OpenCV人脸识别实验(二)——特征脸(fisherface)及其重构的源代码详解
1、算法介绍
线性鉴别分析在降维的同时考虑类别信息,由统计学家 Sir R. A. Fisher发明。为了找到一种特征组合方式,达到最大的类间离散度和最小的类内离散度。这个想法很简单:在低维表示下,相同的类应该紧紧的聚在一起,而不同的类别尽量距离越远。 后来,把鉴别分析引入到人脸识别问题中。
令x是一个来自c个类中的随机向量,
![]()
散度矩阵 ![]() 和S_{W}如下计算:
和S_{W}如下计算:
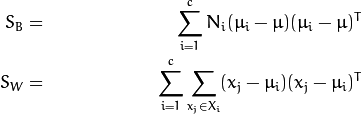
其中 ![]() 是全部数据的均值,
是全部数据的均值,
而![]() 是某个类的均值
是某个类的均值![]() ,
,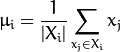
Fisher的分类算法可以看出一个投影矩阵 ![]() ,使得类的可分性最大:
,使得类的可分性最大:
![]()
一个解决这个普通特征值优化问题的方法被提出:
![]()
还有一个问题未解决, Sw的排列最多只有 (N-c), N 个样本和c个类别。在模式识别中,样本数据个数N的大小一般小于输入数据的维数。 使用PCA把数据投影到(N-c)维的子空间,然后再使用线性鉴别分析,因为Sw不是奇异矩阵了(可逆矩阵)。
然后优化问题可以写成:

投影矩阵W,可以把样本投影到(c-1)维的空间上,可以表示为:
![]()
2、代码及实验结果
图片的读取方式依然采用CSV文件,文件名后紧跟一个标签。创建一个CSV文件,at1.txt文件的部分内容的截图如下,后边图片的标签以此类推:

具体代码如下:
#include
#include
#include
#include
#include
#include //文件操作的集合,以流的方式进行
#include //此库定义了stringstream类,即:流的输入输出操作。
//使用string对象代替字符数组,避免缓冲区溢出的危险
using namespace cv;
using namespace std;
using namespace cv::face;
//归一化图像矩阵函数
static Mat norm_0_255(InputArray _src)
{
Mat src = _src.getMat(); //将传入的类型为InputArray的参数转换为Mat的结构
Mat dst; //创建和返回一个归一化后的图像
switch (src.channels())
{
case 1:
normalize(_src, dst, 0, 255, NORM_MINMAX, CV_8UC1);
break;
case 3:
normalize(_src, dst, 0, 255, NORM_MINMAX, CV_8UC3);
break;
default:
src.copyTo(dst);
break;
}
return dst;
}
//使用CSV文件读取图像和标签,主要使用stringstream和getline方法
static void read_csv(const string& filename, vector& images, vector& labels, char separator = ';')
{
ifstream file(filename.c_str(), ifstream::in); //以输入方式打开文件
//c_str()函数将字符串转化为字符数组,返回指针
if (!file)
{
string error_massage = "No valid input file was given,please check the given filename!";
CV_Error(CV_StsBadArg, error_massage);
}
string line, path, classlabel;
while (getline(file, line)) //getline(字符数组,字符个数n,终止标志字符)
{
stringstream liness(line);
getline(liness, path, separator); //遇到分号就结束
getline(liness, classlabel); //继续从分号后边开始,遇到换行结束
if (!path.empty() && !classlabel.empty())
{
images.push_back(imread(path, 0));
labels.push_back(atoi(classlabel.c_str())); //atoi函数将字符串转换为整数值
}
}
}
int main(int argc, const char* argv[])
{
//[1] 检测合法的命令,显示用法
//如果没有参数输入,则退出
//if (argc < 2)
//{
// cout << "usage:" << argv[0] << " " << endl;
// exit(1);
//}
string output_folder;
output_folder = string("D:\\Program Files\\opencv3.0\\opencv\\sources\\data\\FaceData\\result21");
//[2] 读取CSV文件路径
string fn_csv = string("D:\\Program Files\\opencv3.0\\opencv\\sources\\data\\at1.txt");
//两个容器来存放图像数据和对应的标签
vector images;
vector labels;
//读取数据,如果文件不合法就会出错。输入的文件名已经有了
try{
read_csv(fn_csv, images, labels);
}
catch (Exception& e)
{
cerr << "Error opening file" << fn_csv << ".Reason:" << e.msg << endl;
exit(1);
}
//没有读取到足够多的图片,也需要退出
if (images.size() <= 1)
{
string error_message = "This demo need at least 2 images,please add more images to your data set!";
CV_Error(CV_StsError, error_message);
}
//[3] 得到第一张图片的高度,在下面对图像变形得到他们原始大小时需要
int height = images[0].rows;
//[4]下面代码仅从数据集中移除最后一张图片,用于做测试,需要根据自己的需要进行修改
Mat testSample = images[images.size() - 1];
int testLabel = labels[labels.size() - 1];
images.pop_back(); //删除最后一张图片
labels.pop_back(); //删除最后一个标签
//[5] 创建一个特征脸模型用于人脸识别
//通过CSV文件读取的图像和标签训练它
//如果想保留10个fisherfaces,使用如下代码 cv::createFisherFaceRecognizer(10);
//如果希望使用置信度阈值来初始化,使用代码 cv::createFisherFaceRecognizer(10, 123.0);
//如果使用所有特征并使用一个阈值,使用代码 cv::createFisherFaceRecognizer(0, 123.0);
Ptr model = createFisherFaceRecognizer();
model->train(images, labels);
//[6] 对测试图像进行预测,predictedLabel是预测标签结果
int predictedLabel = model->predict(testSample);
// 还有一种调用方式,可以获取结果同时得到阈值:
// int predictedLabel = -1;
// double confidence = 0.0;
// model->predict(testSample, predictedLabel, confidence);
string result_message = format("Predicted class = %d / Actual class = %d.", predictedLabel, testLabel);
cout << result_message << endl;
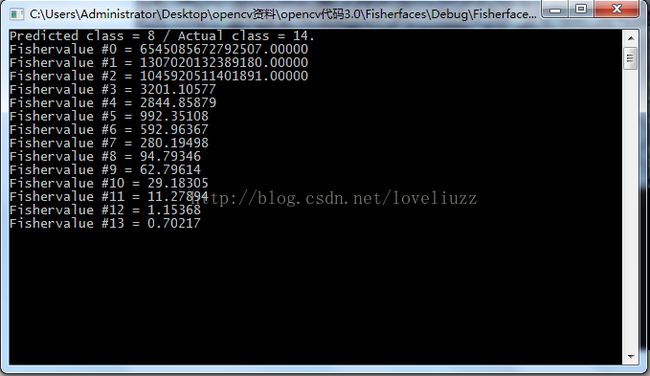
//[7] 如何获取特征脸模型的特征值例子,使用getEigenValues方法
Mat eigenvalues = model->getEigenValues();
//[8] 获取特征向量
Mat W = model->getEigenVectors();
//[9] 得到训练图像的均值向量
Mat mean = model->getMean();
//[10] 显示或保存
imshow("mean", norm_0_255(mean.reshape(1, images[0].rows)));
imwrite(format("%s/mean.png", output_folder.c_str()), norm_0_255(mean.reshape(1, images[0].rows)));
//[11] 显示或保存特征脸
for (int i = 0; i < min(15, W.cols); i++) //修改数值15可以修改特征脸的数目
{
string msg = format("Fishervalue #%d = %.5f", i, eigenvalues.at(i));
cout << msg << endl;
//得到第i个特征向量
Mat ev = W.col(i).clone();
//把它变成原始大小,把数据显示归一化到0-255
Mat grayscale = norm_0_255(ev.reshape(1, height));
//使用Bone伪彩色来显示结果,为了更好的观察
Mat cgrayscale;
applyColorMap(grayscale, cgrayscale, COLORMAP_BONE);
//显示或保存
imshow(format("fisherface_%d", i), cgrayscale);
imwrite(format("%s/fisherface_%d.png", output_folder.c_str(), i), norm_0_255(cgrayscale));
}
//[12] 预测过程中,显示或保存重建后的图像
for (int num_components = min(W.cols, 0); num_components < min(W.cols,15); num_components++) //修改值300可改变重构的图像的数目
{
//从模型中的特征向量截取一部分
Mat evs = W.col(num_components);;
Mat projection = LDA::subspaceProject(evs, mean, images[2].reshape(1, 1)); //投影样本到LDA子空间
Mat reconstruction = LDA::subspaceReconstruct(evs, mean, projection); //重构来自于LDA子空间的投影
//归一化结果
reconstruction = norm_0_255(reconstruction.reshape(1, images[0].rows));
//[13] 若不是存放到文件夹中就显示他,使用暂定等待键盘输入
imshow(format("fisherface_reconstruction_%d", num_components), reconstruction);
imwrite(format("%s/fisherface_reconstruction_%d.png", output_folder.c_str(), num_components), reconstruction);
}
waitKey(0);
return 0;
}
为了更好显示图像效果,使用YaleA人脸数据库。每一个Fisherface都和原始图像有同样长度,它可以被显示成图像。下面显示了14张Fisherfaces图像。

Fisherfaces方法学习一个正对标签的转换矩阵,所依它不会如特征脸那样那么注重光照。鉴别分析是寻找可以区分人的面部特征。需要说明的是,Fisherfaces的性能也很依赖于输入数据。实际上,如果你对光照好的图片上学习
Fisherfaces,而想对不好的光照图片进行识别,那么他可能会找到错误的主元,因为在不好光照图片上,这些特征不优越。这似乎是符合逻辑的,因为这个方法没有机会去学习光照。
Fisherfaces允许对投影图像进行重建,就行特征脸一样。但是由于我们仅仅使用这些特征来区分不同的类别,因此你无法期待对原图像有一个好的重建效果。对于Fisherfaces方法我们将把样本图像逐个投影到Fisherfaces上。特征脸把每个图片看成一个个体,重建时效果也有保证,而Fisherfaces把一个人的照片看成一个整体,那么重建时重建的效果则不是很好。重构的人脸效果图如下:

