【面试篇】寒冬求职季之你必须要懂的原生JS(中)
互联网寒冬之际,各大公司都缩减了HC,甚至是采取了“裁员”措施,在这样的大环境之下,想要获得一份更好的工作,必然需要付出更多的努力。
一年前,也许你搞清楚闭包,this,原型链,就能获得认可。但是现在,很显然是不行了。本文梳理出了一些面试中有一定难度的高频原生JS问题,部分知识点可能你之前从未关注过,或者看到了,却没有仔细研究,但是它们却非常重要。本文将以真实的面试题的形式来呈现知识点,大家在阅读时,建议不要先看我的答案,而是自己先思考一番。尽管,本文所有的答案,都是我在翻阅各种资料,思考并验证之后,才给出的(绝非复制粘贴而来)。但因水平有限,本人的答案未必是最优的,如果您有更好的答案,欢迎给我留言。
本文篇幅较长,但是满满的都是干货!并且还埋伏了可爱的表情包,希望小伙伴们能够坚持读完。
写文超级真诚的小姐姐祝愿大家都能找到心仪的工作。
如果你还没读过上篇【上篇和中篇并无依赖关系,您可以读过本文之后再阅读上篇】,可戳【面试篇】寒冬求职季之你必须要懂的原生JS(上)
小姐姐花了近百个小时才完成这篇文章,篇幅较长,希望大家阅读时多花点耐心,力求真正的掌握相关知识点。
1.说一说JS异步发展史
异步最早的解决方案是回调函数,如事件的回调,setInterval/setTimeout中的回调。但是回调函数有一个很常见的问题,就是回调地狱的问题(稍后会举例说明);
为了解决回调地狱的问题,社区提出了Promise解决方案,ES6将其写进了语言标准。Promise解决了回调地狱的问题,但是Promise也存在一些问题,如错误不能被try catch,而且使用Promise的链式调用,其实并没有从根本上解决回调地狱的问题,只是换了一种写法。
ES6中引入 Generator 函数,Generator是一种异步编程解决方案,Generator 函数是协程在 ES6 的实现,最大特点就是可以交出函数的执行权,Generator 函数可以看出是异步任务的容器,需要暂停的地方,都用yield语句注明。但是 Generator 使用起来较为复杂。
ES7又提出了新的异步解决方案:async/await,async是 Generator 函数的语法糖,async/await 使得异步代码看起来像同步代码,异步编程发展的目标就是让异步逻辑的代码看起来像同步一样。
1.回调函数: callback
//node读取文件
fs.readFile(xxx, 'utf-8', function(err, data) {
//code
});
回调函数的使用场景(包括但不限于):
- 事件回调
- Node API
- setTimeout/setInterval中的回调函数
异步回调嵌套会导致代码难以维护,并且不方便统一处理错误,不能try catch 和 回调地狱(如先读取A文本内容,再根据A文本内容读取B再根据B的内容读取C…)。
fs.readFile(A, 'utf-8', function(err, data) {
fs.readFile(B, 'utf-8', function(err, data) {
fs.readFile(C, 'utf-8', function(err, data) {
fs.readFile(D, 'utf-8', function(err, data) {
//....
});
});
});
});
2.Promise
Promise 主要解决了回调地狱的问题,Promise 最早由社区提出和实现,ES6 将其写进了语言标准,统一了用法,原生提供了Promise对象。
那么我们看看Promise是如何解决回调地狱问题的,仍然以上文的readFile为例。
function read(url) {
return new Promise((resolve, reject) => {
fs.readFile(url, 'utf8', (err, data) => {
if(err) reject(err);
resolve(data);
});
});
}
read(A).then(data => {
return read(B);
}).then(data => {
return read(C);
}).then(data => {
return read(D);
}).catch(reason => {
console.log(reason);
});
想要运行代码看效果,请戳(小姐姐使用的是VS的 Code Runner 执行代码): https://github.com/YvetteLau/Blog/blob/master/JS/Async/promise.js
思考一下在Promise之前,你是如何处理异步并发问题的,假设有这样一个需求:读取三个文件内容,都读取成功后,输出最终的结果。有了Promise之后,又如何处理呢?代码可戳: https://github.com/YvetteLau/Blog/blob/master/JS/Async/index.js
注: 可以使用 bluebird 将接口 promise化;
引申: Promise有哪些优点和问题呢?
