【性能测试】压榨一下ServiceComb
ServiceComb性能测试
- 前言
本文以一个最简单的单consumer->单producer的测试场景为例,说明了如何在指定测试环境中,通过观察metrics统计数据,不断调整参数压榨出最大性能,。
基本测试过程:
- 测试驱动加大压力,TPS逐渐上升
- 驱动压力达到一定程度后,TPS不再上升,或是缓慢上升,甚至是下降,此时伴随着时延明显上升,称之为性能拐点
- 调整consumer/producer各种参数(网络线程/业务线程等等),提升处理能力
- 重新调整测试驱动压力(加大或减小),重复前面步骤
- 输出最终性能拐点时的各项参数,包括TPS/时延/CPU/带宽等等
- 环境确认
- 使用华为云c3.2xlarge.2 VM
Node1 192.168.26.44
Node2 192.168.29.195
Node1 ping Node2:平均0.171ms
基准带宽:2 Gbit/s (指弹性云服务器能稳定达到的保证带宽)
最大带宽:5 Gbit/s (指弹性云服务器能够达到的最大带宽)
内网收发包:900,000 pps (指弹性云服务器能达到的最大收发包能力)
-
- 网络
打开网卡的RSS特性,执行ethtool -l eth0,得到类似下图的数据
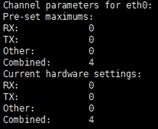
如果Pre-set的Combined不等于Current的Combined,则执行ethtool -L eth0 combined {Pre-Set Combined}改为相等,在这里应该是ethtool -L eth0 combined 4
打开网络队列的自动负载均衡:service irqbalance start
-
- CPU
cat /proc/cpuinfo | grep name
8 Intel(R) Xeon(R) Gold 6151 CPU @ 3.00GHz
-
- 内存
dmidecode -t memory
16GB
- 部署
- service center
- 下载service center
http://mirror.bit.edu.cn/apache/servicecomb/servicecomb-service-center/1.1.0/apache-servicecomb-service-center-1.1.0-linux-amd64.tar.gz
- 上传到Node2,解压
- 修改conf/app.conf,监听地址设为Node2小网IP
Httpaddr = 192.168.29.195
- 启动service center
- 编译用例工程
- 下载源码
git clone https://github.com/apache/servicecomb-java-chassis.git
- 编译
mvn clean install -Dmaven.test.skip=true
cd demo/perf
mvn install -Pdemo-run-release -Dmaven.test.skip=true
编译时增加maven.test.skip仅仅是为了加快编译速度
-
- Producer
在Node2的demo/target/perf目录中新建microservice.yaml:
service_description:
name: perf1
servicecomb:
service:
registry:
address: http://192.168.29.195:30100
highway:
address: 192.168.29.195:7070
server:
thread-count: 1
rest:
address: 192.168.29.195:8080
server:
thread-count: 1
response-size: 1024
启动:java –jar perf*
-
- 测试驱动:Consumer
在Node1的demo/target/perf目录中新建microservice.yaml:
service_description:
name: consumer
servicecomb:
service:
registry:
address: http://192.168.29.195:30100
highway:
address: 192.168.26.44:7070
client:
thread-count: 1
rest:
address: 192.168.26.44:8080
client:
thread-count: 1
connection:
maxPoolSize: 5
references:
transport: highway
metrics:
window_time: 1000
publisher.defaultLog:
enabled: true
endpoints.client.detail.enabled: true
启动:java –jar perf* -c
- Highway
- 同步调优
Consumer的microservice.yaml中配置
sync-count: 1
sync: true
-
-
- TPS/时延/CPU/带宽消耗都很低
-

此时驱动并发度才1,太低,加大驱动压力到500
sync-count: 500
-
-
- Producer CPU很低
-
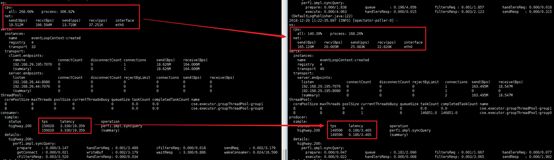
TPS上升到了10多万
时延3+ms,偏高
Producer本身时延并不太大,8C才用了不到2C,并且默认的2组业务线程中只有1组在工作(默认线程池,每1组与一个网络线程绑定)
为充分使用网络带宽,提升网络连接数
Consumer:
servicecomb:
highway:
client:
thread-count: 8
Producer:
servicecomb:
highway:
server:
thread-count: 8
-
-
- Producer 线程池排队
-
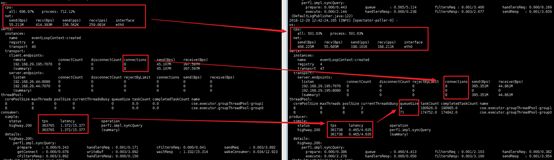
TPS进一步提升到36万左右
Consumer时延从3+ms降低到1+ms
Producer线程池有排队现象,考虑扩展线程池,有2种思路,1是加大每个池中的线程数,1是加大线程组数
因为这个性能测试场景,业务非常轻量,tps已经达到了几十万级别,线程池入队的竞争/唤醒会比较激烈,加大线程数,效果并不会太好
实际验证也确实如此,加大线程数,TPS基本不变;所以这里加大线程组,减小竞争概率,并且减小每组线程数,减少线程切换,Producer:
servicecomb:
executor:
default:
group: 4
thread-per-group: 2
-
-
- 最终效果
-
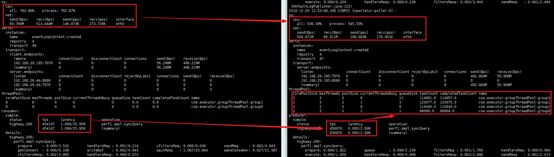
TPS提升到45万左右,时延少量下降
尝试调整驱动并发数sync-count,从当前的500并发往下调,TPS下降,往上调,TPS基本不变,而时延上升,处于性能拐点。
-
- Reactive调优
Consumer的microservice.yaml中配置
async-count: 1
sync: false
-
-
- TPS/时延/CPU/带宽消耗都很低
-

