数据结构与算法--双向链表
单向链表的指向是单向的,当前结点只指向它的后一个结点。同样,遍历的时候也只有一个顺序。如果需要访问前一个结点,即使是单向循环链表也需要循环size - 1次。有没有办法更方便的访问前面的结点呢?改变下Node的数据结构就行了。
private class Node {
Item data;
Node prev;
Node next;
}
其中Item是泛型参数。现在每个结点都有两个指向了,同时拥有了前后两个结点的信息。由于我们实现的是非循环结构的双向链表,所以first的prev指向null,last的next指向null,这应该是不言自明的。虽然每个结点有个两个指针,但是很多操作中只用一个指针也够了,所以单链表的很多方法可以直接拿过来使用。
上代码。
package Chap3;
import java.util.Iterator;
public class DLinkedList- implements Iterable
- {
private class Node {
Item data;
Node prev;
Node next;
}
// 指向第一个节点
private Node first;
// 指向最后一个节点
private Node last;
private int N;
public int size() {
return N;
}
public boolean isEmpty() {
return N == 0;
}
private Node index(int index) {
// [0, N-1]的定位范围
if (index < 0 || index >= N) {
throw new IndexOutOfBoundsException(index + "");
}
// 索引在前半部分就正向查找, 在后半部分就反向查找
if (index < N / 2) {
Node current = first;
for (int j = 0; j < index; j++) {
current = current.next;
}
return current;
} else {
Node current = last;
for (int i = N - 1; i > index; i--) {
current = current.prev;
}
return current;
}
}
public Item get(int index) {
Node current = index(index);
return current.data;
}
public void set(int index, Item item) {
Node current = index(index);
current.data = item;
}
// 可以在表头(index==0)和表尾插入
public void insert(int index, Item item) {
if (index == N) {
add(item);
} else {
// 因为有prev,所以定位到当前结点就好,如果使用index(index -1)当index为0时报错
Node current = index(index);
Node pre = current.prev;
Node a = new Node();
a.data = item;
/* 由于多处使用到current即pre.next,所以最后才改变其值
1. 先确定新结点的两头
2. 更新 后结点的前驱
3. 更新 前结点的后继
*/
a.prev = pre;
a.next = current;
current.prev = a;
// 如果是insert(0,item)则pre为null,没有前结点,跳过步骤3
if (pre == null) {
first = a;
} else {
pre.next = a;
}
N++;
}
}
public Item remove(int index) {
/*
定位到当前位置
1. 前一结点的后继为下一结点
2. 下一结点的前驱为前一结点
*/
Node current = index(index);
Item item = current.data;
Node pre = current.prev;
Node next = current.next;
// 下面三行帮助垃圾回收
