acl2018---Aspect Based Sentiment Analysis with Gated Convolutional Networks论文阅读笔记
Abstract
基于Aspect的情感分析(ABSA)能提供比一般情感分析更详细的信息,因为它旨在预测文本中给定的aspect或实体的情感极性。我们把以前的工作总结为两类:aspect分类情感分析(aspect-category sentiment analysis (ACSA)) 和aspect实体情感分析( aspect-term sentiment analysis (ATSA) )。大部分以前的工作使用了LSTM和attenion机制来预测有关目标的情感极性,但是常常模型很复杂并且需要很长的训练时间。我们提出了一个更精确有效的基于卷积神经网络(convolutional neural networks )和门机制( gating mechanisms )的模型。首先一种新的Tanh-ReLU 门单元能够根据给定的aspect或实体选择输出的情感特征。这个结构比应用于现有模型的注意力层简单得多。然后,我们的模型的计算在训练中很容易并行化,因为卷积层不像LSTM层那样有时间依赖性,并且门单元也能够独立的工作。在SemEval 数据集上的实验表明我们工作的效率。
Introduction
在用户生成的评论进行意见挖掘和情绪分析 (庞和李, 2008) 可以为提供商和消费者提供有价值的信息。除了预测整体情绪极性, 基于细粒度方面的情绪分析 (ABSA) (刘和张, 2012) 能够比传统情绪分析更好地理解评论。具体地说, 我们对文本中的aspect类别或目标实体的情绪极性感兴趣。有时, 也会加上aspect实体提取 (薛等, 2017)。有关ABSA已经开发了许多模型, 但有两个不同的子任务, 即aspect分类情绪分析 (ACSA) 和aspect实体的情绪分析 (ATSA)。ACSA 的目标是对于给定的几个预定义的类别之一的aspect预测情绪极性。另一方面, ATSA 的目标是识别文本中出现的目标实体的情绪极性, 这可能是一个多词短语或一个单词。对aspect实体作出贡献的不同词语的数量可能超过1000。例如, 在句子 "Average to good Thai food, but terrible delivery. .", ATSA 会问情绪极性对实体Thai food ;虽然 ACSA 会问aspect情感极性 service , 即使词service 没有出现在句子中。
我们的模型在更少的训练时间下能得到更好的精确度。对于ACSA任务,我们的模型有两个单独的卷积层在embedding层之上,这个embedding层的输出是由新型门单元的组合组成的。有多重过滤器的卷积层能够在每个可接受的领域的许多粒度下有效的抽取n-gram特征。门单元被设计为有两个非线性门,两个中的任何一个都和一个卷积层链接。在给定的aspect信息下,对于情感的预测能够抽取aspect-specific 情感信息。比如说,在句子“Average to good Thai food, but terrible delivery ”中当food这个aspect被提供,门单元能够自动忽视在第二个子句中delivery这个aspect的消极情绪,并且只输出第一个子句的积极情绪。因为模型中的每个组成部分都能够并行,因此比LSTM和attention机制需要更少的训练时间。对于ATSA任务,当这个aspect实体由多个单词组成时,
对于目标表达式我们将我们的模型扩展到包括另一个卷积层。我们评估我们的模型在 SemEval 数据集, 其中包含餐厅和笔记本电脑评论与标签上的方面水平。据我们所知, 迄今为止, 还没有提出基于aspect的情绪分析的基于CNN 模型。
2 Related Work
现有工作主要由以下两方面分析。
2.1 Neural Networks
近年来神经网络非常流行
语法翻译方面:Tree-LSTM ,Recursive Neural Tensor Network
情感分析方面:RNN(比如LSTM和GRU)
NLP:CNN,被证明无需花费太多计算能力就能捕获丰富的语义信息
2.2 Aspect based Sentiment Analysis
ABSA主要分为两种子任务
Aspect-Term Sentiment Analysis.
最近的:
TD-LSTM,gated neural networks 使用两或三层LSTM对目标的左右上下文分别建模。一层有门单元的全连接层在LSTM的输出下预测句子极性
Memory network :由于知识库建立在单个的词向量模型上,因此难以学习到在更复杂的文本中的有附加词的意见词。
Aspect-Category Sentiment Analysis.
Attention-based LSTM 用aspect向量来有选择的参与LSTM生成的表示区域
3 Gated Convolutional Network with Aspect Embedding
我们提出了一个模型名叫Gated Convolutional network with Aspect Embedding (GCAE)
6 Experiments
6.1 Datasets and Experiment Preparation
实验数据集:SemEval(Pontiki et al., 2014),关于餐馆和笔记本电脑的用户评论。
一些现有的工作从从四类情绪标签删除了 "冲突" 的标签, 这使得他们的结果非常好 (Kiritchenko et al., 2014).本文重现了这种比较方法。
在评论数据中, 对句子中不同aspect或目标有不同情绪标签的句子比标准情绪分类更常见。表1中的句子显示了评论者对两个方面的不同态度: 食物和配送。因此, 为了更准确地评估模型对评论句子的执行方式, 我们创建了一些小而困难的数据集, 它们由对不同aspect/目标有相反或不同情绪的句子组成。在表1中, 数据集包括像这样的两个相同的句子, 但有不同的情绪标签。如果一个句子有4个aspect的目标, 这个句子将有4个副本在数据集, 其中每一个副本都与不同的目标和情绪标签相关联。

