【Netty4.X】Netty源码分析之ByteBuf(七)
ByteBuf是一个缓冲区,用于和NIO通道进行交互。缓冲区本质上是一块可以写入数据,然后可以从中读取数据的内存。这块内存被包装成NIO Buffer对象,并提供了一组方法,用来方便的访问该块内存。每当你需要传输数据时,它必须包含一个缓冲区。虽然Java NIO 为我们提供了原生的多种缓冲区实现,但是使用起来相当复杂并且没有经过优化,有着以下缺点:
- 1、不能进行动态的增长或者收缩。如果写入的数据大于缓冲区capacity的时候,就会发生数组越界错误。
- 2、只有一个位置标识Position,只能通过flip或者rewind方法来对position进行修改来处理数据的存取位置,一不小心就可能会导致错误。
Netty提供了一个强大的缓冲区ByteBuf,帮助我们解决了以上问题。
一、ByteBuf的读写操作
当需要与远程进行交互时,需要以字节码发送/接收数据。
ByteBuf有2部分:一个用于读,一个用于写。我们可以按顺序的读取数据,并且可以跳到开始重新读一遍。所有的数据操作,我们只需要做的是调整读取数据索引和再次开始读操作。
在对象初始化时,readerIndex和writerIndex的值都是0,随着读写操作的进行,readerIndex和writerIndex都会增加,但是readerIndex不会超过writerIndex。当readerIndex大于0时,0-readerIndex之间的空间会被视为discardable(丢弃的空间),discardable会在调用discardReadBytes之后销毁,同时readerIndex会被重置为0。
* BEFORE discardReadBytes()
*
* +-------------------+------------------+------------------+
* | discardable bytes | readable bytes | writable bytes |
* +-------------------+------------------+------------------+
* | | | |
* 0 <= readerIndex <= writerIndex <= capacity
*
* AFTER discardReadBytes()
*
* +------------------+--------------------------------------+
* | readable bytes | writable bytes (got more space) |
* +------------------+--------------------------------------+
* | | |
* readerIndex (0) <= writerIndex (decreased) <= capacity readerIndex: 读指针,可读区域是[readerIndex,writerIndex)
writerIndex: 写指针,可写区域是[writerIndex,capacity)
discardable: 丢弃的读空间[0,readerIndex],在调用discardReadBytes后被释放。
二、ByteBuf源码分析
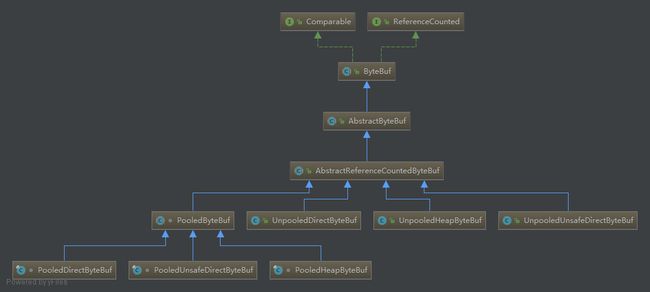
2.1 AbstractReferenceCountedByteBuf
自从Netty 4开始,对象的生命周期由它们的引用计数(reference counts)管理,而不是由垃圾收集器(garbage collector)管理了。ByteBuf是最值得注意的,它使用了引用计数来改进分配内存和释放内存的性能。
private static final AtomicIntegerFieldUpdater refCntUpdater;
private volatile int refCnt = 1;
@Override
public ByteBuf retain() {
for (;;) {
int refCnt = this.refCnt;
if (refCnt == 0) {
throw new IllegalReferenceCountException(0, 1);
}
if (refCnt == Integer.MAX_VALUE) {
throw new IllegalReferenceCountException(Integer.MAX_VALUE, 1);
}
if (refCntUpdater.compareAndSet(this, refCnt, refCnt + 1)) {
break;
}
}
return this;
}
public final boolean release() {
for (;;) {
int refCnt = this.refCnt;
if (refCnt == 0) {
throw new IllegalReferenceCountException(0, -1);
}
if (refCntUpdater.compareAndSet(this, refCnt, refCnt - 1)) {
if (refCnt == 1) {
deallocate();
return true;
}
return false;
}
}
}
refCntUpdater: refCntUpdater对refCnt进行原子更新
refCnt: 每个对象的初始计数为1,这里利用了voliate内存的可见性和CAS操作来保证它的安全性。
retain(): 可以通过调用retain()增加引用计数,前提是引用计数对象未被销毁
