caffe-windows快速配置和测试训练教程
下载资源和数据
1、下载微软官方caffe-windows解压到F盘根目录。这个版本好处待会会说。点我进入Git下载
2、Cuda SDK。这里以Cuda7.5为例。解压到caffe-windows目录。点我进入官网下载
3、下载cuDNN。同样用7.5版本。点我进入官网下载。官网下载可能需要你注册,忍一下吧。
4、下载用于训练手写数字识别模型LeNet的mnist数据集。点我官网下载
编译caffe-windows
1、解压caffe-windows后,找到windows\CommonSettings.props.example文件,重命名为CommonSettings.props文件。然后重点找到下面几个属性进行修改。
<CpuOnlyBuild>falseCpuOnlyBuild>
<UseCuDNN>trueUseCuDNN>
<CudaVersion>7.5CudaVersion>
<CudaArchitecture>compute_30,sm_30CudaArchitecture>
<CuDnnPath>F:\caffe-masterCuDnnPath> 说明如下:
- CpuOnlyBuild: 指明只使用CPU。我们这里使用GPU,因此输入false。
- UseCuDNN: 指明使用GPU。因此输入true。显然和CpuOnlyBuild必然不能同真。
- CudaVersion: 你的cuda版本号!
- CudaArchitecture: 对应你的GPU的Cuda计算能力!请使用GPU-Z工具查看,鼠标放到CUDA单选框上即可。如下图所示。我这里是3.0.
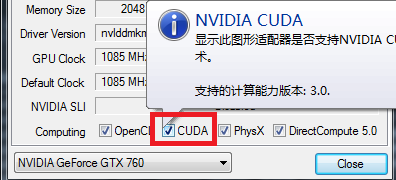
- CuDnnPath: 指明cuDNN的存放目录。注意是cuda目录的父目录!
2、使用Visual Studio 2013打开.\windows\Caffe.sln,编译之前请一定确认以下几个事项:
- 编译选项设置为Release,X64;
- ibcaffe工程属性→配置属性→C/C++→常规→将警告视为错误修改为“否”;
- libcaffe工程属性 →配置属性→ CUDA C/C++→Device →Code Generation中的CudaArchitecture确实设置正确(符合你的GPU计算能力);
3、开始编译解决方案。如果出现如下错误:
E:\NugetPackages\boost.1.59.0.0\lib\native\include\boost/format/alt_sstream_impl.hpp : error C2220: 警告被视为错误 - 没有生成“object”文件 (….\src\caffe\util\math_functions.cpp)
不要慌,编码方式问题而已。打开该文件,保存一下即可 1。
4、微软官方版本的好处是微软使用NuGet管理第三方开发包,编译过程会自动帮你下载一大堆依赖库到../NugetPackages目录中。因此可能会比较慢,但是毕竟方便。
5、全部生成成功后,caffe.exe等文件存放在.\Build\x64\Release目录中。
训练第一个手写数字识别网络——LeNet!
1、解压数据。
把下载好的mnist数据集解压到.\examples\mnist\mnist_data目录,可以看到其解压后由4个ubyte文件组成。
2、转换数据。
caffe必须将其转换成lmdb或者leveldb文件才能进行训练。在.\examples\mnist下新建一个Convert_Mnist_Data.bat文件,输入:
..\..\Build\x64\Release\convert_mnist_data.exe --backend=lmdb mnist_data\train-images.idx3-ubyte mnist_data\train-labels.idx1-ubyte mnist_train_lmdb
..\..\Build\x64\Release\convert_mnist_data.exe --backend=lmdb mnist_data\t10k-images.idx3-ubyte mnist_data\t10k-labels.idx1-ubyte mnist_test_lmdb
pause运行成功后,就把mnist的训练数据和测试数据转换成了lmdb文件。注意其存放于.\examples\mnist下的mnist_test_lmdb和mnist_train_lmdb目录中。
3、计算训练数据均值。
在.\examples\mnist下新建一个Create_Mean.bat文件,输入:
..\..\Build\x64\Release\compute_image_mean.exe mnist_train_lmdb mean.binaryproto --backend=lmdb
Pause运行成功后,当前目录会生成一个mean.binaryproto均值文件。训练中会用到。
4、修改LeNet网络描述文件
打开.\examples\mnist目录下的lenet_train_test.prototxt文件,查找transform_param属性,在其中加入一行代码,指定均值文件:
transform_param {
mean_file: "mean.binaryproto"
scale: 0.00390625
}打开.\examples\mnist目录下的lenet_solver.prototxt文件,注意最后几行:
snapshot_prefix: "examples/mnist/lenet"
# solver mode: CPU or GPU
solver_mode: GPU- snapshot_prefix: 目录前缀,由于我们接下来会在examples\mnist目录下写一个bat来训练LeNet,因此,这里把目录修改为”lenet”即可。
- solver_mode: 指定使用GPU进行训练。你可以改为CPU来体验龟速训练。
5、开始训练
在.\examples\mnist下新建一个Train_Mnist.bat文件,输入:
..\..\Build\x64\Release\caffe.exe train --solver=lenet_solver.prototxt
pause使用GPU的话大概不到1分钟即可训练完毕,最后收敛时准确率在0.991左右。
测试自己的手写数字!
是不是迫不及待的想自己写几个数字让LeNet来识别了呢?部分博主提供了使用matlab转灰度图的方法2。这里我提供更加简单粗暴的方法如下:
1、使用画图程序,画布大小调整为较小的正方形即可;
2、使用墨水工具把背景涂成黑色;
3、铅笔手写一个数字,然后另存为单色位图即可,命名为0.bmp。如下图所示:
4、将图片存放到examples\mnist\mytest下。然后在该目录下新建一个标签描述文件label.txt,里面输入:
0
1
2
3
4
5
6
7
8
9 5、在.\examples\mnist下新建一个MyTest.bat文件,输入:
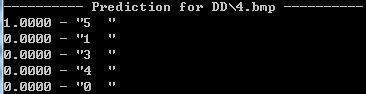
..\..\Build\x64\Release\classification.exe lenet.prototxt lenet_iter_10000.caffemodel mean.binaryproto mytest\label.txt mytest\0.bmp
pause应该可以看到如下结果:
最后感谢其他网友提供的Check fail错误解决方案3,以及其他对mnist数据集4和Cifar数据集的训练教程5。