3D重建模的初步了解
3D重建模的初步了解
相关学习资料如下:
cousera课程: https://www.coursera.org/learn/robotics-perception
youtube课程: https://www.youtube.com/watch?v=RDkwklFGMfo
Tutorial: https://www.cse.wustl.edu/~furukawa/papers/fnt_mvs.pdf
分清楚 3D 重建 vs. 3D 建模
这里一般指的是用多张2D图片加上额外的信息,进行重建 3D
@知乎问题:三维重建 3D reconstruction有哪些使用算法
以下为知乎中的相关回答
用一组图片来做3D reconstruction需要的算法: SFM(Structure from motion),也就是从时间系列的2D图像中推算3D信息。
使用这种方法的软件有: Pix4Dmapper, Autodesk 123D Catch, PhotoModeler, VisualSFM
大多数三维重建的数据源是RGB图像,或者RGBD这种带有图像深度信息的图像(用kinect之类的特殊特备拍出来的)。
SFM是最经典的三维重建方案:
1.特征提取(SIFT, SURF, FAST等一堆方法)
2.配准(主流是RANSAC和它的改进版)
3.全局优化bundle adjustment 用来估计相机参数
4.数据融合
SFM算法是一种基于各种收集到的无序图片进行三维重建的离线算法。在进行核心的算法structure-from-motion之前需要一些准备工作,挑选出合适的图片。
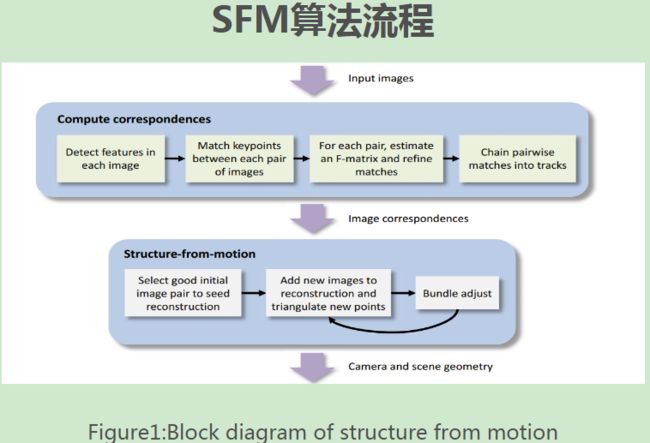
三维重构算法得看试用的是什么传感器,如果是双目相机,一般是极线几何加视觉特征配准的算法,优化就是bundle adjustment; 如果是单目相机,较早的有PTAM,DTAM,, 近几年就是SFM比较火,如果是Kinect之类的RGBD相机,比较好的就是微软的KinectFusion, PCL的开源KinFu,以及MIT加强版Kintinuous; 如果是用激光,一般就是SLAM做了。
基于rgb单目主要就是基于multiview geometry(SFM) ,比较经典的是DTAM和微软的monofusion, 缺点是没法做稍大场景的重建以及重建精度不高。
双目的话就认为是rgbd相机的重建,底层可以得到深度图的原理就是结构光,双目,激光,或者tof(结构光方法适合室内高精度重建,商业产品较多, sfm方法比结构光方法更方便,无需事先标定相机,但精度差些,很多无人机对大型建筑建模就是用的sfm方法)
@ 知乎-刘锐
参考文章 : https://zhuanlan.zhihu.com/p/30445504
3D重构算法可以描述为当给定某个物体或场景的一组照片时,在一些假定条件下,比如物体材料,观测视角和光照环境等,通过估计一个最相似的3D shape来解释这组照片。一个完整的3D重构流程通常包含以下几个步骤:
1. 收集场景图片
2. 计算每张图片的相机参数
3. 通过图组来重构场景的3D shape以及对应的相机参数
4. 有选择的重构场景的材料等

最核心步骤就是第三步: 3D shape的重构算法
常规的3D shape representation主要有四种: 深度图(depth), 点云(point cloud), 体素(voxel), 网格(mesh)
今年来也出现了很多基于deep learning的方法:
David Eigen NIPS2014: Depth Map Prediction from a Single Image using a Multi-Scale Deep Network
Fayao Liu CVPR2015 Deep Convolutional Neural Fields for Depth Estimation from a Single Image
这两篇论文都是利用CNN网络结构预测 a single image与其对应的depth map之间的关系。
但是depth image还不足以解释重构原始input的信息,它只能作为3D scene understanding的一个辅助信息。所以开始研究利用一组二维图来重构3D点云图或voxel以及mesh图。
基于deep learning的3D点云和mesh重构是较难以实施的,因为DL学习一个物体完整的架构需要大量数据的支持。然后传统的3D模型是由vertices和trangulation mesh组成的,因此不一样的data size造成了training的困难。所以后续大家都用voxelization(Voxel)的方法把所有CAD model转成binary voxel模式(有值为1, 空缺为0)这样保证了每个模型都是相同的大小。最近的一篇论文: Choy ECCV2016: 3D-R2N2:A Unified Approach for Single and Multi-view 3D Object Reconstruction
采用深度学习从2D图像到其对应的3D voxel模型的映射:首先利用一个标准的CNN结构对原始input image进行编码,然后用Deconv进行解码,最后用3D LSTM的每个单元重构output voxel.
3D voxel是三维的,它的resolution成指数增长,所以它的计算相对复杂,目前的工作主要采用32*32*3以下的分辨率以防止过多的占用内存。但是也使得最终重构的3D model分辨率并不高。所以科研道路道阻且长。
mesh和point cloud是不规则的几何数据形式,因此直接使用CNN是不可行的。但是可以考虑将3D mesh data转化成graphs形式,再对3D曲面上的2D参数进行卷积。具体有Spatial construction(Geodesic CNN)和Spectral construction(Spectral CNN)
基于point cloud的方法,看Hao Su的CVPR2017论文 PointNet: Deep learning on Point Sets for 3D Classification and Segmentation以及 A Point Set Generation Network for 3D Object Reconstruction from a Single Image.
基于mesh和point cloud的方法总的来讲数学东西多,而且细节回复上效果欠佳。不过可以考虑voxel来提高重构精度。
@ 知乎问题:计算机图形学与机器学习(深度学习)怎么结合起来?
以下为MSRA相关回答
随着深度学习尤其是卷积神经网络(CNN)这一利器在各领域里的卓越表现,如何将CNN运用到三维数据上成为计算机视觉和图形学一个焦点课题。
分析与处理三维形体是计算机图形学中的一个基本任务与研究方向。近年来随着三维数据获取的便捷和三维数据集的迅猛增长,这个研究方向也面临新的挑战和契机。一方面,在新的数据形势下,传统算法的一些前提假设不再成立,研发新型算法的需求迫在眉睫。另一方面,大数据的出现,可以使得传统的三维分析和机器学习更加有机地结合起来,从而帮助人们加深对三维世界的认知,有效地理解现实三维几何世界并构建虚拟数字世界。
“三维去噪”
由于Kinect设备的低精度,三维网格存在着大量的噪声。如图(b)

去噪问题本质上是求解一个病态的逆问题:在噪声的类型和程度未知、真实模型的几何特性未知的前提下,如果要把噪声从输入中完美剥离,必然需要引入各种假设来辅助求解。
真实噪声是与数据以及设备相关的,简单的噪声模型不可能刻画出真实的噪声。
忽略真实数据去研发一个放之四海而皆准的去噪算法是不可行的。噪声来自数据,我们应该从数据中探究其中的奥秘。我们的工作也体现了数据的威力.Siggraph Asia 2016发表的文章,Mesh Denoising via Cascaded Normal Regression
“形状空间与3D CNN”
三维形状在数字世界里可以有不同的表达,如三角网格、点云、体素、参数曲面、隐式曲面等。不同的表达和CNN也有着不同的结合方式。有的方法将网格参数化到二维空间,在二维空间编码几何特征,并利用CNN在二维定义域上类似图像空间进行卷积;有的将曲面局部处理成测地圆盘域并在其上编码几何信号,然后在圆盘上进行CNN卷积;也有的以三维空间的体素作为定义域,示性函数作为信号(即物体形状内部信号编码为1,外部为0)进行3D卷积,将CNN直接拓展到三维空间;还有一大类方法是利用空间投影将物体变为多个视图下的二维影像,然后当作图像来处理。在近年的视觉、机器学习、计算机图形学的会议上,如CVPR/ICCV/NIPS/SIGGRAPH,针对三维形状的深度学习网络已开始大放光彩。但这些方法各有利弊,对输入也各有不同的要求。
