有趣的机器学习——莫烦教程学习记录
文章目录
- 1机器学习
- 1.1什么是机器学习?
- 2神经网络
- 2.1人工神经网络与生物神经网络
- 生物神经网络
- 人工神经网络
- 2.2神经网络(Neural Network)
- 2.3卷积神经网络CNN (Convolutional Neural Network)
- 2.4循环神经网络RNN (Recurrent Neural Network)
- 2.5LSTM RNN(long short term memory)
- 2.6自编码 (Autoencoder)
- 2.7生成对抗网络(GAN)
- 2.8神经网络的黑盒不黑
- 2.9神经网络 梯度下降
- 2.10 迁移学习 Transfer Learning
- 3 神经网络技巧
- 3.1检验神经网络(evaluation)
- 3.2特征标准化(feature normalization)
- 3.3 选择好特征(good feature)
- 3.4 激励函数(activation function)
- 3.5 过拟合 (Overfitting)
终于要开始学习机器学习了,之前偶尔看过,不成体系,更没有实践过。于是跟着莫烦机器学习的视频来学习,后面会有实战练习。因为想快速对各种方法了解一下,光看视频,走马观花一般,一遍下来,问问自己,好像什么也没记住,需要将学习到的知识在这里记录、梳理,并加深印象。如果要学习的话,还是直接看莫烦的教程就好了,我的总结也不够精简……主要是为了自己加深印象。
1机器学习
1.1什么是机器学习?
机器学习是一种计算机理论,是计算机科学家想让机器像人一样思考而发展出来的,包含概率论、统计学等数学知识。
-
机器学习的一些应用:Google now, Google photo,百度的图片识别都应用了机器学习。另外汇率预测、房价涨跌等一些应用也在探索和实践中发展起来。
-
机器学习的方法:即程序语言中所说的算法,算法有多种,目前所有方法大概分4-5类
-
监督学习(supervised learning):带标签的数据让他学习,比如图片标明是猫或狗,然后给他这些图片去学习。神经网络就是一种监督学习的方式。
-
非监督学习(unsupervised learning):没有标签的数据让他自己去发现数据背后的规律,比如只给猫和狗的图片,不告诉他哪些是猫、哪些是狗,让他把这个判断和分类,让他自己总结两种图片的不同。
给数据打标签是一件枯燥而低级的事情,但是估计分类效果更好,不然就不需要半监督学习了
-
半监督学习(semi-supervised learning):综合监督学习和非监督学习特征,主要是想用少量带标签的数据和大量不带标签的数据进行训练和分类。
-
强化学习(reinforcement learning):由规划机器人行为准则而来,让计算机在完全陌生的环境,自己学习成长,适应环境或者找到完成一项任务的方法途径。比如让机器人投篮,只给一个球,并告知命中得一分,然后他自己去适应调整,以得到高分。最初的表现可能会非常差,但是他经过总结、学习之后,最后会达到很高的命中率。AlphaGo即是用了这种方法。