current.prev = null;
current.next = null;
current.data = null;
// 如果删除的是第一个结点,则pre为null。没有后继,跳过
if (pre == null) {
first = next;
} else {
pre.next = next;
}
// 如果删除的是最后一个结点,则next为null。没有前驱,跳过
if (next == null) {
last = pre;
} else {
next.prev = pre;
}
N--;
return item;
}
// 表尾加入元素
public void add(Item item) {
Node oldlast = last;
last = new Node();
last.data = item;
// last应该指向null,但是新的结点next默认就是null
// 如果是第一个元素,则last和first指向同一个,即第一个
if (isEmpty()) {
first = last;
} else {
last.prev = oldlast;
oldlast.next = last;
}
N++;
}
// 表头插入元素
public void push(Item item) {
Node oldfirst = first;
first = new Node();
first.data = item;
// 和add一样,第一个元素加入时,last和first指向同一个结点
if (isEmpty()) {
last = first;
} else {
first.next = oldfirst;
oldfirst.prev = first;
}
N++;
}
// 删除表头元素
public Item pop() {
Item item = first.data;
Node next = first.next;
// 这两行有助于垃圾回收
first.data = null;
first.next = null;
first = next;
N--;
// 最后一个元素被删除,first自然为空了,但是last需要置空。
if (isEmpty()) {
last = null;
} else {
// next的引用给first,此时first的prev不为空。需要把表头的前驱设为null(因为first没有前驱)
first.prev = null;
}
return item;
}
public void clear() {
while (first != null) {
Node next = first.next;
// 下面两行帮助垃圾回收
first.next = null;
first.data = null;
first = next;
}
// 所有元素都空时,last也没有有所指了。记得last置空
last = null;
N = 0;
}
public int indexOf(Item item) {
int index = 0;
if (item != null) {
for (Node cur = first; cur != null; cur = cur.next) {
if (item.equals(cur.data)) {
return index;
}
index++;
}
} else {
for (Node cur = first; cur != null; cur = cur.next) {
if (cur.data == null) {
return index;
}
index++;
}
}
return -1;
}
public boolean contains(Item item) {
return indexOf(item) >= 0;
}
@Override
public Iterator
- iterator() {
return new Iterator
- () {
private Node current = first;
@Override
public boolean hasNext() {
return current != null;
}
@Override
public Item next() {
Item item = current.data;
current = current.next;
return item;
