hadoop学习笔记--8.MapReduce案例一:简单好友推介实现
| 一、好友推介概述 |
好友推荐算法在实际的社交环境中应用较多,比如qq软件中的“你可能认识的好友”或者是Facebook中的好友推介。常见的好友推介算法有六度分割理论,三元闭包论 和最基本的好友推介算法。在这简单介绍最简单的好友推介算法。
假设用户A有好友A1,A2,A3,则A1,A2,A3相互之间都可能通过好友A认识,是潜在的好友关系。如果用户B有好友A1,A2,B1,则A1,A2,B1相互之间都可能通过好友B认识。如下图所示
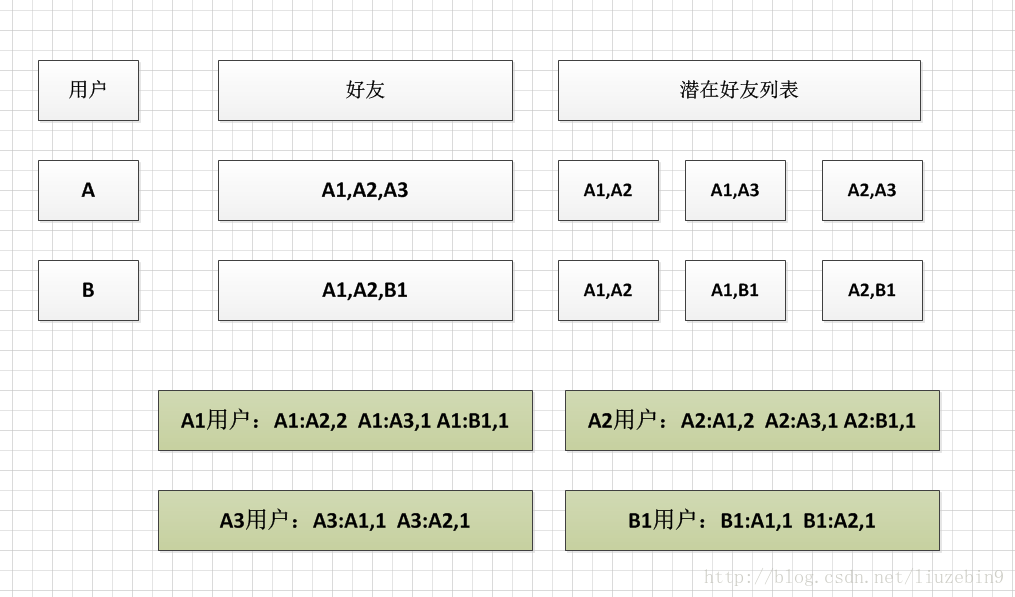
如上图所示,A1,A2在潜在好友列表中出现2次,说明A1,A2有2个共同好友,在上图中即为A,B。当两个潜在好友如果共同好友越多,则他们可能认识的可能性就越大,彼此之间推介机会就越高。算法简单介绍如下:首先需要遍历所有用户的好友列表生成两两间的潜在好友列表,计算所有用户潜在好友列表中同一对潜在好友出现的次数。如上图例子中A1,A2出现次数为2次。注意:A1:A2与A2:A1为相同的一对潜在好友,计算时应进行累加。再次计算同一个用户的潜在好友列表和出现的次数,如图中A1用户,A1与A2出现2次,A1与A3出现1次,A1与B1出现1次。如果只能给每个用户推介一个好友的话,A2与A1认识的可能性更大,优先推介A2。注意:还需要除去已经是该用户好友的潜在好友列表。如果A1与A2已经是好友关系了,则不需要再次推介。
| 二、MapReduce程序实现 |
2.1 实验数据

备注:每个名字之间用”\t”分隔符隔开。
2.2 潜在好友列表统计
2.2.1 类型定义
由于A1:A2与A2:A1是同一个潜在好友列表,为了能够方便的统计,故统一按照字典排序,输出A1:A2格式。
package friendsToFriends;
import org.apache.hadoop.io.Text;
/**
*
* @author liu
* 说明:好友a:b之间与好友b:a之间是一样的,为了在reduce阶段,key相同可以自动合并,
* 故采用字典排序统一规范好友之间的名字列表
*/
public class Fof extends Text{
public Fof(){
super();
}
public Fof(String a,String b){
super(getFof(a, b));
}
//统一确定a与b的排序格式
public static String getFof(String a,String b){
int r = a.compareTo(b);
if(r<0){
return a+"\t"+b;
}else{
return b+"\t"+a;
}
}
}2.2.2 Map类定义
//map函数,统计好友之间的FOF关系列表(FOF关系:潜在好友关系)
static class FofMapper extends Mapper<Text, Text, Fof, IntWritable>{
@Override
protected void map(Text key, Text value,
Context context)
throws IOException, InterruptedException {
String user = key.toString(); //用户
String[] friends = StringUtils.split(value.toString(), '\t'); //用户所有的好友列表
//好友之间的FOF关系矩阵
for (int i = 0; i < friends.length; i++) {
String f1 = friends[i]; //好友1
Fof AlreadyFriends =new Fof(user, f1); //用户的好友列表
context.write(AlreadyFriends, new IntWritable(0)); //输出好友列表,值为0。方便在reduce阶段去除已经是好友的FOF关系。
for (int j = i+1; j < friends.length; j++) {
String f2 = friends[j]; //好友2
Fof fof = new Fof(f1,f2);
context.write(fof, new IntWritable(1)); //输出好友之间的FOF关系列表,值为1,方便reduce阶段累加
}
}
}
}2.2.3 Reduce类定义
//reduce函数,统计全部的FOF关系列表的系数
static class FofReducer extends Reducer<Fof, IntWritable, Fof, IntWritable>{
@Override
protected void reduce(Fof arg0, Iterable arg1,
Context arg2)
throws IOException, InterruptedException {
int sum = 0;
boolean f = true;
for(IntWritable i:arg1){
if(i.get() == 0){ //已经是好友关系
f = false;
break;
}else {
sum = sum+i.get(); //累计,统计FOF的系数
}
}
if(f){ //已经是好友关系的,不再重复推介
arg2.write(arg0, new IntWritable(sum)); //输出key为潜在好友对,值为出现的次数
}
}
} 2.2.4 运行类定义
public static void run1(Configuration config) {
try {