-
遗传算法–和强化学习类似(genetic algorithm):通过模拟进化理论、淘汰弱者,来选择最优的设计或模型。比如让计算机学习玩超级玛丽,第一代可能很快就挂掉了,最后保存所有马里奥中最厉害的一个,第二代就基于他继续打怪,如此一代代下去,最终搞到一个高手高手高高手出来。
2神经网络
2.1人工神经网络与生物神经网络
神经网络将感官和反射器连接在一起,神经网络由神经元和突触组成。
生物神经网络
比如人的神经网络,一般是认为学习时会形成新的突触,由此形成了某些知识、记忆。比如学会了向父母讨要糖果,就会产生讨要糖果的突触,以后信号就会从先前形成的突触/路径传递到我们相应地器官——比如手,让手的动作变得有意义。
人工神经网络
人工神经网络的神经元和其间的连接都是固定的,不会产生新的连接。当我们想让计算机学习如何讨要糖果,就要给他大量的数据,看每次输入之后,手的动作是不是讨糖的动作,并依次来修改神经网络中的神经元强度,这种修改叫做误差反向传递。也可以看成将信号反向传回去,看神经元对于讨糖的动作有没有贡献,让他好好反思和修正,争取下一次有好的表现。
总结来说,人工神经网络是一个能让计算机处理和优化的数学模型,而生物神经网络则是通过刺激形成新的连接,让信号通过新的连接传递,并形成反馈。
2.2神经网络(Neural Network)
(一个详尽的介绍)
神经网络由大量人工神经元组成,他会在外界信息的基础上改变内部结构,是一种逐渐适应的过程。一般神经元由三个部分组成:输入层、隐藏层、输出层。
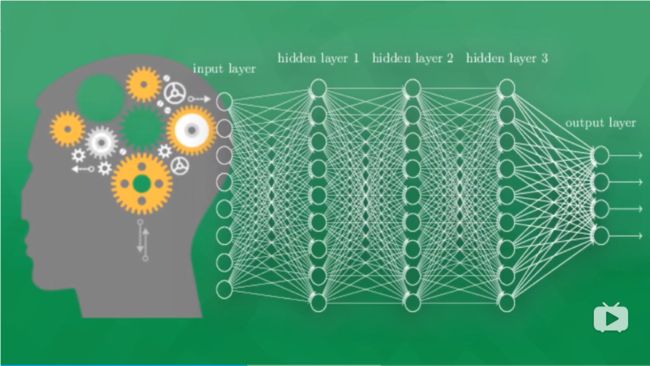
- 输入层:负责传递数据信息,比如一只猫的图片
- 输出层:是信息在网络中传递、中转、经分析和权衡形成输出的的结果。其结果就是计算机对事物的认知。
- 隐藏层:可以有多个层面,习惯上会用一层,他负责信息的加工处理,经过其加工之后,才能形成对数据的理解。
计算机处理的全是数据,信息是数据,最后处理的结果也是数据,但是计算机知道这些数据是有意义的。
那神经网络是怎么被训练的呢?比如前面说的监督学习那种,计算机对输入有一个输出,输出结果与标准答案的差别会反向传递回去,每一个神经元就向正确的方向上改动一点点,到下一次识别的时候,正确的几率就能提高一点点。经过很多多多多多多多多次的改进,积累起来,我们就向正确识别图片迈进了一大步。最后我们就能得到一个不错的模型,当你给他图片的时候,他就能有很大几率给出正确答案。
更进一步,改进是怎么完成的?实际上每个神经元有一个自己的刺激函数/激活函数,当你给模型看一只猫的图片,只有部分神经元被激励/激活,被激活的神经元传递的信息是计算机最为重视的信息,也就是对输出结果最有价值的信息。
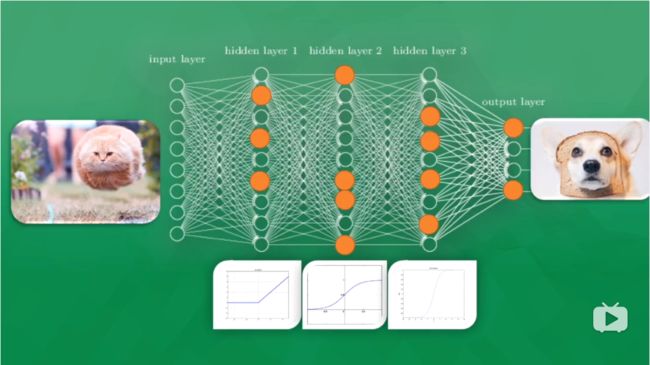
比如上面的一次判断,结果是一只狗,那么所有神经元的参数都会被调整,这时有些容易被激活的神经元就会变得迟钝,另外一些就会变得敏感起来,这就说明 所有神经元的参数正在被改变,变得对图片里真正重要的信息更为敏感。
