docker 部署rabbitmq,k8s部署rabbitmq集群,跟踪和监控rabbitmq
全栈工程师开发手册 (作者:栾鹏)
架构系列文章
rabbit原理和架构可以参考https://blog.csdn.net/luanpeng825485697/article/details/82082751
docker部署rabbitmq
在docker环境部署RabbitMQ
RabbitMQ是用 Erlang 编写的,直接部署的话需要先部署 Erlang 环境,比较麻烦。在 docker 环境下部署就比较简单了,直接使用rabbitmq官方提供的镜像即可。
登录 docker 节点,运行
docker pull rabbitmq:management
这里使用的是带 web 管理插件的镜像。
或者我们可以自己封装镜像,以方便扩展
Dockerfile文件内容如下
FROM rabbitmq:management
# 启用记录插件
RUN rabbitmq-plugins enable rabbitmq_tracing
运行下面的命令进行封装。本次封装的内容为日志跟踪,在页面的admin中有tracking,创建跟踪以后会自动订阅消息,保存在日志文件中。这样可以方便查看历史消息。
# docker build -t luanpeng/lp:rabbitmq-management .
启动容器:
docker run -d --name rabbitmq --publish 5671:5671 -p 5672:5672 -p 4369:4369 -p 25672:25672 -p 15671:15671 -p 15672:15672 rabbitmq:management
容器启动之后就可以访问web 管理端了 http://127.0.0.1:15672,默认创建了一个 guest 用户,密码也是 guest。