FileSystem fs =FileSystem.get(config);
//设置job
Job job = Job.getInstance(config);
job.setJarByClass(Main.class); //设置main方法所在的类
job.setJobName("run1");
//设置mapper相关类
job.setMapperClass(FofMapper.class);
job.setMapOutputKeyClass(Fof.class);
job.setMapOutputValueClass(IntWritable.class);
//设置reducer相关属性
job.setReducerClass(FofReducer.class);
job.setOutputKeyClass(Fof.class);
job.setOutputValueClass(IntWritable.class);
//设置keyvalue分隔符
job.setInputFormatClass(KeyValueTextInputFormat.class);
//设置输入输出目录
FileInputFormat.addInputPath(job, new Path("/home/liu/input/FOF/FOF数据.txt"));
Path outPath = new Path("/home/liu/output/FOF/f1");
if(fs.exists(outPath)){
fs.delete(outPath, true);
}
FileOutputFormat.setOutputPath(job, outPath);
//提交任务
boolean f = job.waitForCompletion(true);
if(f){
System.out.println("job执行成功");
}
} catch (Exception e) {
e.printStackTrace();
}
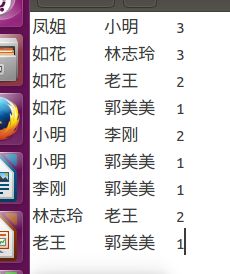
} 2.2.5 实验结果
2.3 好友推介计算
由于在MapReduce中,key值自动能够排序,而value值往往不可以。所以为了根据每一个用户与其他用户的共同好友个数从高到低排序,不仅需要将用户名作为key,还需要将该用户与推介用户的共同好友个数作为key的一部分。所以需要重新定义一个类。
2.3.1 类型定义
package friendsToFriends;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.WritableComparable;
/**
*
* @author liu
* User作为key和value,User:用户名+FOF系数
* 用户名一致,FOF系数从大到小排序。 很容易得到一个用户的好友推介的列表
*/
public class User implements WritableComparable{
private String name;
private int friendsCount;
public User() {
}
public User(String name,int friendsCount){
this.name=name;
this.friendsCount=friendsCount;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getFriendsCount() {
return friendsCount;
}
public void setFriendsCount(int friendsCount) {
this.friendsCount = friendsCount;
}
//反序列化
public void readFields(DataInput arg0) throws IOException {
this.name = arg0.readUTF();
this.friendsCount = arg0.readInt();
}
//序列化
public void write(DataOutput arg0) throws IOException {
arg0.writeUTF(name);
arg0.writeInt(friendsCount);
}
//判断是否为同一用户
public int compareTo(User o) {
int result = this.name.compareTo(o.name);
if(result==0){
return Integer.compare(this.friendsCount, o.friendsCount);
}
return result;
}
} 2.3.2 Map类定义
//map函数,每个用户的推介好友列表,并按推介指数从大到小排序
static class SortMapper extends Mapper<Text, Text,User, User>{
protected void map(Text key, Text value,
Context context)
throws IOException, InterruptedException {
String[] splits = StringUtils.split(value.toString(),'\t');
String other = splits[0]; //推介的好友
int friendsCount = Integer.parseInt(splits[1]); // 该推介好友的推介系数
context.write(new User(key.toString(),friendsCount), new User(other,friendsCount)); //mapkey输出用户和好友推介系数。