2.3卷积神经网络CNN (Convolutional Neural Network)
卷积神经网络最常用的是计算机图片识别,当然也有用于视屏分析、自然语言处理等方面。
举一个识别图片的例子,在一个神经网络中有很多神经层,每一层中有多个神经元,神经元是蛇精网络识别事物的关键。当输入图片数据时,输入的实际是数据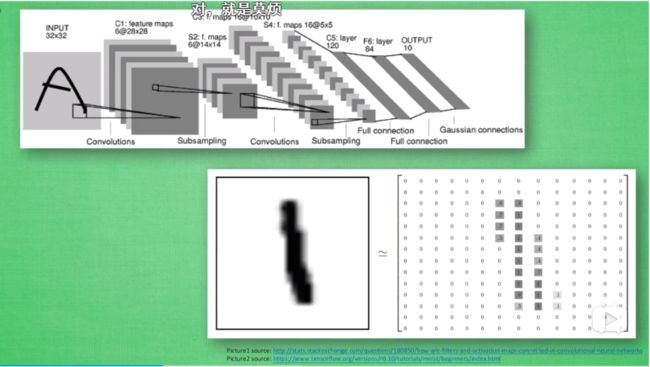
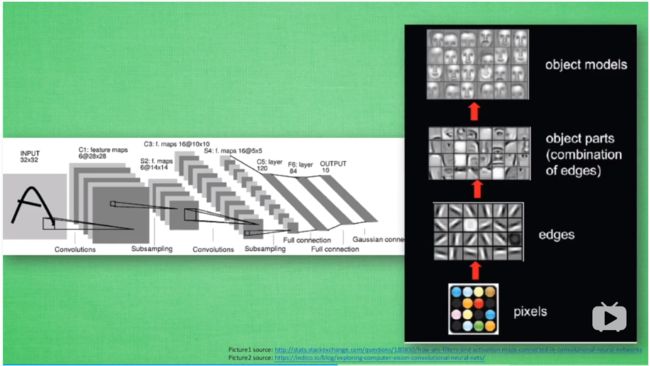
卷积意味着神经网络处理的不是每一个像素点,而是对每一小块像素区域做处理,这种做法加强了图片信息的连续性,使得神经网络可以看到一小块图形而非一个点。这种做法同时也加强了计算机对图片的理解,具体地说,卷积神经网络有一个批量过滤器,持续不断在图片上滚动,收集图片上的信息,每次收集来的信息都只是图片上的一小块像素区域,然后对收集来的信息做一个整理,整理出来的信息就有了一些实际上的呈现,比如此时神经网络可以看到一些边缘的信息。继之以同样的步骤,图片过滤器扫描这些边缘信息,神经网络用边缘信息总结出更高级的结构,比如总结出的信息可以画出眼睛、鼻子等等。再一次过滤后,从眼睛、鼻子等信息就能画出人脸了。最后,再把信息套入几层普通的全连接神经网络中进行分类,这样就能得出输入的图片被分入哪一类了。
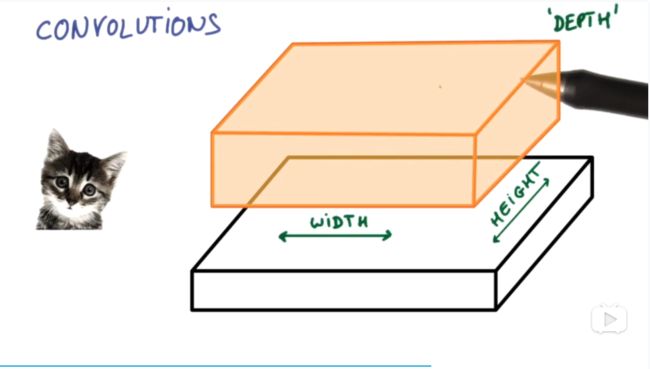
图片具体是如何被卷积的呢?一个图片有的数据如下:有长宽高三个维度,高度是颜色维度,长宽应该是各个像素点位置信息。过滤器(patch所指示的)在其中扫描,收集各个像素块的信息。
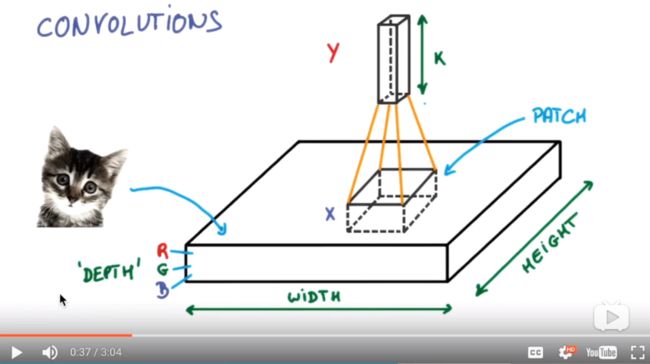
收集完所有信息后得到的值可以理解为是一个高度更高,长宽更小的图片:
继续扫描,长宽进一步压缩,高度进一步增高,我们对图片就有了更深的理解。将压缩、增高的信息嵌入普通分类器(classifier),就能得到计算机对该图片的分类
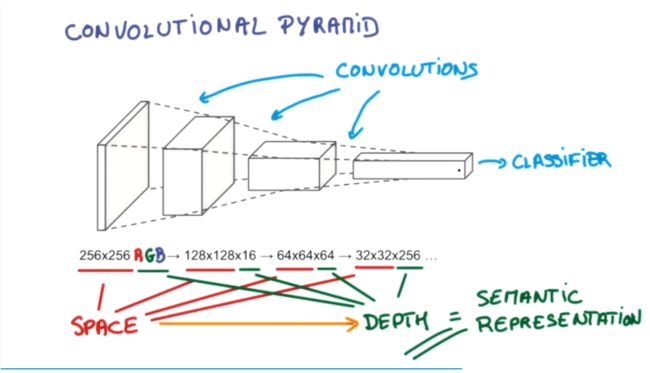
研究发现,每次压缩之后会丢失一部分图片信息。池化(pooling)就是用来解决这个问题,具体说是在卷积时不压缩长宽,压缩工作交给pooling来做,以此保留更多信息。这样做的效果是可以提高准确性。有了这些,我们就可以搭建一个卷积神经网络,一个典型的例子是:
image(输入)–>卷积–>池化–>卷积–>池化–>全连接层–>全连接层–>分类器

2.4循环神经网络RNN (Recurrent Neural Network)
(一个详尽的介绍)
上面所说的神经网络,我们可以理解为对于data0,有输出result0,若给了data1就有result,即是想强调神经网络对于一个输入就有一个输出。但是,如果data0和data1是有联系的怎么办呢?RNN就是解决这个问题的,怎么实现呢?
