A SIMPLE NEURAL ATTENTIVE META-LEARNER
数据集
Omniglot
- 包含50个字母表的1623个手写字符,每个字符包含20个样本
- 先调整尺寸到28x28,之后通过多次旋转90度的方式增加字符的种类,一共6492类
- 划分
- 训练集:82240项 4112类
- 验证集:13760项 688类
- 测试集:33840项 1692类
Mini-ImageNet
- 从ImageNet中随机选取100个类,每类包含600个样本
- 将尺寸缩放到84x84
- 包含
- 训练集:64类
- 验证集:16类
- 测试集:20类
数据准备
每个iteration包含多个batch,也就是多个eposide;每个eposide包含随机的classes_per_it个类别,每个类别包含随机选择的sample_per_class个样本组成support set,query set由这些类中的一个随机类的一个随机样本组成。由于这些样本是作为一个序列输入到模型中的,所以最后一个样本即为query set,也就是要预测标签的样本。输入时,将一个batch中的所有eposide的样本拼接起来一起输入。
模型
将图像输入到时序卷积网络前,先要对图像做特征提取
特征提取
- Omniglot:使用和PrototpicalNet相同的结构
- Mini-ImageNet:在PrototpicalNet中,使用的是和Omniglot相同的结构,通道数减少到32,但是这样浅层的特征提取网络没有充分的利用SNAIL的容量,所以使用了ResNet进行特征提取

[ 84 , 84 , 3 ] → [ 42 , 42 , 64 ] → [ 21 , 21 , 96 ] → [ 10 , 10 , 128 ] → [ 5 , 5 , 256 ] → [ 5 , 5 , 2048 ] → [ 1 , 1 , 2048 ] → [ 1 , 1 , 384 ] [84,84,3]\rightarrow[42,42,64]\rightarrow[21,21,96]\rightarrow[10,10,128]\rightarrow[5,5,256]\rightarrow[5,5,2048]\rightarrow[1,1,2048]\rightarrow[1,1,384] [84,84,3]→[42,42,64]→[21,21,96]→[10,10,128]→[5,5,256]→[5,5,2048]→[1,1,2048]→[1,1,384]
时序卷积
- 时序卷积是通过在时间维度上膨胀的一维卷积生成时序数据的结构,如下图所示。这种时序卷积是因果的,所以在下一个时间节点生成的值只会被之前时间节点的信息影响,而不受未来信息的影响。相比较于传统的RNN,它提供了一种更直接,更高带宽的方式来获取过去的信息。但是,为了处理更长的序列,膨胀率通常是指数级增长的,所以需要的卷积层数和序列长度呈对数关系。因此,只能对很久之前的信息进行粗略的访问,有限的容量和位置依赖性对于元学习方法是不利的,不能充分利用大量的先前的经验。

class CasualConv1d(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size,
stride=1, dilation=1, groups=1, bias=True):
super(CasualConv1d, self).__init__()
self.dilation = dilation
padding = dilation * (kernel_size - 1)
self.conv1d = nn.Conv1d(in_channels, out_channels, kernel_size, stride,
padding, dilation, groups, bias)
def forward(self, input):
# Takes something of shape (N, in_channels, T),
# returns (N, out_channels, T)
out = self.conv1d(input)
return out[:, :, :-self.dilation] #
-
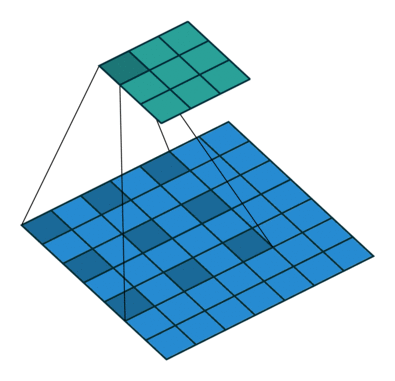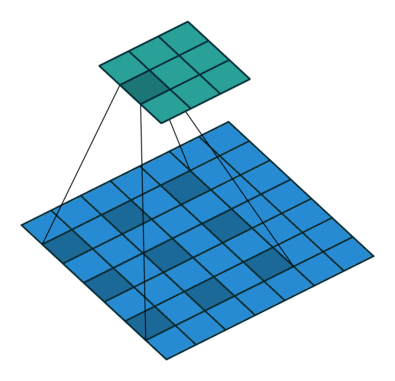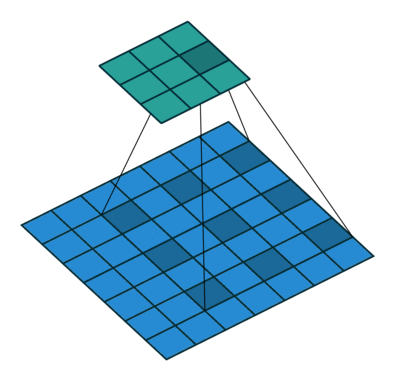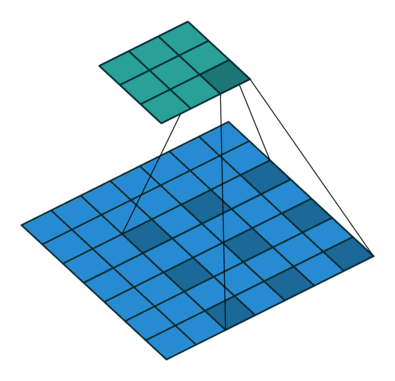
-
dilation为膨胀率(如上图所示,也就是卷积核元素之间的距离),T为要处理的序列长度,卷积核大小为2
class DenseBlock(nn.Module):
def __init__(self, in_channels, dilation, filters, kernel_size=2):
super(DenseBlock, self).__init__()
self.casualconv1 = CasualConv1d(in_channels, filters, kernel_size, dilation=dilation)
self.casualconv2 = CasualConv1d(in_channels, filters, kernel_size, dilation=dilation)
def forward(self, input):
# input is dimensions (N, in_channels, T)
xf = self.casualconv1(input)
xg = self.casualconv2(input)
activations = F.tanh(xf) * F.sigmoid(xg) # shape: (N, filters, T)
return torch.cat((input, activations), dim=1)