context.write(new User(other,friendsCount), new User(key.toString(),friendsCount)); //好友关系是相互的,
}
}2.3.3 sort类定义
package friendsToFriends;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
/**
*
* @author liu
* 将key根据用户名和次数排序
*/
public class FofSort extends WritableComparator{
public FofSort() {
super(User.class,true);
}
public int compare(WritableComparable a,WritableComparable b){
User u1 = (User) a;
User u2 = (User) b;
int result = u1.getName().compareTo(u2.getName()); //比较用户名
if(result == 0){
return -Integer.compare(u1.getFriendsCount(), u2.getFriendsCount()); //比较次数
}
return result;
}
}
2.3.4 Group类定义
package friendsToFriends;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
/**
*
* @author liu
* 将同一个用户作为一个Group,同时被reduce处理。
*/
public class FoFGroup extends WritableComparator{
public FoFGroup() {
super(User.class,true);
}
public int compare(WritableComparable a, WritableComparable b) {
User u1 =(User) a;
User u2=(User) b;
return u1.getName().compareTo(u2.getName()); //比较是否为同一个用户
}
}2.3.5 Reduce类定义
//同一时刻,同一个group的值同时处理,同一个group的值放在 Iterable arg1中
static class SortReducer extends Reducer<User, User, Text, Text>{
protected void reduce(User arg0, Iterable arg1,
Context arg2)
throws IOException, InterruptedException {
String user = arg0.getName(); //用户名
StringBuffer sb = new StringBuffer();
for(User u:arg1){
sb.append(u.getName()+":"+u.getFriendsCount()+","); //推介好友
}
arg2.write(new Text(user), new Text(sb.toString()));
}
} 2.3.6 运行类定义
public static void run2(Configuration config) {
try {
FileSystem fs =FileSystem.get(config);
//设置job
Job job = Job.getInstance(config);
job.setJarByClass(Main.class); //设置main方法所在的类
job.setJobName("run2");
//设置mapper相关类
job.setMapperClass(SortMapper.class);
job.setMapOutputKeyClass(User.class);
job.setMapOutputValueClass(User.class);
//设置reducer相关属性
job.setReducerClass(SortReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//设置排序分组
job.setSortComparatorClass(FofSort.class);
job.setGroupingComparatorClass(FoFGroup.class);
//设置keyvalue分隔符
job.setInputFormatClass(KeyValueTextInputFormat.class);
//设置输入输出目录
FileInputFormat.addInputPath(job, new Path("/home/liu/output/FOF/f1"));
Path outPath = new Path("/home/liu/output/FOF/f2");
if(fs.exists(outPath)){
fs.delete(outPath, true);
}
FileOutputFormat.setOutputPath(job, outPath);
//提交任务
boolean f = job.waitForCompletion(true);
if(f){
System.out.println("job执行成功");
}
} catch (Exception e) {
e.printStackTrace();
}
} 2.3.6 实验结果