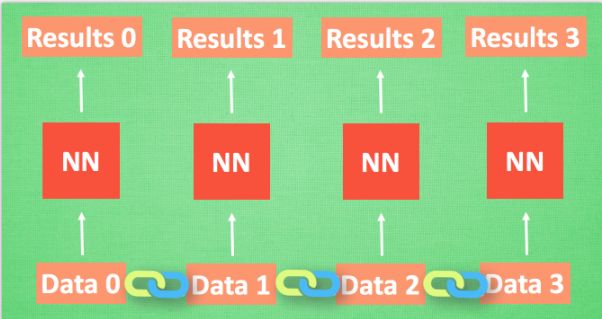
RNN:彼此联系的数据
RNN让神经网络——NN(neural network)对数据间的关联加以分析的方法: 最基本的方法就是记住之前发生的事,具体实现方法是在每次运算完之后产生一个对当前状态的描述,比如用data0算完得到result0时就产生一个状态state(0),当分析data1时就会产生result1,相应地也会产生state1。值得注意的是这里的result1是由state0和state1共同作用得到的。简单来说,RNN就是在计算下一个数据的时候,考虑了数据间的关联,将上一个数据状态记住,并让他参与下一个数据的计算。
RNN 的应用
RNN 的形式不单单这有这样一种, 他的结构形式很自由. 如果用于分类问题, 比如说一个人说了一句话, 这句话带的感情色彩是积极的还是消极的. 那我们就可以用只有最后一个时间点输出判断结果的RNN.
又或者这是图片描述 RNN, 我们只需要一个 X 来代替输入的图片, 然后生成对图片描述的一段话.
或者是语言翻译的 RNN, 给出一段英文, 然后再翻译成中文.
有了这些不同形式的 RNN, RNN 就变得强大了. 有很多有趣的 RNN 应用. 比如之前提到的, 让 RNN 描述照片. 让 RNN 写学术论文, 让 RNN 写程序脚本, 让 RNN 作曲. 我们一般人甚至都不能分辨这到底是不是机器写出来的.
好吧,到这里我有点怀疑这样学习是不是有效率,因为教程中讲的还是太简单了,有时候不是真的明白,但也确实让自己对各个概念有一个初步的了解。其实我的目标也是想快速看看这些方法到底在讲什么,而不是像一头扎在各种细节之中,因此还是继续吧,到时候具体练习各种方法的时候,应该会有更深入的理解。毕竟你不能一下就理解各种方法的本质和细节,可能当时确实懂了,但还是“看山是山,看水是水”的第一重境界,不能内化成你自己的东西,想要内化知识,必定要经过大量练习和体验,而这和快速了解各种方法是矛盾的。因此想要快速了解各种方法,就是不深入细节,有一个大体的认识就好了。
……………写随笔(我是指上面这一段小议论或者说思考、反思)这种东西就和自己写日记一样,好不啰嗦!不过我喜欢这种写作的过程,身心极度愉悦——单单这一点我觉得就很是值得了,要是还能真正得到一些有益的东西,那真是再好不过,“有益”这一点也不是一下就能看出来的,可能更多的是潜移默化的东西。
2.5LSTM RNN(long short term memory)
(一个详细介绍)
一般中文称之为长短期记忆网络,是针对普通RNN的弊端而提出的。
普通RNN的弊端:普通RNN的弊端就是会遗忘,比如有一个句子“我今天要做红烧排骨,首先要准备排骨,然后切葱,排骨焯水,炒排骨,最后红烧,这样红烧排骨就出炉啦”(我胡编这么长的,我也不晓得怎么做)。当你问RNN这个长句子说我们要做什么菜,他可能给出结果是“椒麻牛蛙”。判断错误的话,RNN就要学习句子与红烧排骨之间的关系,具体怎么学习呢?
