新feature,这个新的feature具有原来的3层空间信息,当我们用256个1×1的卷积获也取256个8×8的feature时,也就得到我们图中的8×8×256的feature map,与标准卷积一样,DWconv也获取了相同规模的feature map,但过程是完全不同的。DWconv的操作减少了大量的计算与参数,同时它与标准卷积获取的信息量从理解上应该是差不多的。
下面,我们来看看这两种卷积的参数量与计算量。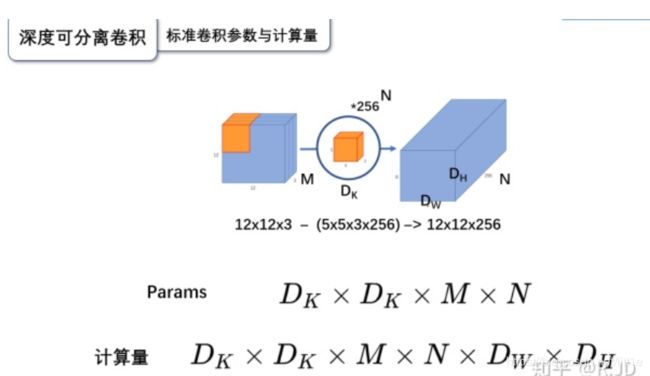
标准卷积,它的kernel size 是Dk×Dk×M,有N个这样的kernel。所以它的参数量是: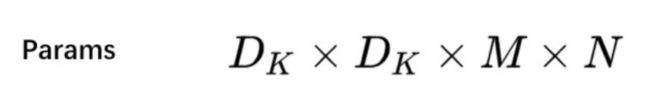
经过卷积后,获得了Dw×Dh×N的feature map,我们知道Dw×Dh中的每个像素都要经过Dk×Dk×M次相乘相加,所以标准卷积的计算量就是:


再来看看DWconv的参数与计算量。DWconv分为两部,第一步是拆分后获取单层feature,很显然,参数量是Dk×Dk×M,计算量是Dk×Dk×M×Dw×Dh。第二步是1×1升维,参数量,因为有N个1×1×M的卷积,所以就是M×N,计算量,M×N×Dw×Dh。

2.激活函数

这个激活函数是从swish改进而来,主要是为了简化swish的计算成本,并最大程度完成swish的功能。有实验来看是有一定的效果的。
3.SE结构

SE block的思想:从空间信息的权重出发,利用feature map经过一系列conv操作获取BP优化后的各层权重。过程:从H×W×C的feature map经过averagepool变成1×1×C的向量,这个操作过于简单粗暴,但从性能和速度来看却达到了平衡,再经过两次1×1的卷积后,获得1×1×C的权重。最后将原来的feature map逐层与该向量相乘,获得最终的结果。
4.block

从上图我们可以看到,mobilenet V3 block由以下组成:
1:膨胀,由1×1卷积将原来的feature map膨胀。
2:深度可分离卷积,由3×3卷积核逐层卷积每层特征,在经过1×1卷积融合程新的feature map。
3:se,获取新的feature map后,利用se的注意力机制获取空间权重来优化性能
4:residual,利用残差结构
代码理解
class Block(nn.Module):
'''expand + depthwise + pointwise'''
def __init__(self, kernel_size, in_size, expand_size, out_size, nolinear, semodule, stride):
super(Block, self).__init__()
self.stride = stride
self.se = semodule
self.conv1 = nn.Conv2d(in_size, expand_size, kernel_size=1, stride=1, padding=0, bias=False)
self.bn1 = nn.BatchNorm2d(expand_size)
self.nolinear1 = nolinear
self.conv2 = nn.Conv2d(expand_size, expand_size, kernel_size=kernel_size, stride=stride, padding=kernel_size//2, groups=expand_size, bias=False)
self.bn2 = nn.BatchNorm2d(expand_size)
self.nolinear2 = nolinear
self.conv3 = nn.Conv2d(expand_size, out_size, kernel_size=1, stride=1, padding=0, bias=False)
self.bn3 = nn.BatchNorm2d(out_size)
self.shortcut = nn.Sequential()
if stride == 1 and in_size != out_size:
self.shortcut = nn.Sequential(
nn.Conv2d(in_size, out_size, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(out_size),
)
def forward(self, x):
out = self.nolinear1(self.bn1(self.conv1(x)))
out = self.nolinear2(self.bn2(self.conv2(out)))
out = self.bn3(self.conv3(out))
if self.se != None:
out = self.se(out)
out = out + self.shortcut(x) if self.stride==1 else out
return out
我们主要根据上面讲的Block结构来分析代码如何实现的。self.conv1很显然是膨胀操作,将原来的feature map膨胀到指定通道数,self.nolinear1 = nolinear,nolinear是激活函数,是由形参传入可以是hswish与hsigmoid。self.conv2进行逐层卷积,大家看到group这个参数,group=膨胀通道数,意味着将H×W×C分成了C个H×W×1来分别进行卷积,这样才能实现深度可分离的操作。self.conv3实现空间重组,与此同时加入se机制。然后再stride=1的条件下做残差。