- 为了提高模型的效果,作者使用了残差连接和稠密连接。一个denseblock包含一个膨胀率为R卷积核数为D的一维因果卷积,使用了geted的激活函数,最后将输出与输入进行拼接。
class TCBlock(nn.Module):
def __init__(self, in_channels, seq_length, filters):
super(TCBlock, self).__init__()
self.dense_blocks = nn.ModuleList([DenseBlock(in_channels + i * filters, 2 ** (i+1), filters) for i in range(int(math.ceil(math.log(seq_length))))])
def forward(self, input):
# input is dimensions (N, T, in_channels)
input = torch.transpose(input, 1, 2)
for block in self.dense_blocks:
input = block(input)
return torch.transpose(input, 1, 2)
- 整个的时序卷积网络是由一系列的denseblock组成,每个denseblock膨胀率呈指数增加,直到感受野包含整个序列。
注意力模块
soft attention可以让模型在可能的无限大的上下文中精确的定位信息,把上下文信息当做无序的键值对,通过内容对其进行查找。
class AttentionBlock(nn.Module):
def __init__(self, in_channels, key_size, value_size):
super(AttentionBlock, self).__init__()
self.linear_query = nn.Linear(in_channels, key_size)
self.linear_keys = nn.Linear(in_channels, key_size)
self.linear_values = nn.Linear(in_channels, value_size)
self.sqrt_key_size = math.sqrt(key_size)
def forward(self, input):
# input is dim (N, T, in_channels) where N is the batch_size, and T is
# the sequence length
mask = np.array([[1 if i>j else 0 for i in range(input.shape[1])] for j in range(input.shape[1])])
mask = torch.ByteTensor(mask).cuda()
#import pdb; pdb.set_trace()
keys = self.linear_keys(input) # shape: (N, T, key_size)
query = self.linear_query(input) # shape: (N, T, key_size)
values = self.linear_values(input) # shape: (N, T, value_size)
temp = torch.bmm(query, torch.transpose(keys, 1, 2)) # shape: (N, T, T)
temp.data.masked_fill_(mask, -float('inf'))
temp = F.softmax(temp / self.sqrt_key_size, dim=1) # shape: (N, T, T), broadcasting over any slice [:, x, :], each row of the matrix
temp = torch.bmm(temp, values) # shape: (N, T, value_size)
return torch.cat((input, temp), dim=2) # shape: (N, T, in_channels + value_size)

- 基于self attention,使用键值查询的方式对之前的信息进行访问,为了保证在特定的时间节点不能访问未来的键值对,在softmax之前加入了mask,把query与未来的key之间的匹配度设置为负无穷,最后将输出与输入进行拼接。
SNAIL

- 时序卷积可以在有限的上下文中提供高带宽的访问方式,attention可以在很大的上下文中精确地访问信息,所以将二者结合寄来就得到了SNAIL。在时序卷积产生的上下文中应用causal attention,可以使网络学习到挑出聚集到的哪些信息,以及如何更好地表示这些信息。SNAIL由两个卷积和attention交错组成。
- 对于N-way,K-shot的问题,输入序列的长度为N*K+1
- 由[192,1,28,28]-encoder->[192,64]-cat->[192,69]->[32,6,69]-AttentionBlock->[32,6,101]-TCBlock->[32,6,357]-AttentionBlock->[32,6,485]-TCBlock->[32,6,741]-AttentionBlock->[32,6,997]-FC->[32,6,5]组成
- 做完特征提取后,将标签与特征进行拼接后进行输入,query set的样本标签为全0的vector
- 标签采用独热码表示
- loss:采用交叉熵损失函数
训练
过程与PrototpicalNet相同
实验结果
| Model | 5-way 1-shot Acc. | 5-way 5-shot Acc. | 20-way 1-shot Acc. | 20-way 5-shot Acc. |
|---|---|---|---|---|
| Reference Paper | 99.07% | 99.78% | 97.64% | 99.36% |
| This repo | 98.31% | 99.26% | 93.75% | 97.88% |