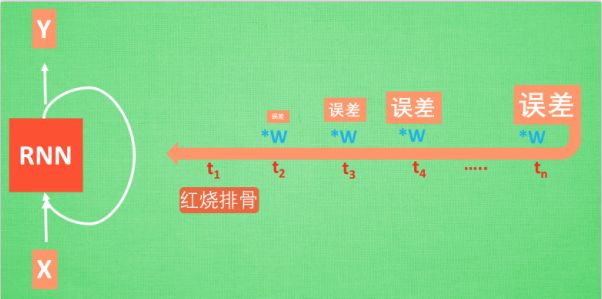
梯度消失/梯度弥散
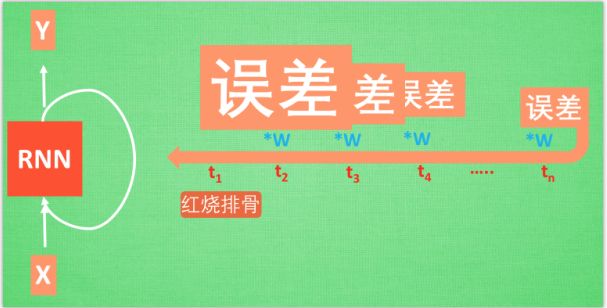
梯度爆炸
在RNN中红烧排骨这一信息源要经过长途跋涉才会到达最后一个时间点。然后我们得到误差,误差在反向传递的时候每一步都会乘以一个参数w,这样如果w<1,wn就会迅速衰减——梯度消失/梯度弥散(gradient vanishing),如果w>1,wn就会呈现出指数爆炸般的增大——梯度爆炸(gradient exploding)
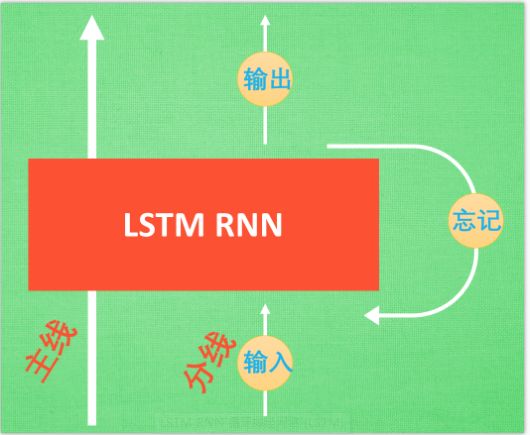
LSTM
LSTM就是为了解决上述问题:LSTM与普通RNN相比多了三个控制器:输入控制、输出控制、忘记控制。我们把上面的长句想象成一个故事,故事发展有一个主线和分线两个剧情。如果分线剧情对剧终结果很重要,分线剧情就会按照分线剧情重要程度将剧情写入主线。如果分线剧情的发展改变了我们对主线剧情的猜测,忘记控制就会发挥作用,将之前的主线剧情忘掉,按比例替换成现在的新剧情。最后的输出控制会根据当前的主线剧情和分线剧情来判断要输出什么结果 。基于此三者,LSTM能够带来更好地结果。
2.6自编码 (Autoencoder)
一个详细介绍
自编码在做什么?简单的理解就是自编码在学习怎么将数据进行压缩。比如一张高清图片,可能信息量达到上千万,让神经网络在这样大的信息量下学习非常吃力,自编码能够帮助我们缩减一下信息量,但是保留图片的主要信息,当我们需要的时候可以解压得到和原来差不多的图片。
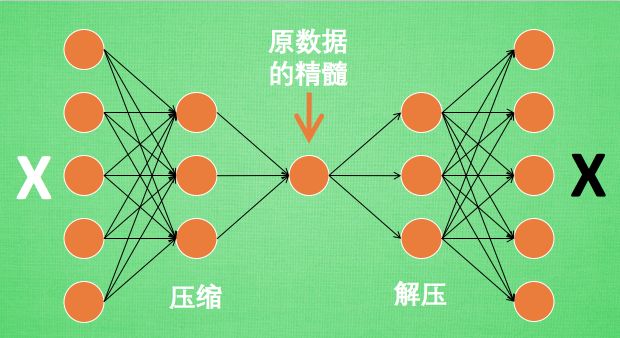
自编码压缩数据
所以自编码在做的事情就是压缩数据,自编码学习时通过将原图和解压后的图片进行比较,求出预测误差,进行反向传递 ,提升自编码的可靠性。由于只用到了原图X,而并没有原图的标签,所以自编码算是一种非监督学习。实际我们正式使用自编码这个网络来压缩数据的时候,只需要压缩那一步就行了,不需要解压缩,解压缩只在训练过程中才使用。
2.7生成对抗网络(GAN)
一个详细介绍
前述网络都是判别模型,其本质是将样本的特征向量映射成对应的label。而生成对抗网络是想让我们根据随机的数据,创造出更好地作品。生成模型由于需要大量的先验知识去对真实世界进行建模。
GANs的实现方法是让DD和GG进行博弈,训练过程中通过相互竞争让这两个模型同时得到增强。由于判别模型DD的存在,使得 GG 在没有大量先验知识以及先验分布的前提下也能很好的去学习逼近真实数据,并最终让模型生成的数据达到以假乱真的效果(即DD无法区分GG生成的图片与真实图片,从而GG和DD达到某种纳什均衡)——这段话出自本节开头的链接。
GAN主要有两个东西:1:Generator——生成器,用于生成数据,2:Discriminator——鉴别器,用于判别Generator产生的数据怎么样,并将结果反馈给Generator,这样generator会学着去逼近生成好的数据。
