机器学习主题模型之LDA参数求解——Gibbs采样
LDA参数推导的Gibbs采样方法基于马尔科夫链蒙特卡洛方法,因此首先学习MCMC方法。
一、马尔科夫链蒙特卡洛方法
MCMC(Markov Chain Monte Carlo)方法是构造适合的马尔科夫链,使其平稳分布为待估参数的后验分布,抽样并使用蒙特卡洛方法进行积分计算,实现了抽样分布随模拟的进行而改变的动态模拟,弥补了传统蒙特卡洛积分只能静态模拟的缺陷。
1、蒙特卡洛方法
蒙特卡洛方法是以概率统计的理论方法为基础的一种数值计算方法,将所要求解的问题同一定的概率模型相联系,用计算机实现统计模拟或抽样,以获得问题的近似解,故又称随机抽样法或统计试验法。这种方法求得的是近似解,对于一些复杂问题往往是唯一可行的方法,模拟的样本数越大越接近真实值,但同时计算量也大幅上升。
蒙特卡洛方法的三个步骤:
(1)构造/描述概率过程
对于本身就具有随机性质的问题,如粒子运输问题,只要正确描述和模拟这个概率过程即可;对于本来不是随机性质的确定性问题,如定积分计算,就需要构造一个人为的概率过程,将不具有随机性质的问题转化为随机性质的问题。
例如要求f(x)在[a,b]上的积分,但原函数F(x)难以求解;如果可以得到x在[a,b]上的概率分布函数p(x),则定积分可以近似求解为:
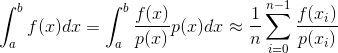
(2)实现从已知概率分布中抽样
构造概率模型后,就可以基于概率分布去采样所需的n个x的样本集,带入求和式子即可求解。最基本的一个概率分布是(0,1)上的均匀分布,可以使用线性同余发生器LCG生成伪随机数样本:
x:=(a*x+c)%m, 0
对于一些常见的连续分布,如正态分布、t分布、F分布、Beta分布、![]() 分布等都可以通过uniform(0,1)的样本转换而得。
分布等都可以通过uniform(0,1)的样本转换而得。
对于不是常见的分布,可以使用接受-拒绝采样来得到该分布的样本,即使用一个可以采样的分布q(x)与一个常数c相乘后,使得真实分布总在cq(x)曲线的下方。

重复以下步骤直到获得n个被接受的采样点:
①从cq(x)中获得一个随机采样点![]() ,值为
,值为![]() ;
;
②计算接受概率acceptance probability:![]() ;
;
③从uniform(0,1)中随机生成一个值u,如果ɑ≥u,则接受采样![]() ,否则拒绝
,否则拒绝![]() 并回到第一步。
并回到第一步。
从图上可以看出,cq(x)与p(x)曲线接近的地方接受概率较高,所以这样的地方采到的点就会比较多;而在接受概率较低的、差距较大的地方采到的点就会比较少,这也就保证了这个方法的有效性。
(3)建立各种估计量。
在构造了概率模型并从中抽样后,就可以确定一个随机变量,作为所要求问题的解——无偏估计。建立各种估计量,相当于对模拟实验的结果进行考察和登记,从中得到问题的解。
2、马尔科夫链
当后验分布的样本相互独立时,可以使用大数定律求解;当样本不独立时,就要使用马尔科夫链的平稳分布进行抽样。
对于一个非周期的马尔科夫链,任何两个状态i,j∈E是相通的(不可约),那么它的状态转移概率的极限存在且与i无关,则称此马尔科夫链具有遍历性:![]() ,此时若满足
,此时若满足![]() ,则称
,则称![]() 为转移概率的极限分布。
为转移概率的极限分布。
平稳分布:若有限或无限数列![]() 满足
满足![]() ,则称它是概率分布;如果此概率分布满足
,则称它是概率分布;如果此概率分布满足![]() ,则称它是平稳分布。
,则称它是平稳分布。
有限马尔科夫链转移概率的极限分布一定是平稳分布;无限马尔科夫链转移概率的极限分布不一定是平稳分布。
在得到平稳分布的马尔科夫链状态转移矩阵后,就可以从这个平稳分布中采样蒙特卡洛方法所需的样本集了。

3、Metropolis-Hastings算法
对不满足细致平稳条件的马尔科夫链状态转移矩阵p,引入ɑ(i,j)使其可以取等号,即得到满足条件的目标矩阵P:
ɑ(i,j)∈[0,1]称为接受率,P可以通过任意一个马尔科夫链状态转移矩阵p乘以ɑ(i,j)得到,注意每次转移后需要归一化矩阵使得每一行之和为1。但由于ɑ(i,j)可能非常小,导致大部分采样都被拒绝转移,马尔科夫链需要采样很多次才能收敛,采样效率很低。
MH采样将接受率做了如下改进,解决了接受率过低的问题:
![]()
MH算法在特征很多的情况下,接受率的计算量很大;且在特征维度很高,难以求出特征的联合概率分布,只能得到特征之间的条件概率分布时,需要采取Gibbs采样的方法解决这类问题。