}
};
}
public Iterable
- reversed() {
return new Iterable
- () {
@Override
public Iterator
- iterator() {
return new Iterator
- () {
Node cur = last;
@Override
public boolean hasNext() {
return cur != null;
}
@Override
public Item next() {
Item item = cur.data;
cur = cur.prev;
return item;
}
};
}
@Override
public String toString() {
Iterator
- it = iterator();
if (!it.hasNext()) {
return "[]";
}
StringBuilder sb = new StringBuilder();
sb.append("[");
while (true) {
Item item = it.next();
sb.append(item);
if (!it.hasNext()) {
return sb.append("]").toString();
}
sb.append(", ");
}
}
};
}
@Override
public String toString() {
Iterator
- it = iterator();
if (!it.hasNext()) {
return "[]";
}
StringBuilder sb = new StringBuilder();
sb.append("[");
while (true) {
Item item = it.next();
sb.append(item);
if (!it.hasNext()) {
return sb.append("]").toString();
}
sb.append(", ");
}
}
public static void main(String[] args) {
DLinkedList
a = new DLinkedList<>();
a.push(2);
a.push(1);
a.push(3);
a.set(2, 11);
System.out.println(a.get(2)); // 11
System.out.println(a);
a.insert(0, 444);
a.clear();
a.add(11);
a.add(12);
a.add(13);
a.push(14);
a.remove(2); // 12
a.pop(); // 14
System.out.println(a.indexOf(13)); // 1
System.out.println(a.reversed());
for (Integer aa : a.reversed()) {
System.out.println(aa);
}
}
}
考虑到效率问题,在定位函数Node index(int index)中使用了prev指针。可以看到,当索引位置在链表的前半部分时,使用next指针正向查找。当索引位置在链表的后半部分时,使用prev指针反向查找。这能减少循环次数,提高效率。
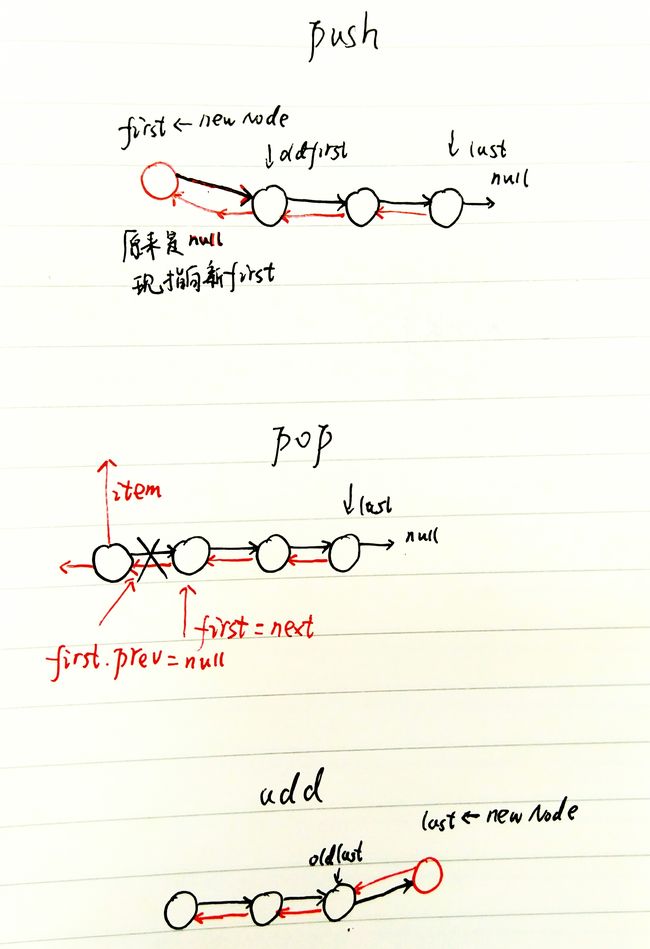
再看push方法,与单链表的方法相比多了一句oldfirst.prev = first,让原first结点的前驱指向新的first结点。
pop方法多了一个判断分支,当被弹出的时最后一个结点时,即first被弹出时,由于first.prev和first.next都已经是null了,所以只需将last置为null;但是如果被弹出的不是最后一个结点呢?next结点携带着prev的信息,所以在 first = next之后,first的prev并不为null。所以需要手动令first.prev = null。
add方法,也只是多了一句last.prev = oldlast;,目的是让新的last的前驱指向旧的last结点。
以上三个方法,看图:
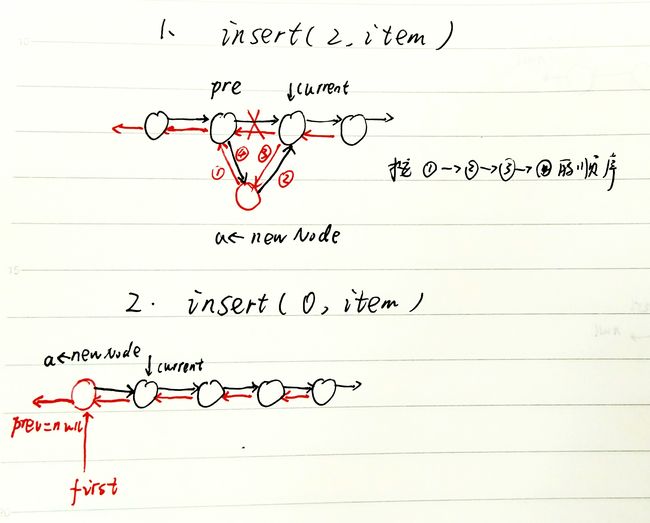
