深度学习典型神经网络之ResNet
深度残差网络ResNet是2015年ILSVRC的冠军,深度达152层,是VGG的8倍,top-5错误率为3.6%。ResNet的出现使上百甚至上千层的神经网络的训练成为可能,且训练的效果也很好,利用ResNet强大的表征能力,使得图像分类、计算机视觉(如物体检测和面部识别)的性能都得到了极大的提升。
一、残差学习
根据无限逼近定理(Universal Approximation Theorem)可知,只要有足够多的神经元,一个单层的神经网络就已经足以表示任何函数了。但这样很容易出现过拟合问题,因此常见做法是让网络的结构不断加深。然而随着简单地叠加网络深度会使梯度弥散/爆炸,导致网络的性能趋于饱和,甚至不如浅层神经网络,此时可以通过输入正则化、中间层BN等方法来解决,使数十层的网络能通过具有反向传播的随机梯度下降(SGD)收敛。
当更深的网络能够开始收敛时,暴露了一个退化 degradation 问题:随着网络深度的增加,准确率达到饱和(这可能并不奇怪)然后迅速下降。但这种退化不是由过拟合引起的,并且在适当的深度模型上添加更多的层会导致更高的训练误差。

二、shortcut恒等映射
作者认为增加网络层数的同时不应降低网络的性能,因此引入深度残差结构解决退化问题,让几个堆叠的层拟合残差映射,而不直接拟合期望的底层映射,这是因为残差学习比直接学习底层特征更加容易。当残差为0时,堆叠层仅做了恒等映射,至少网络性能不会下降;实际上残差不会为0,这会使堆叠层在输入特征基础上能够学到新的特征,从而拥有更好的性能。
一层或多层的shortcut connections结构如下图所示,即“抄近道”的意思。论文中使用identity mapping作为shortcut添加到堆叠层的输出,恒等映射既不增加额外的参数也不增加计算复杂度,整个网络仍然可以由带有反向传播的SGD进行端到端的训练,并且可以使用公共库轻松实现。令x和y表示堆叠层的输入和输出,![]() 表示要学习的残差映射,则有
表示要学习的残差映射,则有 ![]() 。对于两层的模块
。对于两层的模块 ![]() ,σ为ReLU激活函数,F+x后再ReLU激活。注意y中的x和F维度必须相等,当更改输入/输出通道时,可以通过线性投影Ws来匹配维度:
,σ为ReLU激活函数,F+x后再ReLU激活。注意y中的x和F维度必须相等,当更改输入/输出通道时,可以通过线性投影Ws来匹配维度:![]()
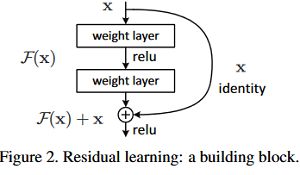
作者通过实验表明恒等映射足以解决退化问题,并且是合算的,![]() 仅在维度匹配时使用。残差函数F的形式是可变的,如两层、三层或以上的层,但如果F只有一层,
仅在维度匹配时使用。残差函数F的形式是可变的,如两层、三层或以上的层,但如果F只有一层,![]() ,则没有效果。
,则没有效果。
三、网络架构
ResNet受VGG-19的启发以其当做baseline,设计出了plain网络和残差网络。
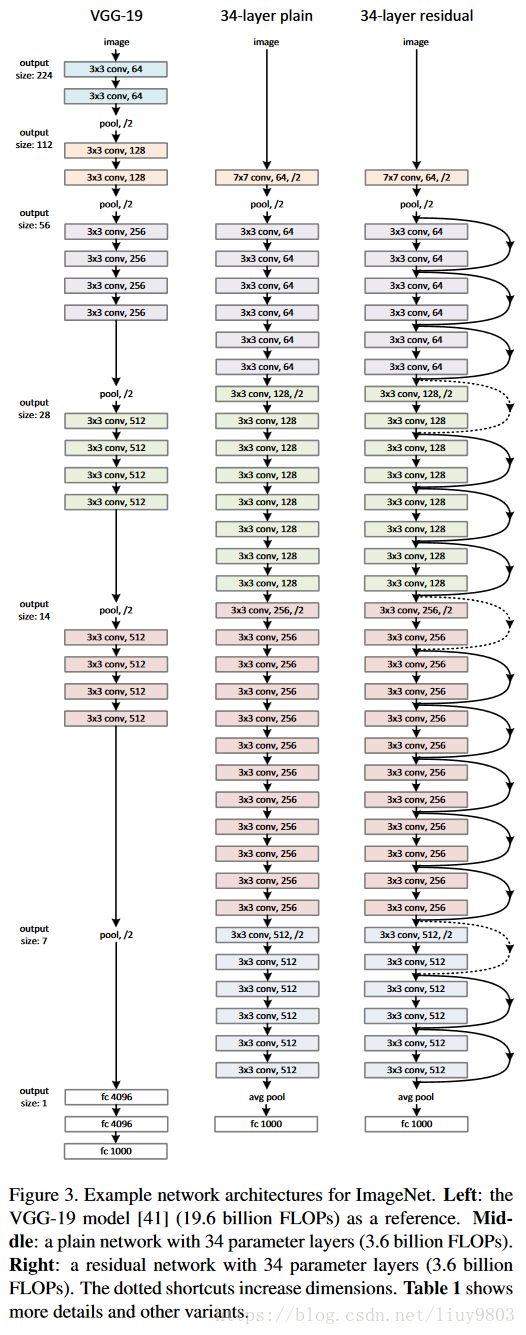
1、plain网络
卷积核多为3*3,对于有相同输出特征图尺寸的层有具有相同数量的filters;如果特征图尺寸减半,则filter数量加倍,以便保持每层的时间复杂度。通过步长为2的卷积层下采样,网络以全局平均池化层GAP和具有softmax的1000维全连接层结尾。模型与VGG相比有更少的filters和更低的复杂度,34层有36亿FLOP(multiply-adds乘加),仅为VGG-19的18%(196亿)。