3.Generator
Generator 函数是 ES6 提供的一种异步编程解决方案,整个 Generator 函数就是一个封装的异步任务,或者说是异步任务的容器。异步操作需要暂停的地方,都用 yield 语句注明。
Generator 函数一般配合 yield 或 Promise 使用。Generator函数返回的是迭代器。对生成器和迭代器不了解的同学,请自行补习下基础。下面我们看一下 Generator 的简单使用:
function* gen() {
let a = yield 111;
console.log(a);
let b = yield 222;
console.log(b);
let c = yield 333;
console.log(c);
let d = yield 444;
console.log(d);
}
let t = gen();
//next方法可以带一个参数,该参数就会被当作上一个yield表达式的返回值
t.next(1); //第一次调用next函数时,传递的参数无效
t.next(2); //a输出2;
t.next(3); //b输出3;
t.next(4); //c输出4;
t.next(5); //d输出5;
为了让大家更好的理解上面代码是如何执行的,我画了一张图,分别对应每一次的next方法调用:

仍然以上文的readFile为例,使用 Generator + co库来实现:
const fs = require('fs');
const co = require('co');
const bluebird = require('bluebird');
const readFile = bluebird.promisify(fs.readFile);
function* read() {
yield readFile(A, 'utf-8');
yield readFile(B, 'utf-8');
yield readFile(C, 'utf-8');
//....
}
co(read()).then(data => {
//code
}).catch(err => {
//code
});
不使用co库,如何实现?能否自己写一个最简的my_co?请戳: https://github.com/YvetteLau/Blog/blob/master/JS/Async/generator.js
PS: 如果你还不太了解 Generator/yield,建议阅读ES6相关文档。
4.async/await
ES7中引入了 async/await 概念。async其实是一个语法糖,它的实现就是将Generator函数和自动执行器(co),包装在一个函数中。
async/await 的优点是代码清晰,不用像 Promise 写很多 then 链,就可以处理回调地狱的问题。错误可以被try catch。
仍然以上文的readFile为例,使用 Generator + co库来实现:
const fs = require('fs');
const bluebird = require('bluebird');
const readFile = bluebird.promisify(fs.readFile);
async function read() {
await readFile(A, 'utf-8');
await readFile(B, 'utf-8');
await readFile(C, 'utf-8');
//code
}
read().then((data) => {
//code
}).catch(err => {
//code
});
可执行代码,请戳:https://github.com/YvetteLau/Blog/blob/master/JS/Async/async.js
思考一下 async/await 如何处理异步并发问题的? https://github.com/YvetteLau/Blog/blob/master/JS/Async/index.js
如果你有更好的答案或想法,欢迎在这题目对应的github下留言:说一说JS异步发展史
2.谈谈对 async/await 的理解,async/await 的实现原理是什么?
async/await 就是 Generator 的语法糖,使得异步操作变得更加方便。来张图对比一下:
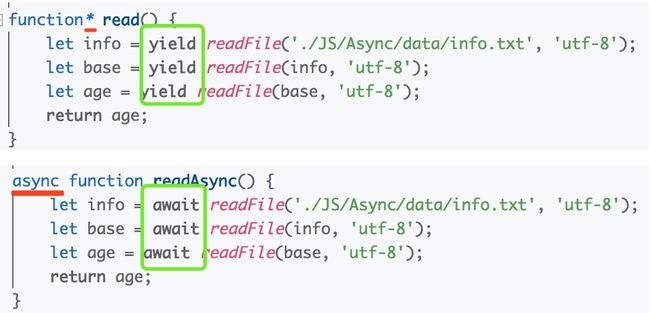
async 函数就是将 Generator 函数的星号(*)替换成 async,将 yield 替换成await。
我们说 async 是 Generator 的语法糖,那么这个糖究竟甜在哪呢?
