9、MapReduce程序Java示例
Hadoop一般用于做数据分析以及数据挖掘,并不做类似sql的关系数据查询;
MapReducer程序中程序员可以控制的部分:
Mapper、Shuffle的partition,Combiner以及Reducer过程
1、创建Eclipse的Hadoop程序
新建程序,选择Java Project即可

选择下一步,命名为MapReduce项目名,然后点击finish结束即可

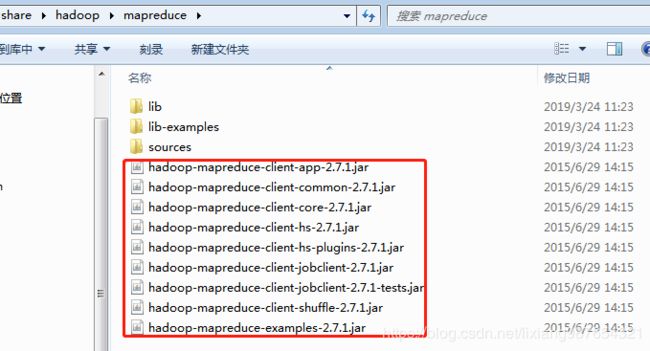
2、导入Hadoop相关的jar包
这里我安装的Hadoop版本为Hadoop2.7.1版本,网络下载的tar包解压后即可发现对应的jar包,在..\hadoop2.7.1\hadoop-2.7.1\share\hadoop的子目录之下,找到如下所有包:
各个包的作用:
commons-cli:主要提供了解析命令行的库
commons-logging:常用的日志相关库
guava: guava是google的一个开源项目。其中包含了很多java的常用库
hadoop-common:hadoop的基础依赖库,包括配置文件,文件系统,通信,安全等
hadoop-mapreduce-client-core:顾名思义,这是编写mapreduce程序的核心依赖库了
当然如果有必要的话,可以导入所有jar包:
hadoop-2.7.1/share/hadoop/mapreduce下的所有jar包(子文件夹下的jar包不用)
hadoop-2.7.1/share/hadoop/common下的hadoop-common-2.7.2.jar
hadoop-2.7.1/share/hadoop/common/lib下的commons-cli-1.2.jar
实际开发过程最好导入如下所有包,以免缺少包导致错误
(1)hadoop-2.7.1\share\hadoop\common 下的三个包
hadoop-common-2.7.1.jar
hadoop-common-2.7.1-tests.jar
hadoop-nfs-2.7.1.jar
(2)\hadoop-2.7.1\share\hadoop\common\lib下的第三方所有包
(3)基于MapReduce的,所以需要导入MapReduce相关jar包
hadoop-2.7.1\share\hadoop\mapreduce
MapReduce基于Yarn的,所以需要导入Yarn相关包
hadoop-2.7.1\share\hadoop\yarn