2、残差网络
基于plain网络加入shortcut connections,将网络转换为对应版本的残差网络。当输入和输出具有相同的维度时,为实线连接,可以直接使用恒等映射;当维度增加时为点线连接,可以采取两种措施:(1)仍然使用恒等映射y=F(x)+x,多出的维度补零,这种方法不增加额外的参数。(2)使用 ![]() 公式匹配维度(由1*1的卷积完成)。这两种方法当shortcut连接跨越两种尺寸的特征图时,步长设为2。
公式匹配维度(由1*1的卷积完成)。这两种方法当shortcut连接跨越两种尺寸的特征图时,步长设为2。
四、实现及实验
使用尺度增强方法调整图像大小,令其较短的边在[256,480]之间进行随机采样后,从图像或其水平翻转中随机裁剪224×224的区域,并用每个像素减去均值,然后使用标准颜色增强,并在每个卷积后和激活之前使用BN。按照ReLU ![]() 、Leaky ReLU
、Leaky ReLU ![]() 的方法初始化权重,使用batch大小为256的MBGD方法,迭代次数为
的方法初始化权重,使用batch大小为256的MBGD方法,迭代次数为![]() 。学习率从0.1开始,当误差停止减小时手动缩减学习率(除以10),优化器使用的权值削减为0.0001,动量项为0.9,根据实践经验不使用dropout。
。学习率从0.1开始,当误差停止减小时手动缩减学习率(除以10),优化器使用的权值削减为0.0001,动量项为0.9,根据实践经验不使用dropout。
在测试阶段,为了比较学习采用标准的10-crop测试(10次不同位置的裁剪,还可以color shift)。对于最好的结果,作者采用全卷积形式,并在多尺度上对分数进行平均(图像尺寸调整使得短边为集合{224, 256, 384, 480, 640}中的值)。
作者使用ImageNet 2012分类数据集对几种模型进行评估,该数据集由1000个类别组成,训练集使用128万张图片,验证集5万张,测试集10万张。

Identity vs. Projection Shortcuts
文中比较了34层网络的3个变种:(A)增加的维度使用0填充,不引入额外的参数;(B)增加的维度使用投影映射,其他shortcut使用恒等映射;(C)全部使用投影映射。这3个变种比对应的plain网络效果好的多,其中B略好于A是因为A中的全0填充没有残差学习;C略好于B是因为引入了额外的参数。为了减少内存/时间复杂性和模型大小,将不再使用C。
Deeper Bottleneck Architectures
对于更深的网络考虑训练时间,使用瓶颈设计,将2层stack改为3层,分别为1*1、3*3、1*1的卷积,其中1*1负责减小然后恢复维度,使3*3称为具有较小输入输出维度的瓶颈。恒等shortcut比投影的复杂度小,可以为瓶颈设计得到更有效的模型。
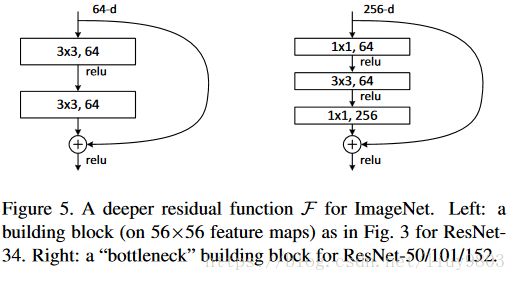
残差模块的一些变体:
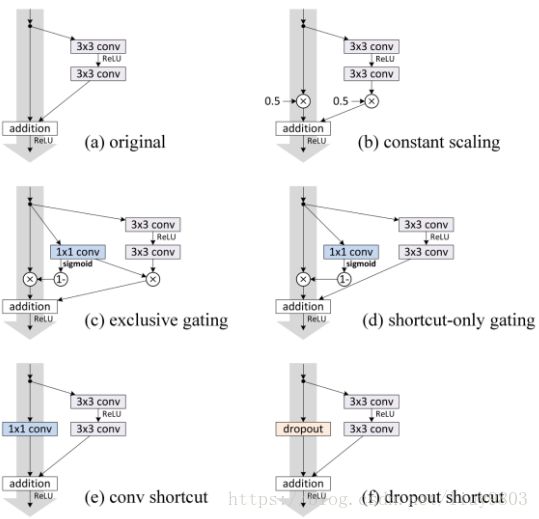
五、ResNet的变体
1、ResNeXt
将Inception引入残差模块,Inception系列基本遵循“split - transform - merge”的策略,ResNeXt网络的结果简明,更加模块化,与ResNet使用相同个数的参数,效果更好。
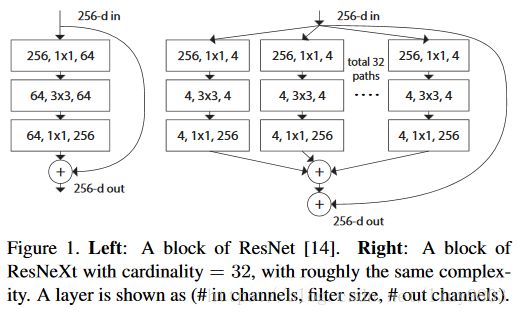
文中提出超参数cardinality基数(分支路径的数量)的概念,提供了一种调整模型能力的新思路。实验表明,通过扩大基数值,能够更加高效地提升模型的表现,与Inception相比这个全新的架构更容易适应新的数据集或任务,因为它只有一个分支和一个超参数需要调整,而Inception需要调整很多超参数(比如每个路径卷积核的大小)。下图为3种等价变体:

ResNet与ResNeXt的结构比较:

2、DenseNet
进一步使用了shortcut connections,将所有的层互相连接起来。在这个新架构中,每一层的输入都包含了所有较早的层的特征图,而且它的输出被传递至每个后续层,即对于有L层的传统网络,一共有L个连接,那么对于DenseNet则有L*(L+1)/2个连接,这些特征图通过depth concatenation在一起。
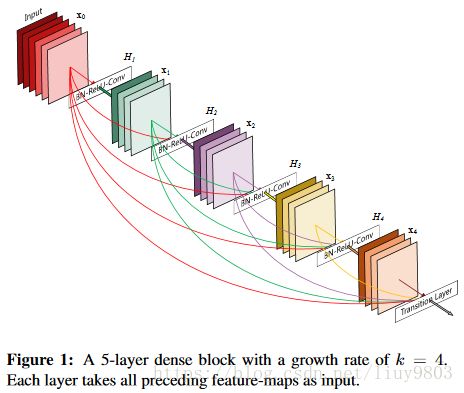
除了解决梯度消失、减少训练参数,这个架构还支持特征重用,这就使得网络更加“参数高效”。恒等变换的输出与模块的输出直接相加,如果两个层的特征图有着完全不同的分布,可能会阻碍信息的流动。因此,用depth-concatenation能够有效避免这种情况的发生,并且增加输出的多样性,进而促进特征的重新使用。
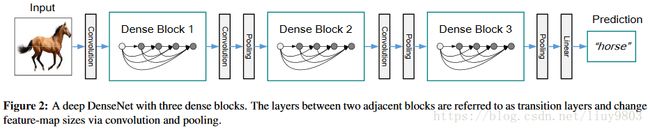
使用超参数“增长率k”防止网络变得过宽,还用一个1*1的卷积瓶颈层在3*3卷积前减少特征映射的数量,ResNet:![]() ;DenseNet:
;DenseNet:![]() ,
,![]() 表示三个操作的复合函数BN→ReLU→Conv(3*3)。整体架构如下表所示:
表示三个操作的复合函数BN→ReLU→Conv(3*3)。整体架构如下表所示:

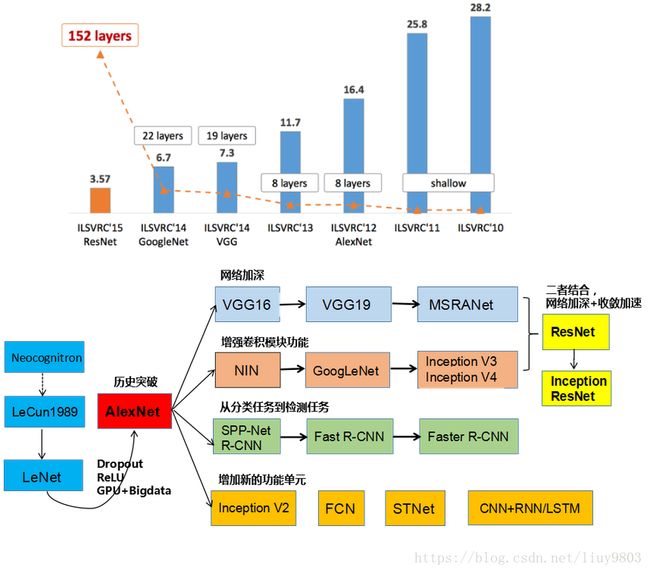
卷积神经网络的演变进程
参考资料
https://arxiv.org/pdf/1512.03385.pdf
https://arxiv.org/pdf/1611.05431.pdf
https://www.sohu.com/a/163256797_697750
https://blog.csdn.net/Quincuntial/article/details/77263562?locationNum=6