下面是一个应用的例子,你简单画两笔,然后网络根据想象帮你生成一个好的作品:

生成画作
2.8神经网络的黑盒不黑
人工神经网络是是一连串神经层所组成的把输入进行加工再输出的的系统,中间的加工过程就是我们所说的黑盒。一般我们降神经网络分为三层:输入层、黑盒、输出层。黑盒中所发生的事情就是将数据进行特征转化,这种转化可以让计算机提取到有用信息。比如用三个信息来表示手写数字的所有像素点,经过黑盒的特征转化可以得到手写数字图片的三个信息。我们在三维空间中展示这三个信息,在三维空间中我们可以看到计算机将三个信息分了类,表示同一个数字的三个信息分为同一类,如果有一个手写数字,他的三个信息落在了1所在的区域,则判定该数字是1。
有时候代表特征可能远不止三个,人类可能难以理解,但计算机会理解这些特征的意思。代表特征的这种理解方式实际上很有用,比如迁移学习。迁移学习就是说我们实际上还是用的同一个网络,但是我们要做的却是另一件事。比如讲输出层从图片的数字信息,变为判断图片的价值信息,只需将输出层换一下,让他学着提取些不同的信息,但是网络却是一样的。

迁移学习
2.9神经网络 梯度下降
首先,优化能力是人类历史上的重大突破,解决了很多实际生活中的问题。最优化问题的方法有很多,比如说牛顿法、最小二乘法、梯度下降法等等。神经网络的梯度下降就是其中的一个分支,梯度下降里的梯度实际上就是大学里所提到的求导、求微分。
初学神经网络的时候,我们会遇到一个误差方程:

误差方程
在数值预测中,我们常用平方差来代替,如上图所示。可以看出误差方程最小的地方,实际上就是曲线的最低点。但此时的蓝点并不知道,他只知道梯度线(切线)为自己指出了一个下降的方向。于是就沿着切线下降一点点,于是又出现一个新的切向,再下降一点点,如此下去,直到梯度线已经躺平,这时就找到了W的最理想的值。简言之,就是找到梯度线躺平的点,但是神经网络中的梯度下降并非如此简单。一是我们的曲线可能不止一个W(即可能是2维及以上的数据)
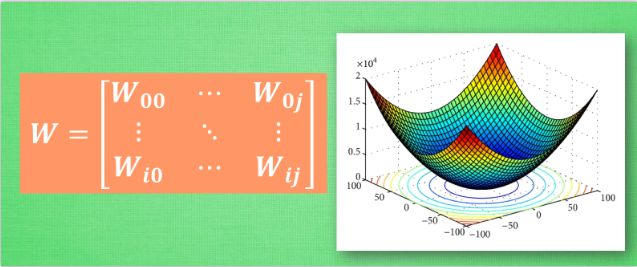
W不止一个
二是误差曲线并不总是如以上两幅图般如此优雅,曲线可能有多个能是梯度线‘躺平’的点。这样当你得到‘最优’的时候,可能并不是全局最优(黄饼所在的地方)的,而是一个局部最优(蓝点所在的地方)。全局最优固然好,但是很多时候我们只能得到一个局部最优解,这无可避免。但是不必过度担心,神经网络也能让你的局部最优足够优秀,达到足以解决你问题的程度。
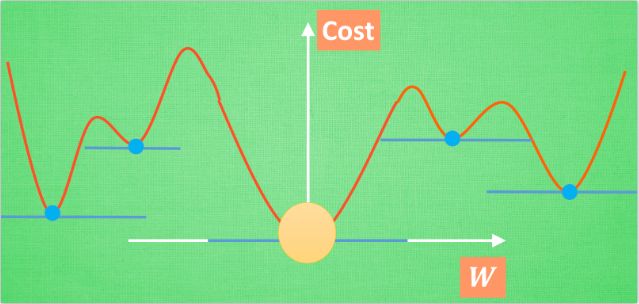
‘不优雅’的曲线
2.10 迁移学习 Transfer Learning
神经网络发展到如今,已经是可以拥有千千万万个神经元的网络了,这和计算机硬件,特别是GPU的发展是离不开的。因了这样强大的算力,我们可以将神经网络设计得非常复杂,可以从最初的基层发展到很多层层层层层层层层层。可是不是所有人都有如此大算力,也有时面对类似的问题时我们希望能够借鉴已有资源。