另外MapReduce运行过程需要读写文件,所以依赖hdfs相关jar包
hadoop-2.7.1\share\hadoop\hdfs

3、编写Mapper类
package com.dondown.mapper;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.util.StringUtils;
/**
* Mapper
* 前两个输入数据的key value
* 后两个输出数据key value
* Mapper
* 输入为数据行的下角标和对应文本
* 输出为自定义的key为单词,value为单词个数
* @author Administrator
*
*/
public class WordCountMapper extends Mapper
/**
* 该方法循环调用, 从文件中的split中读取每行调用一次,
* 把该行所在的下标为key,该行的内容为value
* context为输出结果,输出结果key为单词,value为单词次数+1-后续会被合并
*/
@Override
protected void map(LongWritable key, Text value, Mapper
throws IOException, InterruptedException {
// value为每一行数据,每读取一行就回调一次,key为对应行所在的下标
String[] words = StringUtils.split(value.toString(), ' ');
for(String w :words){
context.write(new Text(w), new IntWritable(1));
}
}
}
4、编写reducer类
package com.dondown.reducer;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
/**
* 洗完牌,循环调用,每一组数据调用一次: 每组数据特点,key相同,value可能有多个
*/
@Override
protected void reduce(Text arg0, Iterable
Reducer
int sum = 0;
for(IntWritable i : arg1){
sum=sum + i.get();
}
// key相同的计算累计出现次数
arg2.write(arg0, new IntWritable(sum));
}
}
5、编写Job执行类
package com.dondown;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import com.dondown.mapper.WordCountMapper;
import com.dondown.reducer.WordCountReducer;
public class WordCountJob {
public static void main(String[] args) {
Configuration config = new Configuration();
try {
// 设置Job相关信息
Job job = Job.getInstance(config);
// 运行入口类
job.setJarByClass(WordCountJob.class);
// 设置Job名称
job.setJobName("WordCount");
// 设置mapper和reduce处理程序
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
// mapper操作输出key和value类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 注意:多个文件可以只写文件名 ,单个文件可以写为/input/word.txt
//FileInputFormat.setInputPaths(job, new Path("/input/"));
FileInputFormat.addInputPath(job, new Path("/input/"));
// 设置输出路径:如果输出路径存在则循环删除
Path outPath = new Path("/output");
FileSystem fs = FileSystem.get(config);
if(fs.exists(outPath)){
fs.delete(outPath, true);
}
fs.close();
FileOutputFormat.setOutputPath(job, outPath);
boolean completion = job.waitForCompletion(true);
if(completion){
System.out.println("统计单词个数执行完成!");
}
} catch (Exception e) {
System.out.println(e);
e.printStackTrace();
}
}
}
6、打包jar文件
选择可运行的jar包文件


导出的jar包,拷贝上传到linux系统:


7、上传大文件
为了与程序写的一致,我们必须建立一个跟目录/input,并在其下防止一个word.txt文件
创建根目录文件夹input
hadoop fs -mkdir /input
hadoop fs -ls /

使用hadoop文件系统进行上传
打开调试模式
export HADOOP_ROOT_LOGGER=DEBUG,console
hadoop fs -put word.txt /input
hadoop fs -ls /