1)async函数内置执行器,函数调用之后,会自动执行,输出最后结果。而Generator需要调用next或者配合co模块使用。
2)更好的语义,async和await,比起星号和yield,语义更清楚了。async表示函数里有异步操作,await表示紧跟在后面的表达式需要等待结果。
3)更广的适用性。co模块约定,yield命令后面只能是 Thunk 函数或 Promise 对象,而async 函数的 await 命令后面,可以是 Promise 对象和原始类型的值。
4)返回值是Promise,async函数的返回值是 Promise 对象,Generator的返回值是 Iterator,Promise 对象使用起来更加方便。
async 函数的实现原理,就是将 Generator 函数和自动执行器,包装在一个函数里。
具体代码试下如下(和spawn的实现略有差异,个人觉得这样写更容易理解),如果你想知道如何一步步写出 my_co ,可戳: https://github.com/YvetteLau/Blog/blob/master/JS/Async/my_async.js
function my_co(it) {
return new Promise((resolve, reject) => {
function next(data) {
try {
var { value, done } = it.next(data);
}catch(e){
return reject(e);
}
if (!done) {
//done为true,表示迭代完成
//value 不一定是 Promise,可能是一个普通值。使用 Promise.resolve 进行包装。
Promise.resolve(value).then(val => {
next(val);
}, reject);
} else {
resolve(value);
}
}
next(); //执行一次next
});
}
function* test() {
yield new Promise((resolve, reject) => {
setTimeout(resolve, 100);
});
yield new Promise((resolve, reject) => {
// throw Error(1);
resolve(10)
});
yield 10;
return 1000;
}
my_co(test()).then(data => {
console.log(data); //输出1000
}).catch((err) => {
console.log('err: ', err);
});
如果你有更好的答案或想法,欢迎在这题目对应的github下留言:谈谈对 async/await 的理解,async/await 的实现原理是什么?
3.使用 async/await 需要注意什么?
- await 命令后面的Promise对象,运行结果可能是 rejected,此时等同于 async 函数返回的 Promise 对象被reject。因此需要加上错误处理,可以给每个 await 后的 Promise 增加 catch 方法;也可以将 await 的代码放在
try...catch中。 - 多个await命令后面的异步操作,如果不存在继发关系,最好让它们同时触发。
//下面两种写法都可以同时触发
//法一
async function f1() {
await Promise.all([
new Promise((resolve) => {
setTimeout(resolve, 600);
}),
new Promise((resolve) => {
setTimeout(resolve, 600);
})
])
}
//法二
async function f2() {
let fn1 = new Promise((resolve) => {
setTimeout(resolve, 800);
});
let fn2 = new Promise((resolve) => {
setTimeout(resolve, 800);
})
await fn1;
await fn2;
}
- await命令只能用在async函数之中,如果用在普通函数,会报错。
- async 函数可以保留运行堆栈。
/**
* 函数a内部运行了一个异步任务b()。当b()运行的时候,函数a()不会中断,而是继续执行。
* 等到b()运行结束,可能a()早就* 运行结束了,b()所在的上下文环境已经消失了。
* 如果b()或c()报错,错误堆栈将不包括a()。
*/
function b() {
return new Promise((resolve, reject) => {
setTimeout(resolve, 200)
});
}
function c() {
throw Error(10);
}
const a = () => {
b().then(() => c());
};
a();
/**
* 改成async函数
*/
const m = async () => {
await b();
c();
};
m();
报错信息如下,可以看出 async 函数可以保留运行堆栈。

如果你有更好的答案或想法,欢迎在这题目对应的github下留言:使用 async/await 需要注意什么?
4.如何实现 Promise.race?
在代码实现前,我们需要先了解 Promise.race 的特点:
-
Promise.race返回的仍然是一个Promise.
它的状态与第一个完成的Promise的状态相同。它可以是完成( resolves),也可以是失败(rejects),这要取决于第一个Promise是哪一种状态。 -
如果传入的参数是不可迭代的,那么将会抛出错误。
-
如果传的参数数组是空,那么返回的 promise 将永远等待。
-
如果迭代包含一个或多个非承诺值和/或已解决/拒绝的承诺,则 Promise.race 将解析为迭代中找到的第一个值。
Promise.race = function (promises) {
//promises 必须是一个可遍历的数据结构,否则抛错
return new Promise((resolve, reject) => {
if (typeof promises[Symbol.iterator] !== 'function') {
//真实不是这个错误
Promise.reject('args is not iteratable!');
}
if (promises.length === 0) {
return;
} else {
for (let i = 0; i < promises.length; i++) {
Promise.resolve(promises[i]).then((data) => {
resolve(data);
return;
}, (err) => {
reject(err);
return;
});
}
}
});
}
测试代码:
//一直在等待态
Promise.race([]).then((data) => {
console.log('success ', data);
}, (err) => {
console.log('err ', err);
});
//抛错
Promise.race().then((data) => {
console.log('success ', data);
}, (err) => {
console.log('err ', err);
});
Promise.race([
new Promise((resolve, reject) => { setTimeout(() => { resolve(100) }, 1000) }),
new Promise((resolve, reject) => { setTimeout(() => { resolve(200) }, 200) }),
new Promise((resolve, reject) => { setTimeout(() => { reject(100) }, 100) })
]).then((data) => {
console.log(data);
}, (err) => {
console.log(err);
});
引申: Promise.all/Promise.reject/Promise.resolve/Promise.prototype.finally/Promise.prototype.catch 的实现原理,如果还不太会,戳:Promise源码实现
如果你有更好的答案或想法,欢迎在这题目对应的github下留言:如何实现 Promise.race?