release(): 当你释放(release)引用计数对象时,它的引用计数减1.如果引用计数为1,这个引用计数对象会被释放(deallocate),并返回对象池
deallocate(): 回收ByteBuf
2.2 AbstractByteBuf
static final ResourceLeakDetector leakDetector = new ResourceLeakDetector(ByteBuf.class);
int readerIndex;
int writerIndex;
private int markedReaderIndex;
private int markedWriterIndex;
private int maxCapacity;
private SwappedByteBuf swappedBuf;
protected AbstractByteBuf(int maxCapacity) {
if (maxCapacity < 0) {
throw new IllegalArgumentException("maxCapacity: " + maxCapacity + " (expected: >= 0)");
}
this.maxCapacity = maxCapacity;
}
swappedBuf: 大端序列与小端序列的转换。这里有个大小端概念,从网上找了个比较好的例子来解释大小端,C,C++蛮多使用小端的,而我们JAVA默认使用大端。什么意思?比如我要发一个18,两个字节就是0x0012,对于小端模式,先发0x12后发0x00,也就是我们先收到12后收到00,对于java,TCP默认的是大端,即先发高位0x00,后发0x12,netty默认大端,即如果按照大端发送过来的数据,可直接转换成对应数值。
leakDetector: leakDetector是Netty用来解决内存泄漏的检测机制,这里使用了static final,表示所有继承AbstractByteBuf的类都将共享一个内存泄漏管理。
2.3 UnpooledHeapByteBuf
UnpooledHeapByteBuf是一个非线程池实现的在堆内存进行内存分配的字节缓冲区,在每次IO操作的都会去创建一个UnpooledHeapByteBuf对象,如此频繁地对内存进行分配或者释放会对性能造成影响。
private final ByteBufAllocator alloc;
private byte[] array;
private ByteBuffer tmpNioBuf;
public ByteBuf capacity(int newCapacity) {
ensureAccessible();
if (newCapacity < 0 || newCapacity > maxCapacity()) {
throw new IllegalArgumentException("newCapacity: " + newCapacity);
}
int oldCapacity = array.length;
if (newCapacity > oldCapacity) {
byte[] newArray = new byte[newCapacity];
System.arraycopy(array, 0, newArray, 0, array.length);
setArray(newArray);
} else if (newCapacity < oldCapacity) {
byte[] newArray = new byte[newCapacity];
int readerIndex = readerIndex();
if (readerIndex < newCapacity) {
int writerIndex = writerIndex();
if (writerIndex > newCapacity) {
writerIndex(writerIndex = newCapacity);
}
System.arraycopy(array, readerIndex, newArray, readerIndex, writerIndex - readerIndex);
} else {
setIndex(newCapacity, newCapacity);
}
setArray(newArray);
}
return this;
}
ByteBufAllocator: 用于内存分配
array: 字节数组作为缓冲区,用于存储字节数据
tmpNioBuf: 用来实现Netty ByteBuf 到Nio ByteBuffer的变换
ensureAccessible: 根据refCnt的值是否为零,判断引用计数对象是否被释放(零是释放)。
capacity:
只要newCapacity!=oldCapacity时,都会创建新的数组作为缓冲区,缓冲区大小是newCapacity。
如果newCapacity大于oldCapacity,调用arraycopy进行内存复制,将旧数据拷贝到新数组中,最后使用setArray进行数组替换。
如果newCapacity小于oldCapacity,首先查看readerIndex是否小于newCapacity。
- readerIndex < newCapacity: 继续对writerIndex和newCapacity作比较,如果writerIndex大于newCapacity的话,就将writerIndex设置为newCapacity,然后将当前可读的数据拷贝到新的数组中
- readerIndex > newCapacity: 没有新的可读数据要复制到新的字节数组缓冲区中,只需要把writerIndex跟readerIndex都更新为newCapacity。
最后调用setArray更换字节数组.
