R&Python Data Science 系列:数据处理(2)
承接继续介绍剩余的函数。
1 衍生字段函数
主要有两个函数,mutate()和transmute(),两个函数在Python和R上使用方法相同,这两个函数本身有点区别:mutate()函数保留原来所有列,然后新增一列;transmute()只保留新增的一列:
python实现
from dfply import *
import numpy as np
import pandas as pd
##新增列x+y、x*y*z,mutate()函数
diamonds >> mutate(x_plus_y = X.x + X.y, xyz = X.x*X.y*X.z) >> head(5)
##新增列x+y、x*y*z,transmute()函数
diamonds >> transmute(x_plus_y = X.x + X.y, xyz = X.x*X.y*X.z) >> head(5)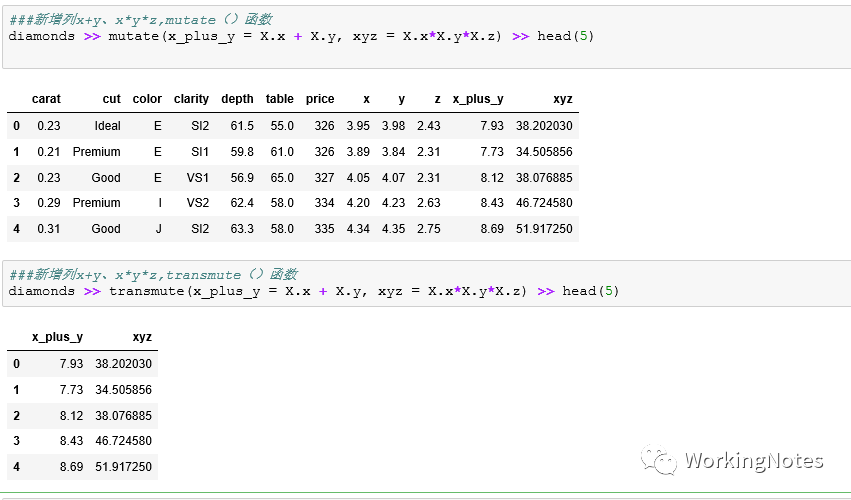
R语言实现
library(dplyr)
library(ggplot2)
library(tidyr)
##新增列x+y、x*y*z,mutate()函数
diamonds %>% mutate(x_plus_y = x + y, xyz = x*y*z) %>% head(5)
##新增列x+y、x*y*z,transmute()函数
diamonds %>% transmute(x_plus_y = x + y, xyz = x*y*z) %>% head(5)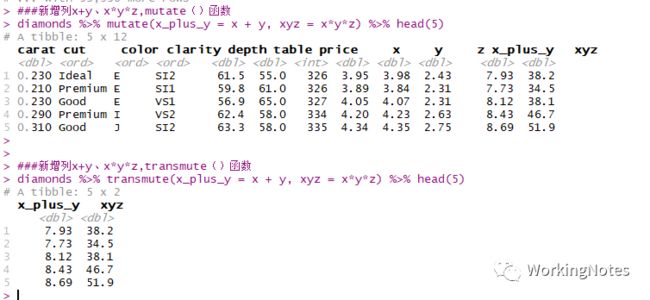
2 条件函数
这里介绍3个条件函数,if_else()、case_when()、between()函数,Python包dfply和R包dplyr中都是这3个函数,在用法上有点细微差别,日常中使用最多,在构建评分卡woe赋值的时候特别好用。
2.1 if_else函数
非A即B函数:
Python实现
##如果钻石价格大于2000,则钻石等级为A,其他为A-
diamonds >> mutate(price_class = if_else(X.price > 2000, 'A', 'A-')) >> distinct(X.price_class)
而且if_else()函数可以嵌套使用,不过当条件判断超过2个的时候,建议使用case_when()函数。
##如果钻石价格大于2000,则钻石等级为A,1500-2000为A-, 1500以下为A--
(diamonds >>
mutate(price_class = if_else(X.price > 2000, 'A', if_else(X.price > 1500,'A-', 'A--'))) >>
distinct(X.price_class) >>
select(X.price_class))
R语言实现
##如果钻石价格大于2000,则钻石等级为A,其他为A-
diamonds %>%
mutate(price_class = if_else(price > 2000, 'A', 'A-')) %>%
distinct(price_class)
##如果钻石价格大于2000,则钻石等级为A,1500-2000为A-, 1500以下为A--
diamonds %>%
mutate(price_class = if_else(price > 2000, 'A', if_else(price > 1500,'A-', 'A--'))) %>%
distinct(price_class)
注意:python在jupyter中使用管道函数换行书写代码的时候需要用()把代码括起来。
2.2 case_when函数
用于多条件赋值,评分卡Woe赋值的时候使用起来很方便。
python实现
##如果钻石价格大于2000,则钻石等级为A,1500-2000为B, 1000-1500以下为C,1000以下为D
(diamonds >>
mutate(price_class = case_when([X.price > 2000, 'A'],
[X.price > 1500 , 'B'],
[X.price > 1000, 'C'],
[True, 'D'])) >>
distinct(X.price_class) >>
select(X.price_class))
R语言实现
##如果钻石价格大于2000,则钻石等级为A,1500-2000为B, 1000-1500以下为C,1000以下为D
diamonds %>% mutate(price_class = case_when(price > 2000 ~ 'A',
price > 1500 ~ 'B',
price > 1000 ~ 'C',
TRUE ~ 'D')) %>%
distinct(price_class)
注意:case_when函数在Python和R语言中使用的时候有点区别,请留意。
2.3 between函数
区间判断条件函数,为闭区间[a,b]
python实现
##如果钻石价格大于2000,则钻石等级为A,1500-2000为B, 1000-1500以下为C,1000以下为D
(diamonds >>
mutate(price_class = case_when([X.price > 2000, 'A'],
[between(X.price,1500,2000) , 'B'],
[between(X.price,1000,1500), 'C'],
[True, 'D'])) >>
select(X.price_class) >>
distinct(X.price_class))
R语言实现
##如果钻石价格大于2000,则钻石等级为A,1500-2000为B, 1000-1500以下为C,1000以下为D
diamonds %>% mutate(price_class = case_when(price > 2000 ~ 'A',
between(price,1500,2000) ~ 'B',
between(price,1000,1500) ~ 'C',
TRUE ~ 'D')) %>%
distinct(price_class)
3 bind函数
两个函数:bind_rows()行拼接;bind_cols()列拼接:
Python实现
###bind_rows()函数
diamonds2 = diamonds >> head(2)
diamonds3 = diamonds >> tail(3)
diamonds2 >> bind_rows(diamonds3)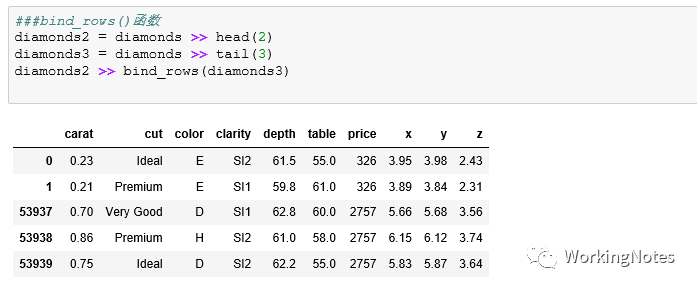
##bind_cols()函数
diamonds4 = diamonds >> select(1, X.carat, 'cut', -1)
diamonds5 = diamonds >> select('x', 'y')
diamonds4 >> bind_cols(diamonds5) >> head(5)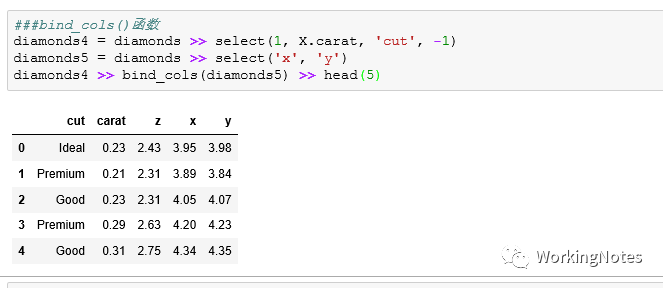
R语言实现
##bind_rows()函数
diamonds2 = diamonds %>% head(2)
diamonds3 = diamonds %>% tail(3)
diamonds2 %>% bind_rows(diamonds3)
##bind_cols()函数
diamonds4 = diamonds %>% select(1, carat, cut, dim(diamonds)[2])
diamonds5 = diamonds %>% select(x, y)
diamonds4 %>% bind_cols(diamonds5) %>% head(5)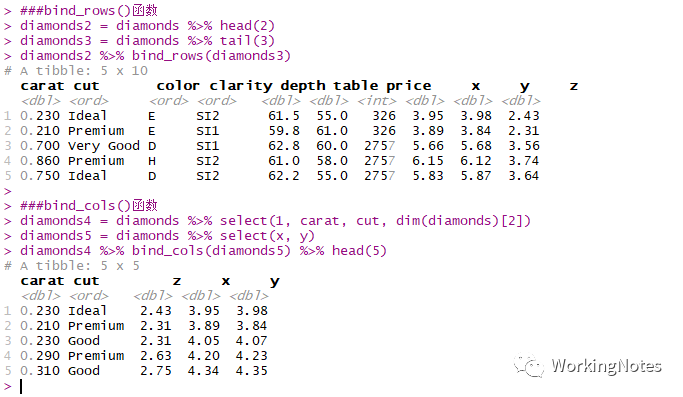
4 连接函数
这里主要介绍inner_join()、left_join()和rigth_join()三个函数
Python实现
a = pd.DataFrame({
'x1':['A','B','C'],
'x2':[1,2,3]
})
b = pd.DataFrame({
'x1':['A','B','D'],
'x3':[True,False,True]
})##inner_join函数
a >> inner_join(b, by='x1')
##left_join函数
a >> left_join(b, by='x1')
##right_join函数
a >> right_join(b, by='x1')
R语言实现
a = data.frame(x1 = c('A', 'B', 'C'), B = c(1, 2, 3))
b = data.frame(x1 = c('A', 'B', 'D'), D = c(TRUE, FALSE, TRUE))
##inner_join函数
a %>% inner_join(b, by = 'x1') ##或者inner_join(a, b, by = 'x1')
##left_join函数
a %>% left_join(b, by = 'x1') ##或者left_join(a, b, by = 'x1')
##right_join函数
a %>% right_join(b, by = 'x1') ##或者rigth_join(a, b, by = 'x1')
注意:R语言中可以使用XXX_join(a,b,by),Python中不可以使用。