基于体素的3D CNN是图像空间CNN的自然推广,然而从二维推广到三维,CNN涉及的离散元素(2D是像素,3D是体素)个数是空间格点分辨率的三次方,即 。庞大的存储量和计算量让基于体素的3D CNN畏足于高分辨率,徘徊于 这样低分辨率的数据中,使得该方法在众多的三维学习任务中饮恨败北。提出基于八叉树的CNN O-CNN Siggraph2017上的文章 O-CNN: Octree-based Convolutional Neural Networks for 3D Shape Analysis

ToF是测飞行时间,Time of Flight, 最开始求取深度的,是激光雷达,但是成本很高,军用较多
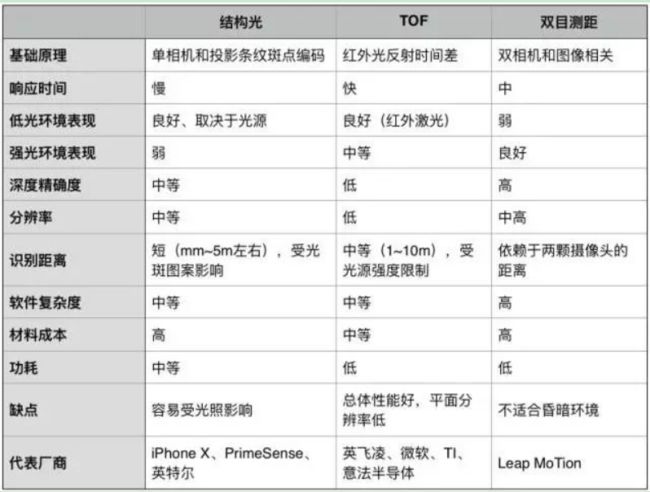
TOF是3D深度摄像技术中的一种方案。目前主流的3D深度摄像方案有三种: 结构光,TOF, 双目成像
双目测距成像因为效率低,算法难,精度差,容易受到环境因素干扰;TOF方案同样有精度缺陷,传感器体积小型化后对分辨率赢你选哪个很大。
应用前景:
百度目前在做基于深度学习的高精度导航模型构建, AR
无人机建筑模型重建
iphone X 3D摄像头
参考文章: https://zhuanlan.zhihu.com/p/29326039
3D视觉作为一项激动人心的新技术,早已经出现在微软Kinect、英特尔RealSense等消费级产品中。近几年,随着硬件端技术的不断进步,算法与软件层面的不断优化,3D深度视觉的精度和实用性得到大幅提升,使得“3D深度相机+手势/人脸识别”具备了大规模进入移动智能终端的基础。作为全球手机当之无愧的龙头,苹果率先大规模采用3D视觉技术,将彻底激活3D视觉市场,开启全新时代。
3D视觉技术不仅仅在识别精度方面大幅提升,更重要的是打开了更加广阔的人工智能应用空间。随着机器视觉、人工智能、人机交互等科学技术的发展,各种高智能机器人开始走进现实,3D视觉技术成为助力制造业实现“智能化”转型的好帮手。
大家耳熟能详的深度摄像头技术和应用有英特尔的RealSense、微软的 Kinect、苹果的 PrimeSense、以及谷歌的Project Tango等。不过可以看到这一技术的研究和开发多为国外公司,国内计算视觉方面的公司或创业团队屈指可数,技术上的壁垒依旧较大。
关于目前市场上的深度相机的技术方案主要有以下三种: 双目被动视觉、结构光、TOF。 双目被动视觉主要是利用两个光学摄像头,通过左右立体像对匹配后,再经过三角测量法来得到深度信息。此算法复杂度高,难度很大,处理芯片需要很高的计算性能,同时它也继承了普通RGB摄像头的缺点:在昏暗环境下以及特征不明显的情况下并不适用。
结构光的原理是通过红外激光发射相对随机但又固定的斑点图案,这些光斑打在物体上后,因为与摄像头距离不同,被摄像头捕捉到的位置也不尽相同。然后先计算拍到的图的斑点与标定的标准图案在不同位置的位移,引入摄像头位置、传感器大小等参数计算出物体与摄像头的距离。
微软在Kinect二代采用的是ToF的技术。ToF是Time of flight的简写,直译为飞行时间的意思。所谓飞行时间法3D成像,是通过给目标连续发送光脉冲,然后用传感器接收从物体返回的光,通过探测光脉冲的飞行(往返)时间来得到目标物距离。相比之下,结构光技术的优势是比ToF更加成熟,成本更低,更加适合用在手机等移动设备上。
深度摄像头是所有需要三维视觉设备的必需模块,有了它,设备就能够实时获取周围环境物体三维尺寸和深度信息,更全面的读懂世界。深度摄像头给室内导航与定位、避障、动作捕捉、三维扫描建模等应用提供了基础的技术支持,成为现今行业研究热点。如今iPhone X搭载3D深度摄像头势必会大力推动机器视觉领域的发展,助力机器人产业实现完美“智能化转型”