4、Gibbs Sampling
马尔科夫链通过转移概率矩阵可以收敛到稳定的概率分布,这意味着MCMC可以借助马尔科夫链的平稳分布特性模拟高维概率分布p(x);当马尔科夫链经过burn-in阶段,消除初始参数的影响、达到平稳状态后,每一次状态转移都可以生成待模拟分布的一个样本。
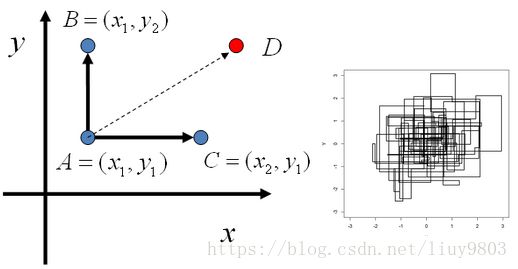
Gibbs采样是MCMC算法的一个特例,只对2维以上的情况有效,它交替随机固定某一维度,通过其他维度的值来抽样该维度的值。设p(x,y)是一个二维的联合概率分布,由下图可知:
![]()
![]()
![]()
所以在 ![]() 这条直线上,如果用条件概率分布
这条直线上,如果用条件概率分布 ![]() 作为马尔科夫链的状态转移概率,则任意两个点之间的转移满足细致平稳条件;在
作为马尔科夫链的状态转移概率,则任意两个点之间的转移满足细致平稳条件;在![]() 这条直线上也是如此。Gibbs采样和MH的不同之处在于,MH只是单独考虑某两个状态的采样(相当于直接从A到D),而Gibbs采样是沿着不同维度进行轮换采样的,且接受率ɑ=1 是MH算法的特例情况。最终的近似平稳分布可以通过采样结果
这条直线上也是如此。Gibbs采样和MH的不同之处在于,MH只是单独考虑某两个状态的采样(相当于直接从A到D),而Gibbs采样是沿着不同维度进行轮换采样的,且接受率ɑ=1 是MH算法的特例情况。最终的近似平稳分布可以通过采样结果![]() 近似表达。
近似表达。

二、Gibbs采样算法求解LDA思路
在Gibbs采样算法求解LDA的方法中,假设α、η是已知的先验输入,目的是推断隐变量的分布,即估计p(θ,z,β,w|ɑ,η),可以通过对θ、β积分将它们边缘化去掉,这种方法称为collapse Gibbs sampling。
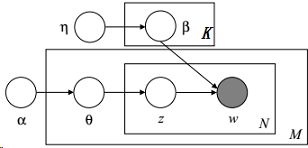
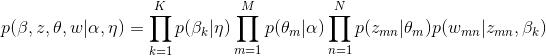
假设每篇文档长度N相同,分别考虑θ、β这两部分的积分,令![]() 代表第m篇文档中分配给第k个主题的词的个数,对应的多项分布的计数为:
代表第m篇文档中分配给第k个主题的词的个数,对应的多项分布的计数为:![]()
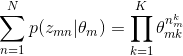
先对θ部分进行计算,根据α→θ→z的Dir-Mult共轭分布关系,省略M的连乘可得:
根据Dirichlet分布的积分性质可知:

因此θ部分积分可化为:
同样地,令![]() 代表第k个主题对应词典中第v个词的词个数,对应的多项分布的计数为:
代表第k个主题对应词典中第v个词的词个数,对应的多项分布的计数为:![]() ,可将β部分的积分写为:
,可将β部分的积分写为:
最终得到主题和词的联合分布如下:
Gibbs采样的目标是接近分布p(z|w,ɑ,η),由于w,ɑ,η已知,令![]() 表示第m篇文档的第n个词对应的主题,
表示第m篇文档的第n个词对应的主题,![]() 代表z去掉
代表z去掉![]() 后的主题分布。
后的主题分布。
![]()
注意到Gibbs采样只需要为![]() 采一个样,因此不用得到上式准确的值,只需得到
采一个样,因此不用得到上式准确的值,只需得到![]() 取值的比值即可,将上式简化为:
取值的比值即可,将上式简化为:

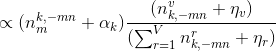
Gibbs采样公式的物理意义就是在K条doc→topic→word的路径中进行采样,当采样收敛后可得所有词最终的主题z,统计每篇文档中的主题概率p(topic|doc)可得文档主题分布![]() ,统计每个主题中所有的词概率p(word|topic)可得主题词分布
,统计每个主题中所有的词概率p(word|topic)可得主题词分布![]() 。
。
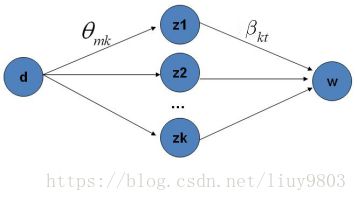
三、LDA Gibbs采样算法流程总结
(1)选择适当的主题总数K,及LDA模型参数ɑ、η;
(2)对应文集中的每一篇文档的每个词w,随机赋予一个主题编号z;
(3)重新扫描文集,对每个词w使用Gibbs采样公式更新它的主题编号,并更新文集中的词;
(4)重复采样过程直至收敛;
(5)统计文集中topic-word共现频率矩阵,即可得到LDA模型。
通常训练LDA模型时,取Gibbs采样收敛之后的n个迭代的结果进行平均来做参数估计,这样模型质量更高。
当LDA模型训练好后,要确定一篇新文档的主题时,由于各个主题的词分布![]() 已经确定,只需要对
已经确定,只需要对![]() 进行采样计算即可。
进行采样计算即可。
选择适合的超参数K非常关键,对于简单的语义区分可选择较小的K,对于复杂的语义区分则选择较大的K,且需要足够多的语料。
Gibbs采样容易并行化,可以很方便的使用大数据平台来分布式地训练海量文档的LDA模型。
参考资料
https://en.wikipedia.org/wiki/Latent_Dirichlet_allocation
lda数学八卦
https://blog.csdn.net/pipisorry/article/details/51373090
http://www.cnblogs.com/pinard/p/6831308.html