5.可遍历数据结构的有什么特点?
一个对象如果要具备可被 for…of 循环调用的 Iterator 接口,就必须在其 Symbol.iterator 的属性上部署遍历器生成方法(或者原型链上的对象具有该方法)
PS: 遍历器对象根本特征就是具有next方法。每次调用next方法,都会返回一个代表当前成员的信息对象,具有value和done两个属性。
//如为对象添加Iterator 接口;
let obj = {
name: "Yvette",
age: 18,
job: 'engineer',
[Symbol.iterator]() {
const self = this;
const keys = Object.keys(self);
let index = 0;
return {
next() {
if (index < keys.length) {
return {
value: self[keys[index++]],
done: false
};
} else {
return { value: undefined, done: true };
}
}
};
}
};
for(let item of obj) {
console.log(item); //Yvette 18 engineer
}
使用 Generator 函数(遍历器对象生成函数)简写 Symbol.iterator 方法,可以简写如下:
let obj = {
name: "Yvette",
age: 18,
job: 'engineer',
* [Symbol.iterator] () {
const self = this;
const keys = Object.keys(self);
for (let index = 0;index < keys.length; index++) {
yield self[keys[index]];//yield表达式仅能使用在 Generator 函数中
}
}
};
原生具备 Iterator 接口的数据结构如下。
- Array
- Map
- Set
- String
- TypedArray
- 函数的 arguments 对象
- NodeList 对象
- ES6 的数组、Set、Map 都部署了以下三个方法: entries() / keys() / values(),调用后都返回遍历器对象。
如果你有更好的答案或想法,欢迎在这题目对应的github下留言:可遍历数据结构的有什么特点?
6.requestAnimationFrame 和 setTimeout/setInterval 有什么区别?使用 requestAnimationFrame 有哪些好处?
在 requestAnimationFrame 之前,我们主要使用 setTimeout/setInterval 来编写JS动画。
编写动画的关键是循环间隔的设置,一方面,循环间隔足够短,动画效果才能显得平滑流畅;另一方面,循环间隔还要足够长,才能确保浏览器有能力渲染产生的变化。
大部分的电脑显示器的刷新频率是60HZ,也就是每秒钟重绘60次。大多数浏览器都会对重绘操作加以限制,不超过显示器的重绘频率,因为即使超过那个频率用户体验也不会提升。因此,最平滑动画的最佳循环间隔是 1000ms / 60 ,约为16.7ms。
setTimeout/setInterval 有一个显著的缺陷在于时间是不精确的,setTimeout/setInterval 只能保证延时或间隔不小于设定的时间。因为它们实际上只是把任务添加到了任务队列中,但是如果前面的任务还没有执行完成,它们必须要等待。
requestAnimationFrame 才有的是系统时间间隔,保持最佳绘制效率,不会因为间隔时间过短,造成过度绘制,增加开销;也不会因为间隔时间太长,使用动画卡顿不流畅,让各种网页动画效果能够有一个统一的刷新机制,从而节省系统资源,提高系统性能,改善视觉效果。
综上所述,requestAnimationFrame 和 setTimeout/setInterval 在编写动画时相比,优点如下:
1.requestAnimationFrame 不需要设置时间,采用系统时间间隔,能达到最佳的动画效果。
2.requestAnimationFrame 会把每一帧中的所有DOM操作集中起来,在一次重绘或回流中就完成。
3.当 requestAnimationFrame() 运行在后台标签页或者隐藏的