好了,RabbitMQ已经启动成功了,然后我们来实践一下。
先添加两个Exchange(camera_exchange、screen_exchange)和两个queue(carema_queue、screen_queue)都选择topic模式
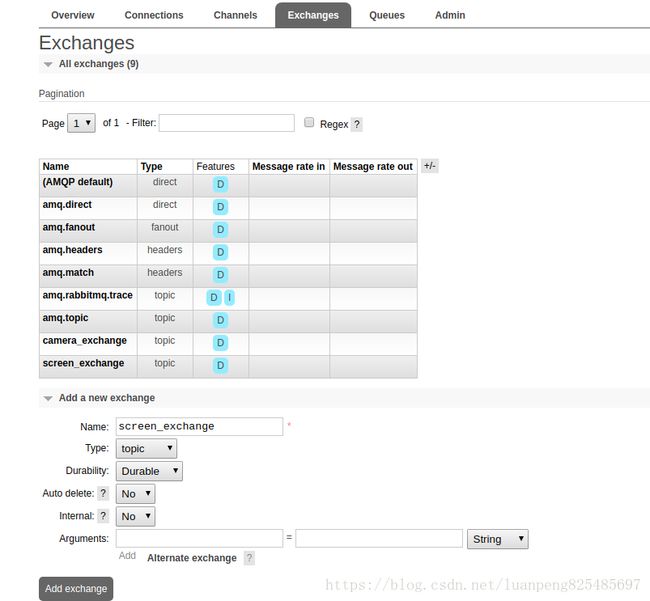
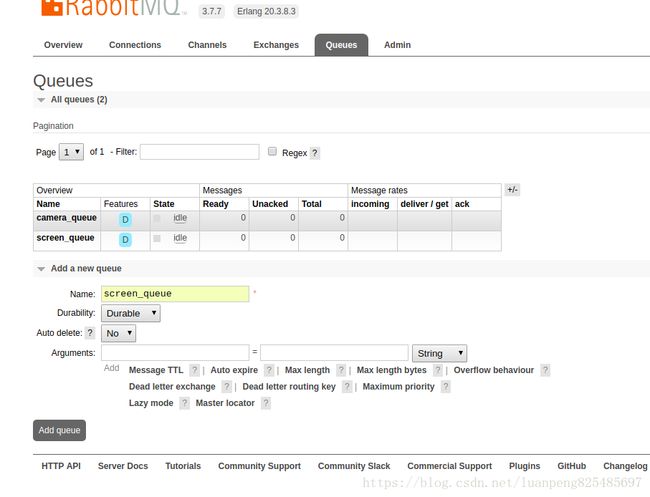
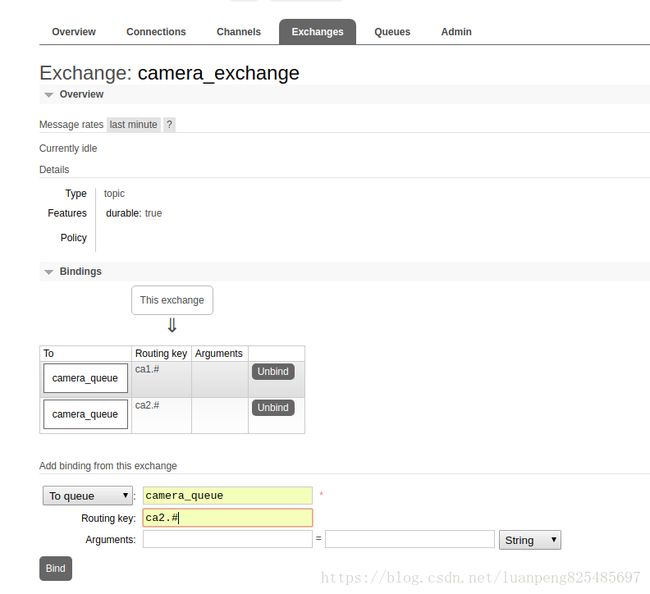
为camera_exchange绑定camera_queue,并绑定两个路由(过滤条件)ca1.#和ca2.#
为screen_exchange绑定screen_queue,并绑定两个路由(过滤条件)sc1.#和sc2.#
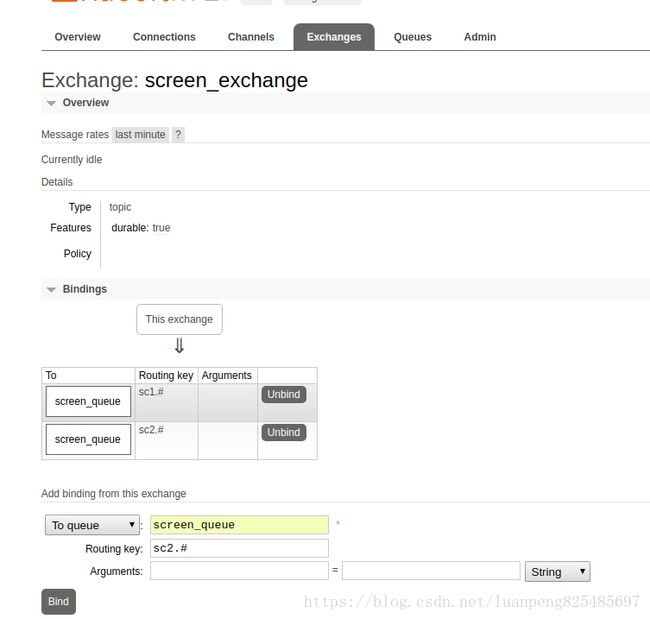
exchange和queue可以多对多绑定。
这样就可以在exchange中发送消息了。消息包含key(Routing key)和message(Payload)。exchange接收消息后通过key值选择将消息发送到哪个queue。
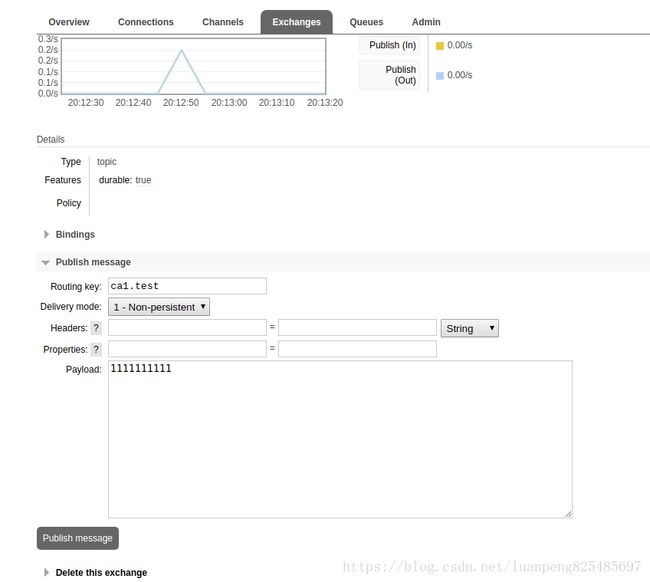
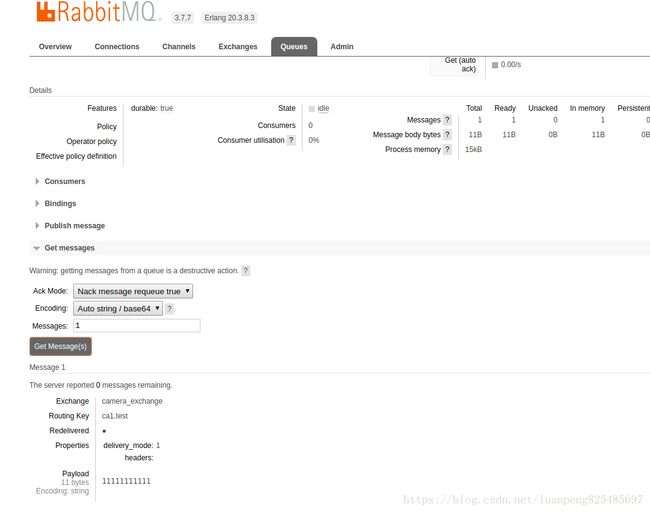
在queue中接收消息
k8s部署rabbit集群
消息中间件rabbitmq,一般以集群方式部署,主要提供消息的接受和发送,实现各微服务之间的消息异步。本篇将以rabbitmq+HA方式进行部署。
一、原理介绍