ACSA任务
我们在SemEva 2014 任务4中的餐馆评论数据中进行实验,有5个aspect :food, price, service, ambience, and misc;4个情感极性:positive,negative, neutral, and conflict。通过合并2014-2016年的餐馆评论,我们得到一个大数据集“Restaurant-Large”。其中不相容的部分在合并时已经被修剪。在2014年的数据中我们将conflict标签用neutral标签替代。在2015和2016年的数据中,一个句子可能有多对“aspect terms”“aspect category”。对于每个句子,用p来表示积极标签的数量减去消极标签的数量的结果。当p>0时我们分配这个句子积极标签,当p<0时消极标签,或者p=0是neutral标签。统计结果如下表2,最后的数据集有8个aspect:restaurant, food, drinks, ambience, service, price, misc and location.

ATSA 任务
我们在SemEva 2014 任务4中的餐馆评论数据中进行实验,在每个数据集中,我们把每个句子复制na次,na等于相应的aspect
categories (ACSA) 或者 aspect terms (ATSA) (Ruder et al., 2016b,a)的数量。统计结果如下表2。
hard data的大小也在表2中展示出来,这个测试集被设计为评估模型是否能够判断同一个句子中对于不同的实体的多个情感极性。没有这个测试集,也许一个全局的情感分类器就足以应对只有一个情感标签的句子了。

然后是一些词向量初始化的介绍
in our experiments, word embedding vectors are initialized with 300-dimension GloVe vectors which are pre-trained on unlabeled data of 840 billion tokens (Pennington et al., 2014). Words out of the vocabulary of GloVe are randomly initialized
with a uniform distribution U(-0:25; 0:25). We use Adagrad (Duchi et al., 2011) with a batch size of 32 instances, default learning rate of 1e-2, and maximal epochs of 30. We only fine tune early stopping with 5-fold cross validation on training datasets. All neural models are implemented in PyTorch.
6.3 Results and Analysis
6.3.1 ACSA

6.3.2 ATSA

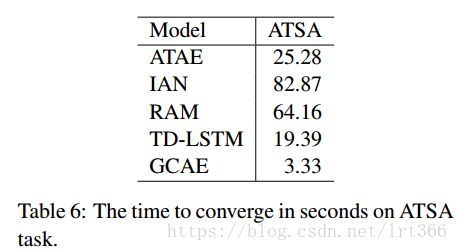
6.4 Training Time
6.5 Gating Mechanisms

7 Visualization

8 Conclusions and Future Work
本文提出了一种高效的卷积神经网络来处理 ACSA 和 ATSA 任务。GTRU 可以根据给定的方面信息有效地控制情绪流, 两个卷积层分别对aspect和情绪信息进行建模。通过对 SemEval 数据集的广泛实验, 证明了与其它神经模型相比, 性能的改进。如何利用神经网络中的大规模情绪词汇是我们未来的工作