2.4 UnpooledDirectByteBuf
UnpooledDirectByteBuf是直接缓冲区,JVM不用将数据到堆中,提升了性能。但也有缺点,直接缓冲区在分配内存和释放内存时非常复杂,4.X之后Netty使用内存池解决了这样的问题。
private final ByteBufAllocator alloc;
private ByteBuffer buffer;
private ByteBuffer tmpNioBuf;
private int capacity;
private boolean doNotFree;
@Override
public ByteBuf capacity(int newCapacity) {
ensureAccessible();
if (newCapacity < 0 || newCapacity > maxCapacity()) {
throw new IllegalArgumentException("newCapacity: " + newCapacity);
}
int readerIndex = readerIndex();
int writerIndex = writerIndex();
int oldCapacity = capacity;
if (newCapacity > oldCapacity) {
//旧缓冲区存储空间不足时,新建一个缓存区,然后将旧缓存区的数据全部写入到新的缓存区,然后释放旧的缓存区。
ByteBuffer oldBuffer = buffer;
ByteBuffer newBuffer = allocateDirect(newCapacity);
oldBuffer.position(0).limit(oldBuffer.capacity());
newBuffer.position(0).limit(oldBuffer.capacity());
newBuffer.put(oldBuffer);
newBuffer.clear();
setByteBuffer(newBuffer);
} else if (newCapacity < oldCapacity) {
ByteBuffer oldBuffer = buffer;
ByteBuffer newBuffer = allocateDirect(newCapacity);
if (readerIndex < newCapacity) {
if (writerIndex > newCapacity) {
writerIndex(writerIndex = newCapacity);
}
oldBuffer.position(readerIndex).limit(writerIndex);
newBuffer.position(readerIndex).limit(writerIndex);
newBuffer.put(oldBuffer);
newBuffer.clear();
} else {
setIndex(newCapacity, newCapacity);
}
setByteBuffer(newBuffer);
}
return this;
}
private void setByteBuffer(ByteBuffer buffer) {
ByteBuffer oldBuffer = this.buffer;
if (oldBuffer != null) {
if (doNotFree) {
doNotFree = false;
} else {
freeDirect(oldBuffer);
}
}
this.buffer = buffer;
tmpNioBuf = null;
capacity = buffer.remaining();
}allocateDirect: 在堆外创建一个大小为newCapacity的新缓冲区
newCapacity > oldCapacity: 将旧缓冲区的数据全部写入到新的缓存区并且释放旧的缓冲区
newCapacity < oldCapacity : 压缩缓冲区,如果readerIndex > newCapacity,无需将旧的缓存区内容写入到新的缓存区中。否则需要将readerIndex至 Math.min(writerIndex, newCapacity)的内容写入到新的缓存.
position:
- 当你写数据到Buffer中时,position表示当前的位置。初始的position值为0.当一个byte、long等数据写到Buffer后, position会向前移动到下一个可插入数据的Buffer单元。position最大可为capacity – 1.
- 当读取数据时,也是从某个特定位置读。当将Buffer从写模式切换到读模式,position会被重置为0. 当从Buffer的position处读取数据时,position向前移动到下一个可读的位置。
limit:
- 在写模式下,Buffer的limit表示你最多能往Buffer里写多少数据。写模式下,limit等于Buffer的capacity。
- 当切换Buffer到读模式时, limit表示你最多能读到多少数据。因此,当切换Buffer到读模式时,limit会被设置成写模式下的position值。换句话说,你能读到之前写入的所有数据(limit被设置成已写数据的数量,这个值在写模式下就是position)
setByteBuffer: 释放旧的缓冲区然后将buffer指向新的缓冲区
2.5 PooledByteBuf
在Netty4之后加入内存池管理PoolChunk,负责管理内存的分配和回收。通过内存池管理比之前的ByteBuf性能要好很多。官方说提供了以下优势:
- 频繁分配、释放buffer时减少了GC压力;
- 在初始化新buffer时减少内存带宽消耗(初始化时不可避免的要给buffer数组赋初始值);
- 及时的释放direct buffer。
有篇文章对使用内存池和不使用内存池性能作了分析,大家可以看下:Netty4底层用对象池和不用对象池实践优化
abstract class PooledByteBuf<T> extends AbstractReferenceCountedByteBuf {
protected PoolChunk chunk;
} final class PoolChunk<T> {
final PoolArena arena;
private final PoolSubpage[] subpages;
PoolChunkList parent;
}
PooledByteBuf主要由以下几个部分组成:
- PoolChunk:负责内存分配和回收
- PoolArena:由多个Chunk组成的,而每个Chunk则由多个Page组成
- PoolSubpage:用于分配小于8k的内存,负责把poolChunk的一个page节点8k内存划分成更小的内存段,通过对每个内存段的标记与清理标记进行内存的分配与释放。
- PoolChunkList:负责管理多个chunk的生命周期
2.6 PooledDirectByteBuf
private static final Recycler RECYCLER = new Recycler() {
@Override
protected PooledDirectByteBuf newObject(Handle handle) {
return new PooledDirectByteBuf(handle, 0);
}
};
static PooledDirectByteBuf newInstance(int maxCapacity) {
PooledDirectByteBuf buf = RECYCLER.get();
buf.setRefCnt(1);
buf.maxCapacity(maxCapacity);
return buf;
} PooledDirectByteBuf是直接缓冲区,在堆之外直接分配内存。其继承自PooledByteBuf,由于PooledByteBuf是基于内存池实现,所以每次创建字节缓冲区的时候不是直接new,而是从内存池中去获取.
参考书籍:Netty in Action