机器学习之EM算法
EM(Expectation-Maximization)算法是一种启发式的迭代方法,用于含有隐变量Z(latent variable)的概率模型参数Θ的最大似然/最大后验估计。由于含有隐变量不能直接使用MLE、MAP,因此用隐变量的期望来代替它,再通过最大化对数边际似然(marginal likelihood)来逐步逼近原函数的极大值,EM的优点是简单、稳定,但容易陷入局部最优解。算法步骤如下:
以初始值Θ0为起点,迭代执行下面两步直至收敛:
E步 → 基于Θt推断隐变量Z的期望,记为Zt;
M步 → 基于已观测变量X和Zt对参数Θt进行MLE或MAP,记为Θt+1;
一、相关概念
1、MAP、MLE
MAP(Maximum A Posteriori estimation)和MLE一样,都是通过样本估计参数θ的值。在MLE中假设先验概率是等值的,是求使似然函数P(x|θ)最大时参数θ的值;而MAP则是求θ使P(x|θ)P(θ)的值最大,这就要求θ值不仅仅是让似然函数最大,同时要求θ本身的先验概率也要比较大,可看作是规则化的MLE(类似正则化中加惩罚项的思想)。

尽管MAP与贝叶斯公式很像,但通常并不认为它是一种贝叶斯方法,因为MAP是点估计,而贝叶斯是使用这些分布来总结数据、得到推论,试图得到后验均值/中值/interval,而不是后验模。
2、Jensen不等式
如果f为凸函数(f的二次导数≥0),那么存在下列公式:
![]()
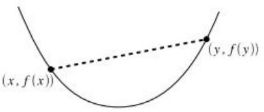
若θ1,θ2,...,θn≥0,且θ1+θ2+...+θn=1,则有:
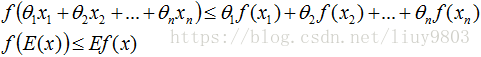
如果f为凹函数,则不等式反号。
二、EM算法推导
以离散型数据集为例,给定m个相互独立训练样本X={x(1),x(2),...,x(m)},假设样本数据中存在隐含数据Z={z(1),z(2),...,z(m)},此时X关于参数θ的对数似然函数为:
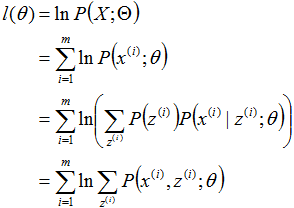
令z的分布为Qi(z(i)),它满足:
![]()
则似然函数可转换为:

根据Jensen不等式的特性,当 的值为常数c的时候(即在两端点),l(θ)函数才能取得等号。E步得到的Qi(z(i))计算公式:
的值为常数c的时候(即在两端点),l(θ)函数才能取得等号。E步得到的Qi(z(i))计算公式:

M步是在给定Qi(z(i))后极大化l(θ)的下界:

三、EM算法收敛证明
假设θ(t)和θ(t+1)是第t次和t+1次迭代的结果,只要能够证明对数似然函数的值在迭代的过程中是单调递增的即可,即l(θ(t+1))≥l(θ(t)),要证明:
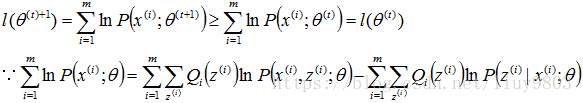
构造L(θ)和H(θ)分别为上式的第一、第二部分:
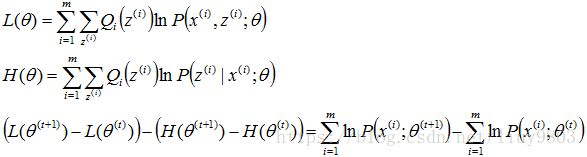
由于M步极大化L(θ)使得L(θ(t+1))-L(θ(t))≥0,这样只需要证明H(θ(t+1))-H(θ(t))≤0即可得证l(θ(t+1))≥l(θ(t))。


采用EM思想的算法有K-means、高斯混合模型、协同过滤、蒙特卡洛算法等。K-means是hard EM(二分抉择)算法,E步是将每个点分配给最近簇(染色),M步更新每个簇的中心点。而soft EM算法是解释隐变量服从某种概率分布的。
四、高斯混合模型GMM
GMM(Gaussian Mixture Model)是指多个高斯模型的线性组合,每个高斯模型为一个component,GMM算法描述的是数据本身存在的一种分布,即无论数据集呈现何种分布,都可以通过多个单一高斯模型进行拟合。
GMM常用于聚类,component的个数可认为是簇的数量。

设n维样本空间中的随机向量x服从高斯分布,则x的概率密度函数为:

其中μ是n维均值向量,Σ是n*n的协方差矩阵。为了显示高斯分布与相应参数的依赖关系,将概率密度函数记为p(x|μ,Σ)。
假定GMM由k个高斯模型线性组成,μi与Σi是第i个高斯模型的参数,每个模型的权重即混合系数(mixture coefficient)为αi>0,那么GMM定义如下:
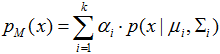
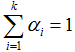
训练集D={x1,x2,...,xm}由上述过程生成,令随机变量zj∈{1,2,...,k}表示生成样本xj的高斯混合成分,取值未知。显然zj的先验概率P(zj=i)对应于αi。根据贝叶斯定理得到zj的后验分布:

pM(zj=i|xj)给出样本xj由第i个高斯混合成分生成的后验概率,简记为γji(i=1,2,...,k)。
E step:
![]()
M step:
对数似然函数

对于混合系数αi考虑限制条件后用Lagrange乘子法求解,在μ与Σ确定后:

GMM的应用有:聚类、图像分割、语音分割及特征提取等。
K-means算法可以被视为GMM的一种特殊形式,GMM能提供更强的描述能力(近邻、簇形状),这两个算法有相似的处理过程(EM),不保证全局最优,主要区别在于模型的复杂度不同,GMM有更多的初始条件要设置(初始质心、协方差矩阵和混合系数)。