再看关键的insert方法,在单链表的实现中,需要定位到插入结点的前一个位置,即index - 1处。由于没有使用头结点,所以在insert(0, item)处,由于不能定位到index为-1的位置,操作方法有所不同(直接使用push方法)。在双向链表中,如果使用单链表的方法,在表尾a[N]处插入时,会定位到last,那么current.next为null,调用current.next.prev将引发空指针异常。除非再单独开一个条件当在a[N]处插入时调用add方法插到末尾。这样代码显得很臃肿。
双向链表有个prev指针,好好利用起来,在定位的时候不必定位到index - 1处了,直接定位到index处可以省去一些麻烦。看insert中这两句
if (index == N) {
add(item);
}
这两句代码很机智,在插入第一个结点时若使用insert(0, item),会直接调用add方法,以后在末尾插入时候,依然调用add方法。如果按照单链表insert的思路来实现双链表的insert方法,需要分index == 0,index == N等情况。由于可以直接定位到index位置,定位的范围是[0, N],index==N的情况采用上面两行的方法处理。当index == 0时else分支也能正确处理。整个insert其实只使用了插入点处的结点current和它前一个结点current.prev。
再看,赋值语句顺序不能搞错。
Node pre = current.prev;
Node a = new Node();
a.data = item;
a.prev = pre;
a.next = current;
current.prev = a;
if (pre == null) {
first = a;
} else {
pre.next = a;
}
由于多处使用到current即pre.next,所以最后才改变其值,不然先改变了,后面使用时指向的对象已经变了。这会导致操作失败。记住下面的操作顺序,一般就不会出错了。
1. 先确定新结点的两头
2. 更新 后结点的前驱
3. 更新 前结点的后继
如果是insert(0, item),相当于push操作,此时pre为null,无法调用pre.next,跳过步骤3。想想push的原理,其实就是让插入的结点成为新的first。
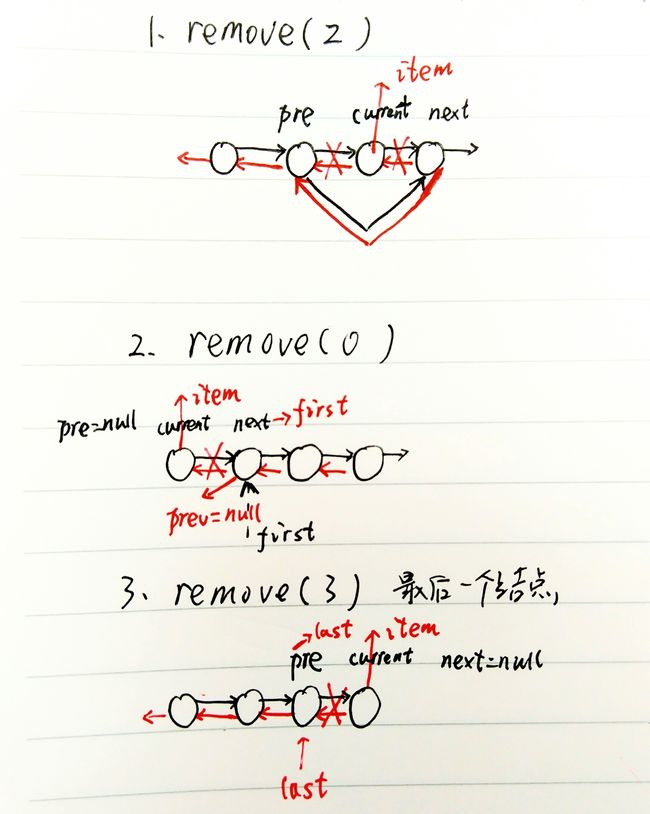
remove方法,也是定位到删除位置,范围是[0, N - 1]。使用到了移除处的结点current,它前一个结点current.prev以及它后一个结点current.next。先用一个临时变量保存后两者。然后清空移除处结点的信息,帮助垃圾回收。
移除需要分三种情况:
- 移除除first和last之外的其他结点
记住下面的操作
- 前一结点的next指向下一结点
- 下一结点的prev指向前一结点
用代码表示就是
pre.next = next;
next.prev = pre;
- 移除first结点
- 让下一结点成为新的first
- 下一结点(已经成为first)的prev置为null(pre此时为null)
代码表示为
// pre == null
first = next;
next.prev = pre;
- 移除last结点
- 前一个结点(即将称为新的last)的next先指向null(next此时为null)
- 让这个结点成为新的last
代码表示就是
pre.next = next;
last = pre;
其余方法如indexOf、contains、clear、iterator都直接使用单链表的实现就行。由于双向链表可以访问前面的结点,所以新增了一个reversed方法,返回一个逆序的可迭代对象,即返回一个Iterable,为此需要实现iterator方法。
new Iterator- () {
Node cur = last;
@Override
public boolean hasNext() {
return cur != null;
}
@Override
public Item next() {
Item item = cur.data;
cur = cur.prev;
return item;
}
};
将当前指针移动到last结点位置,然后通过cur = cur.prev遍历。其实就是将单链表iterator实现中的first改成了last,cur.next改成了prev。
by @sunhaiyu
2017.8.2