机器学习之HMM
机器学习最重要的任务,是根据已观测到的数据(如训练样本)对感兴趣的未知变量(如类别标记)进行推断(inference)。概率图模型是用图表达变量相关关系的概率模型,分为“有向无环图模型/贝叶斯网”和“无向图模型/马尔可夫网”两类。
一、马尔可夫性质
马尔可夫性质(Markov property)是概率论中的一个概念,当一个随机过程在给定现在状态以及所有过去状态的情况下,其未来状态的条件概率分布仅依赖于当前状态(即在给定当前状态后,过去与未来状态是条件独立的),那么这个随机过程就具有马尔可夫性质,具有马尔可夫性质的过程称为马尔可夫过程。
应用有马尔可夫链、布朗运动等。
二、马尔可夫链
马尔可夫链(Markov Chain)是指具有马尔可夫性质的离散事件随机过程,在给定当前状态的情况下,该过程中过去的状态对于预测未来的状态是无关的。
在马尔可夫链的每一步,系统根据概率分布,可以从一个状态变到另一个状态,也可以保持当前状态不变。状态的改变叫做转移,状态改变的相关概率叫做转移概率。
应用有随机漫步、排队理论建模、马尔可夫链蒙特卡洛方法MCMC、统计学建模、作为信号模型用于熵编码、人口过程、基因预测、谱曲等。
三、隐马尔可夫模型
HMM(Hidden Markov Model)是关于时序的概率模型,属于生成式模型,描述由一个隐藏的马尔可夫链随机生成不可观测的状态随机序列(state sequence),再由各个状态生成一个观测而产生的观测随机序列(observation sequence)的过程(双重随机过程)。
应用有语音/行为/模式识别、自然语言处理、生物信息DNA分析、故障诊断等。