此时驱动并发度才1,太低,加大驱动压力到500
1个并发驱动,有2条连接,是因为开始压测前,独立调用了一次,用于打印调用结果;从非eventloop线程发起reactive调用,会随机选择一个网络线程去建立连接。
async-count: 500
-
-
- Consumer最大时延偏高,Producer CPU消耗偏低
-
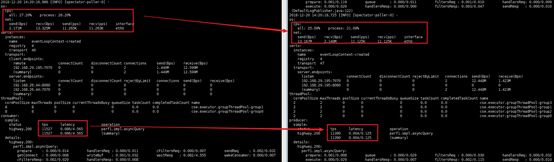
该环境中RSS网络队列只有4个,与CPU数不对等,限制了并发能力,所以Producer CPU偏低
在reactive场景下,网络线程即业务线程,有任何的波动,都会导致最大时延变大
- RESTful
ServiceComb中不同transport切换,只需要修改配置,不需要修改业务代码
Consumer的microservice.yaml中配置
Servicecomb:
references:
transport: rest
sync-count: 500
sync: true
-
- 同步调优
- CPU占用极少,时延超大
- 同步调优
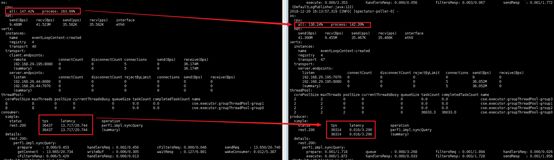
因为默认网络线程只有1,调大网络线程
Consumer:
servicecomb:
rest:
client:
thread-count: 8
Producer:
servicecomb:
rest:
server:
thread-count: 8
-
-
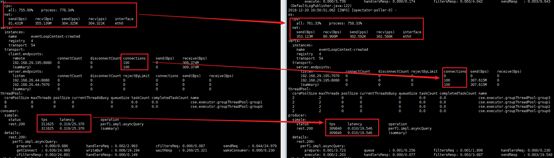
- 连接池耗时较大
-

CPU消耗正常了,TPS提升到15万多,时延仍然较大
主要消耗在从连接池获取连接,默认每个网络线程对每个ip:port建立5个连接,所以共建立了40条连接,而有500个并发请求,考虑扩展连接池。
-
-
- 调用连接池,TPS不变,时延少量降低
-
servicecomb:
rest:
client:
connection:
maxPoolSize: 15
深度每个池连接数为15/30/60等等,TPS在18万左右已经达到上限

降低驱动压力,调整为80时已经可以达到极限TPS
servicecomb:
rest:
client:
connection:
maxPoolSize: 10
sync-count: 80

-
- Reactive调优
直接调大连接池
servicecomb:
rest:
client:
connection:
maxPoolSize: 30
async-count: 500
sync: false

CPU基本耗尽,时延偏大,考虑降低驱动压力到100
servicecomb:
rest:
client:
connection:
maxPoolSize: 15
async-count: 100
- 测试结果汇总
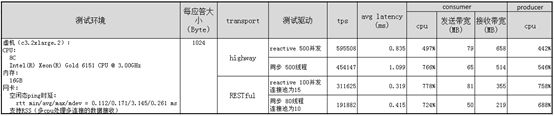
注:
从metrics数据中可以看到,有时os级别的cpu占用反而小于进程级的占用
通过在linux中直接观察top/htop的输出,也有相同的现象,虚机中尤其容易出现,物理机会好一些。
查看top/htop源码,发现htop的算法与top还不一样,htop的计算更容易导致诡异的计算结果。
最新版本的ServiceComb中调整了输出格式,跟top保持一致,进程级的cpu占用按Irix模式展示,os级的cpu占用按Solaris模式展示。