比如我有一个神经网络,经过训练已经可以识别出男人、女人……。这就是说该网络对图片信息已经有了一定的理解能力,这些理解能力以参数的形式存放在每一个神经节点中。当面临新任务,比如预测图片中实物的价值的时候,我们搭建网络从头训练可能需要花费不少时间。而先前的网络因为对图片有一定的理解能力,只是输出层是给出图片的分类结果——这不是我们想要的,于是我们可以将输出层换掉,接着只训练新的输出层,而前面对图片的理解力保持不变。这样因为前面网络的参数不需要训练,而节省了很多时间。
迁移学习并不总是好的,因为我们固定了前面网络的理解力,当迁移前后的数据差别很大,这时前面网络可能对新图片的理解能力就很差了。
上面是一般的迁移学习玩法,此外还有多任务学习等。比如翻译语言,当在某些语言上训练出对语言的理解模型,可将该模型迁移至另外语言上训练。该模型实际上等于将其他语言转化成自己能理解的语言,之后再将自己理解的语言转化成另一种语言,起到一个翻译中转站的作用。
3 神经网络技巧
3.1检验神经网络(evaluation)
有时神经网络可能出现学习效率不高、学到的规律不好等问题。这些问题可能产生自数据问题、学习效率等参数问题等。我们改善或避免此类问题就是通过检验和评价神经网络。通常的做法是把数据分为两部分:训练数据和测试数据。我们评价神经网络就是基于测试数据。当我们用训练数据训练出一个模型,之后就可以用测试数据来评价他。我们通常用误差曲线来展示我们神经网络训练的效果,其他的还有精确度曲线、测量回归问题精度的R2分数、不均衡数据的F1分数等。
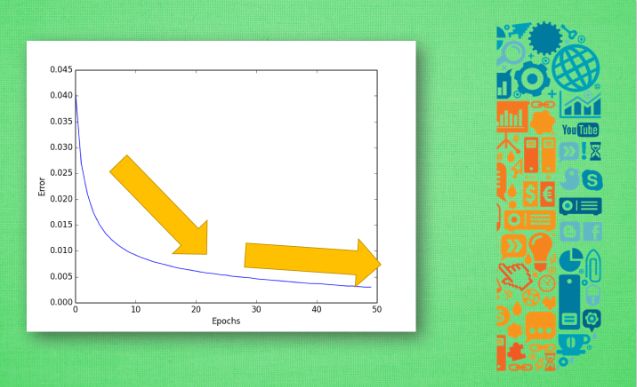
误差曲线
有时候训练出来的结果误差很小,但用测试数据来验证时却误差较大。这就说明我们的模型对训练数据太过依赖,而对测试数据却不能随机应变,这种问题称之为过拟合。解决过拟合的方法有l1、l2正规化,dropout方法等。
交叉验证:神经网络参数很多,交叉验证可以帮助我们确定怎样的参数可以更好地解决我们的问题。交叉验证不仅可以用于神经网络调参,也可用于其他机器学习方法调参。一个调参的例子:比如下面是我们想知道的误差值,横坐标是需要测试的某一参数,假设此参数是神经网络的层数。层数越多,就要消耗越多的时间和资源。我们只需要找到能符合我们目标的参数就可以了,比如说误差不超过0.005,那我们就只要30层结构的神经网络就好了。
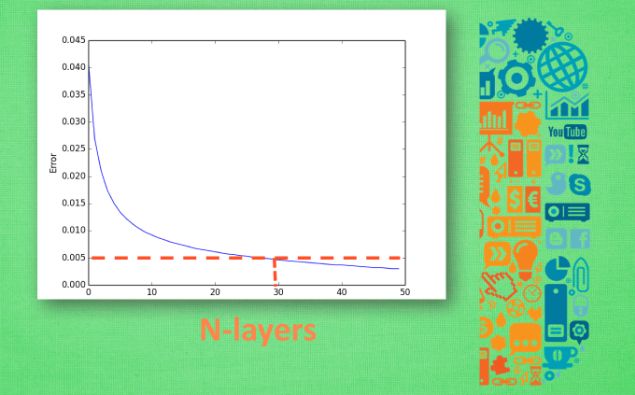
交叉验证调参
3.2特征标准化(feature normalization)
一个详细讲解
特征标准化可以加快机器学习的学习速度, 还可以避免机器学习学得特扭曲。比如下面是房价预测,假设我们只用三个特征来预测房价:离市中心距离、楼层、面积。当我们用神经网络来训练的时候,主要就是训练如下图所示三个参数:a,b,c。从数值上来看,面积的数值很大,而其他两个特征的数值相对较小。因此c只要稍微变化一点,对房价的预测结果影响会非常大,而a,b的变化则不会如此。这样的差别会导致工作效率问题。解决的方法就是特征标准化(其实就类似于归一化处理),一般有两种方法:1、min max normalization——把所有数据缩放到一个区间,比如[0,1]or[-1,1];2、standard deviation normalization——将所有特征数据缩放成 平均值为0, 方差为1。