1、HMM的形式定义
HMM涉及到的参数有:(隐含)状态序列I、观测序列O、初始(隐含)状态概率向量π、(隐含)状态转移概率矩阵A、观测概率矩阵B。
(1)设 ![]() 是所有可能的状态集合,
是所有可能的状态集合,![]() 是所有可能的观测集合,N是可能的状态总数,M是可能的观测总数;
是所有可能的观测集合,N是可能的状态总数,M是可能的观测总数;
(2)![]() 是长度为T的状态序列,
是长度为T的状态序列,![]() 是对应的观测序列;
是对应的观测序列;
(3)![]() 是状态转移概率矩阵,其中
是状态转移概率矩阵,其中 ![]() ,
,![]() 是在时刻t处于状态
是在时刻t处于状态 ![]() 的条件下,在时刻t+1转移到状态
的条件下,在时刻t+1转移到状态 ![]() 的概率。
的概率。
(4)![]() 是观测概率矩阵,其中
是观测概率矩阵,其中 ![]() ,
,![]() ,
,![]() 是在时刻t处于状态
是在时刻t处于状态 ![]() 的条件下生成观测
的条件下生成观测 ![]() 的概率。
的概率。
(5)![]() 是初始状态概率向量,其中
是初始状态概率向量,其中 ![]() ,i=1,2,...,N 是在时刻t=1处于状态
,i=1,2,...,N 是在时刻t=1处于状态 ![]() 的概率。
的概率。
π和A决定了状态序列、B决定观测序列,因此HMM可以使用三要素表示:λ=(A,B,π)。
2、HMM的观测序列生成过程
已知HMM模型λ,观测序列长度为T,则观测序列O的生成过程:
(1)由初始状态分布π产生状态 ![]()
(2)令t=1
(3)按照状态it的观测概率分布 ![]() 生成
生成 ![]()
(4)按照状态的状态转移概率分布 ![]() 产生状态
产生状态 ![]()
(5)令t=t+1,如果t 3、HMM的两个基本假设: (1)齐次马尔可夫性假设 假设隐藏的马尔可夫链在任意t时刻的状态只依赖于其前一时刻的状态,与其他时刻的状态及观测无关,也与时刻t无关: (2)观测独立性假设 假设任意时刻的观测只依赖于该时刻的马尔可夫链的状态,与其他的状态及观测无关: 4、HMM的3个基本问题 (1)概率计算问题:求P(O|λ) 给定模型λ,计算其生成的观测序列O的概率P(O|λ),即评估模型与观测序列之间的匹配程度。 (2)学习问题:求λ 给定观测序列O,调整模型λ的参数(MLE),使得在该模型下观测序列出现的概率P(O|λ)最大; 即训练模型使其能够更好地描述观测数据。 (3)预测问题(decoding):求I 给定模型λ和观测序列O,求使观测序列条件概率P(I|O)最大的状态序列I,即根据观测序列推断最匹配的状态序列。 四、概率计算问题 1、直接计算法(brute) 给定模型λ,计算其生成的观测序列O的概率P(O|λ)。最直接的方式是按照概率公式,列举所有可能的长度为T的状态序列 这种算法的计算量很大 2、前向算法 前向概率指的是给定模型λ,定义到时刻t部分的观测序列为 前向算法 (1)初始化前向概率,是初始时刻的状态 (2)前向递推,设 (3)将状态对应的概率求和消去,即可得到O的边缘概率: 前向概率的计算量为 3、后向算法 后向概率指的是给定模型λ,定义在时刻t状态为 后向算法 (1)初始化后向概率,对最终时刻T的所有状态,i=1,2,...,N有: (2)后向递推,在时刻t+1所有可能的N个状态 (3)将状态对应的概率求和消去,即可得到O的边缘概率: 利用前向概率和后向概率的定义可以将观测序列P(O|λ)统一写成: 4、单个状态的概率 给定模型λ和观测序列O,在时刻t处于状态 由前向、后向概率的定义可知: 于是得到: 单个状态概率的意义在于判断每个时刻最可能存在的状态,从而可以得到一个状态序列作为最终的预测结果。 5、两个状态的联合概率 给定模型λ和观测序列O,在时刻t处于状态 6、将 (1)在观测O下状态i出现的期望值: (2)在观测O下由状态i转移的期望值: (3)在观测O下由状态i转移到状态j的期望值: 五、学习问题 HMM的学习问题,根据训练数据是否包含状态序列分两类:若包含O和I,则可用监督学习算法实现;若只包含O,则需要用非监督学习算法Baum-Welch(EM)算法求解。 1、监督学习方法 由大数定理结论‘频率的极限是概率’直接得出HMM的参数估计。 (1)设时刻t处于状态i、时刻t+1转移到状态j的频数为 (2)设样本中状态为j且观测为k的频数是 (3)初始状态概率 2、非监督学习方法(Baum-Welch算法) 给定观测数据O,状态序列I未知,则HMM为含有隐变量的概率模型 (1)确定完全数据(O,I)的对数似然函数 (2)E步求Q函数 其中, (3)M步极大化Q函数,使用Lagrange乘子法分别求π、A、B的值: 对i求和消去i,可得: 对i、j求和消去i、j,可得: 对j、k求和消去j、k,可得: Baum-Welch算法流程: 给定观测序列 随机初始化 对每个样本使用前向后向算法求出 更新模型参数 如果参数收敛则停止,否则继续迭代。 六、预测问题 HMM的预测问题是给定模型λ和观测序列O,求最可能的状态序列,主要包含近似算法和Viterbi算法两种。 1、近似算法 将每个时刻t最有可能出现的状态 近似算法的优点是计算简单,缺点是不能保证预测的I*是最有可能的I,因为I*可能有实际不发生的部分。 2、Viterbi算法 使用动态规划(dynamic programming)的思路求出概率最大的路径(最优路径),一条路径对应一个状态序列。递推计算时刻 Viterbi算法流程: 给定模型λ=(A,B,π)和观测序列 (1)初始化, (2)递推 (3)终止 (4)回溯求得最优路径 参考资料: 《统计学习方法》、《机器学习——周志华》等 ![]()
![]()
![]() ,求状态序列I与观测序列
,求状态序列I与观测序列 ![]() 的联合概率P(I,O|λ),然后对所有可能的状态序列求和(边际化marginalization),从而得到最终的概率P(O|λ)。
的联合概率P(I,O|λ),然后对所有可能的状态序列求和(边际化marginalization),从而得到最终的概率P(O|λ)。![]()
![]()
![]()
![]()
![]() ,概念上可解但实际应用中不可行。
,概念上可解但实际应用中不可行。![]() ,且状态为
,且状态为 ![]() 的概率为前向概率,记作:
的概率为前向概率,记作:
![]() 和观测
和观测 ![]() 的联合概率。对状态所有的取值总数
的联合概率。对状态所有的取值总数 ![]() 有:
有:![]()
![]() 是时刻t观测到
是时刻t观测到 ![]() 且此时处于
且此时处于 ![]() 状态的前向概率;计算
状态的前向概率;计算 ![]() 就是时刻t观测到o1,o2,...,ot且此时处于
就是时刻t观测到o1,o2,...,ot且此时处于 ![]() 状态而在时刻t+1转移到状态
状态而在时刻t+1转移到状态 ![]() 的联合概率,对其在时刻t所有可能的N个状态求和再乘以观测概率:
的联合概率,对其在时刻t所有可能的N个状态求和再乘以观测概率:
![]()
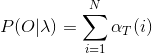
![]() ,减少计算量的原因在于每一次计算直接引用前一个时刻的计算结果,避免了重复计算。
,减少计算量的原因在于每一次计算直接引用前一个时刻的计算结果,避免了重复计算。![]() 的条件下,从t+1到T的部分观测序列为
的条件下,从t+1到T的部分观测序列为 ![]() 的概率为后向概率,记作:
的概率为后向概率,记作:
![]()
![]() 的转移概率
的转移概率 ![]() ,乘以此状态下的观测概率
,乘以此状态下的观测概率 ![]() ,再乘以状态
,再乘以状态 ![]() 之后的后向概率
之后的后向概率 ![]() 即可得到t时刻t状态为
即可得到t时刻t状态为 ![]() 的后向概率。对
的后向概率。对 ![]() ,
,![]() ,有:
,有:


![]() 的概率记为
的概率记为 ![]() :
:![]()
![]()

![]() 且在时刻t+1处于状态
且在时刻t+1处于状态 ![]() 的概率记为
的概率记为 ![]() :
:![]() 和
和 ![]() 对各个时刻t求和,可以得到一些有用的期望值
对各个时刻t求和,可以得到一些有用的期望值


![]() ,则状态转移概率
,则状态转移概率 ![]() 的估计为:
的估计为:![]()
![]() ,则观测概率
,则观测概率 ![]() 的估计为:
的估计为:![]()
![]() 的估计为样本总数中初始状态为
的估计为样本总数中初始状态为 ![]() 的频率。
的频率。![]() ,然后用EM算法进行参数估计。步骤如下:
,然后用EM算法进行参数估计。步骤如下:![]() ,它的对数似然函数是lnP(O,I|λ)
,它的对数似然函数是lnP(O,I|λ)![]() 是HMM参数的当前估计值,需要将其极大化。
是HMM参数的当前估计值,需要将其极大化。![]()


![]()
![]()
![]()








![]()
![]() ,
,![]() ,
,![]() ,得到模型
,得到模型 ![]() ;
;![]() ,
,![]() ;
;![]() ,
,![]() ,
,![]() ;
;![]() 合并成为最终要预测的状态序列
合并成为最终要预测的状态序列 ![]() 。在时刻t处于状态
。在时刻t处于状态 ![]() 的最大概率为:
的最大概率为:
![]()
![]() 状态为i的所有单个路径
状态为i的所有单个路径 ![]() 中概率值最大的一个为
中概率值最大的一个为 ![]() ,对应的终结点为
,对应的终结点为 ![]() 。从后向前逐步求得结点
。从后向前逐步求得结点 ![]() (
(![]() ),即可得到最优路径
),即可得到最优路径 ![]() 。
。![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()