8、执行程序
hadoop jar WordCount.jar com.dondown.WordCountJob
![]()
注意:
hadoop jar表示运行一个jar程序,其后跟对应jar路径,jar后必须跟可运行的jar包的主类的全限定类名!
执行报错:
java.io.IOException: No FileSystem for scheme: hdfs
java.io.IOException: No FileSystem for scheme: hdfs
at org.apache.hadoop.fs.FileSystem.getFileSystemClass(FileSystem.java:2644)
at org.apache.hadoop.fs.FileSystem.createFileSystem(FileSystem.java:2651)
at org.apache.hadoop.fs.FileSystem.access$200(FileSystem.java:92)
at org.apache.hadoop.fs.FileSystem$Cache.getInternal(FileSystem.java:2687)
at org.apache.hadoop.fs.FileSystem$Cache.get(FileSystem.java:2669)
at org.apache.hadoop.fs.FileSystem.get(FileSystem.java:371)
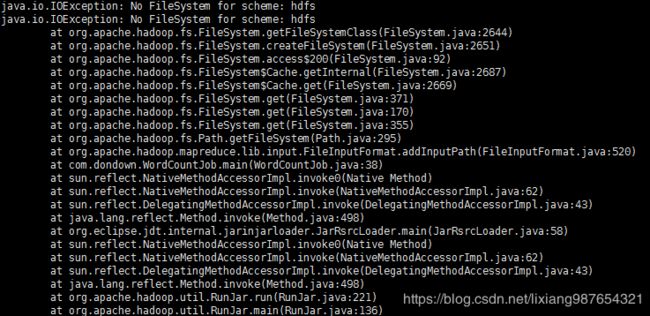
原因:缺少hadoop-hdfs-2.7.1.jar包,添加重新打包即可
执行报错:
java.io.IOException: Cannot initialize Cluster. Please check your configuration for mapreduce.framework.name and the correspond server addresses.
java.io.IOException: Cannot initialize Cluster. Please check your configuration for mapreduce.framework.name and the correspond server addresses.
at org.apache.hadoop.mapreduce.Cluster.initialize(Cluster.java:120)
at org.apache.hadoop.mapreduce.Cluster.
at org.apache.hadoop.mapreduce.Cluster.
at org.apache.hadoop.mapreduce.Job$9.run(Job.java:1260)
at org.apache.hadoop.mapreduce.Job$9.run(Job.java:1256)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1657)
at org.apache.hadoop.mapreduce.Job.connect(Job.java:1255)
at org.apache.hadoop.mapreduce.Job.submit(Job.java:1284)
at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1308)
at com.dondown.WordCountJob.main(WordCountJob.java:50)
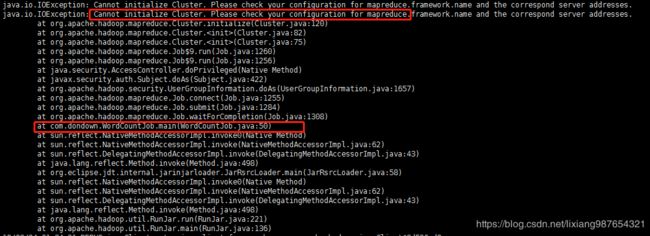
原因:缺少hadoop-mapreduce-client-common-2.7.1.jar包和hadoop-mapreduce-client-jobclient-2.7.1.jar包
以上错误解决后,仍然报错:
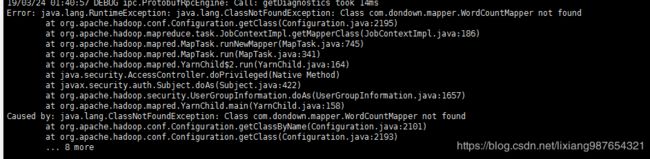
Error: java.lang.RuntimeException: java.lang.ClassNotFoundException: Class com.dondown.mapper.WordCountMapper not found
at org.apache.hadoop.conf.Configuration.getClass(Configuration.java:2195)
at org.apache.hadoop.mapreduce.task.JobContextImpl.getMapperClass(JobContextImpl.java:186)
at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:745)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:341)
at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:164)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1657)
at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:158)
原因:hadoop无法识别你的包,把自己写的wordcount放在自带的wordcount的路径下,成功执行。确定就是mapreduce.application.classpath没有搜索我放在hom下的wordcount.jar中的class
解决办法一:
将执行指令:hadoop jar WordCount.jar com.dondown.WordCountJob
对应修改为:hadoop jar com.dondown.WordCount.jar com.dondown.WordCountJob
改方法没有实验成功!!
解决办法二:
添加jar包位置设置:
// 解决eclipse打包后,自定义内部类无法找到问题
job.setJar("/home/hadoop/WordCount.jar");

或者动态设置路径:
config.set("mapred.jar", System.getProperty("user.dir")+"/WordCount.jar");

最终执行成功:

查看输出:
hadoop fs -ls /

列举文件:
hadoop fs -ls /output
![]()
可以看到,输出结果中包含一个_SUCCESS标识文件,表示执行结果是否成功,part-r-00000表示输出结果;
查看输出结果:
hadoop fs -ls /output/part-r-00000
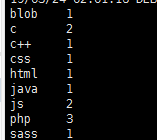
可以发现统计结果单词个数信息,与我们上传的文件相比
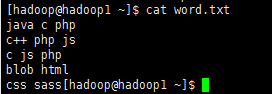
发现c和js确实为2个,php为3个,其他都为一个!说明正确执行!!!!
8、查看执行状态
打开浏览器,输入地址:http://192.168.12.150:8088/cluster
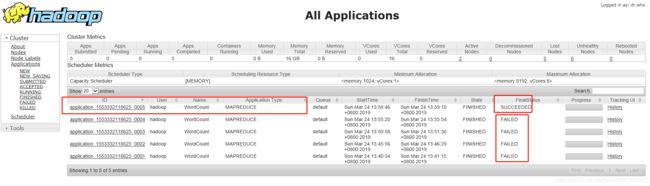
我们可以看到我们执行的任务,执行了5次,前4次失败,最后一次成功!