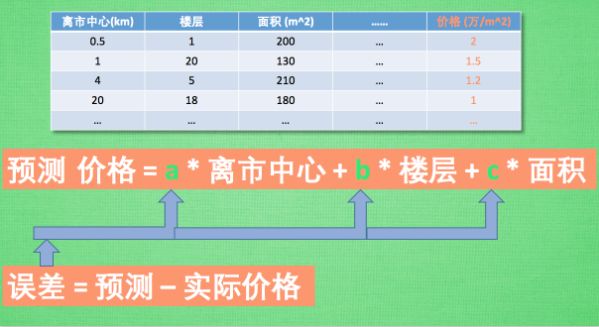
房价预测
3.3 选择好特征(good feature)
什么是好的特征呢?好的特征应该是能够让我们计算就能快速、方便而又正确地分类数据的特征。选择好的特征就是把不好的特征去掉,主要有三类:
1无意义的信息:
比如:要区分博士生和研究生,身高这个特征就没用;要区分男人和女人,眼睛颜色这个特征就没用。
2重复的信息:
比如:1min和60s两个数据表示的是同一个量,我们可以只保留其中一个
3复杂的信息
比如要预测从A点到B点的时间,有两个参数来表示A和B地理位置的信息,一个是AB的距离,另一个是A、B的经纬度,这时经纬度这个信息处理起来就相对复杂。
3.4 激励函数(activation function)
一般来说我们倾向于用一个线性函数来解决问题,但是很多问题都不是简单的线性问题。激励函数就是将这个线性函数给“掰弯”,以使函数更好地符合实际情况。
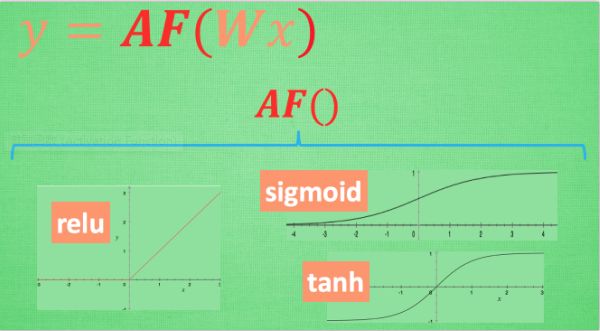
激励函数
3.5 过拟合 (Overfitting)
过拟合的一个形象例子:就是一个人过于自信,达到了自负的程度,坏处就是在一个小圈子里表现非凡,但在大圈子里却出处碰壁。
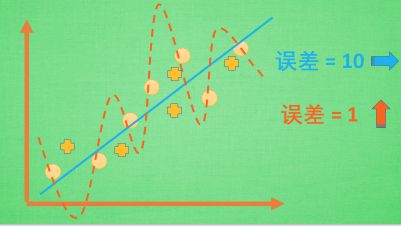
过拟合
比如在上图中,有圆圈所表示的数据点,我们一般会用直线来拟合,误差结果为10;但是机器学习觉得误差太大,用图示虚线来拟合,误差将至1。但是当新数据——‘+’所表示的点——来了之后,我们的直线拟合误差为也许依然是10,但曲线拟合的结果,误差可能是15。也就是说过拟合的后果就是不能很好地表达除了训练数据以外的数据。
解决方法:
1增加数据量:数据多了就更有代表性了
2运用正规化

正规化
L1, l2 regularization等等, 这些方法适用于大多数的机器学习, 包括神经网络。这些方法简单来说就是W越大就给他越大的惩罚。他们的做法大同小异, 简化机器学习的关键公式为 y=Wx,其中W为机器需要学习到的各种参数. 在过拟合中, W 的值往往变化得特别大或特别小. 为了不让W变化太大, 我们在计算误差cost上做些手脚. 原始的 计算误差cost 是这样计算, cost = 预测值-真实值的平方=(Wx-real y)2. 如果 W 变得太大, 我们就让 cost 也跟着变大, 变成一种惩罚机制. 所以我们把 W 自己考虑进来. 这里 abs 是绝对值. 这一种形式的 正规化, 叫做 l1 正规化. L2 正规化和 l1 类似, 只是绝对值换成了平方. 其他的l3, l4 也都是换成了立方和4次方等等. 形式类似. 用这些方法,我们就能保证让学出来的线条不会过于扭曲.