rabbitmq是依据erlang的分布式特性(RabbitMQ底层是通过Erlang架构来实现的,所以rabbitmqctl会启动Erlang节点,并基于Erlang节点来使用Erlang系统连接RabbitMQ节点,在连接过程中需要正确的Erlang Cookie和节点名称,Erlang节点通过交换Erlang Cookie以获得认证)来实现的,所以部署rabbitmq分布式集群时要先安装erlang,并把其中一个服务的cookie复制到另外的节点。
rabbitmq集群中,各个rabbitmq为对等节点,即每个节点均提供给客户端连接,进行消息的接收和发送。节点分为内存节点和磁盘节点,一般的,均应建立为磁盘节点,为了防止机器重启后的消息消失;
RabbitMQ的Cluster集群模式一般分为两种,普通模式和镜像模式。消息队列通过rabbitmq HA镜像队列进行消息队列实体复制。
普通模式下,以两个节点(rabbit01、rabbit02)为例来进行说明。对于Queue来说,消息实体只存在于其中一个节点rabbit01(或者rabbit02),rabbit01和rabbit02两个节点仅有相同的元数据,即队列的结构。当消息进入rabbit01节点的Queue后,consumer从rabbit02节点消费时,RabbitMQ会临时在rabbit01、rabbit02间进行消息传输,把A中的消息实体取出并经过B发送给consumer。所以consumer应尽量连接每一个节点,从中取消息。即对于同一个逻辑队列,要在多个节点建立物理Queue。否则无论consumer连rabbit01或rabbit02,出口总在rabbit01,会产生瓶颈。
镜像模式下,将需要消费的队列变为镜像队列,存在于多个节点,这样就可以实现RabbitMQ的HA高可用性。作用就是消息实体会主动在镜像节点之间实现同步,而不是像普通模式那样,在consumer消费数据时临时读取。缺点就是,集群内部的同步通讯会占用大量的网络带宽。
二、集群部署方案
本方案中是在多台机器之间部署rabbitmq的cluster,要求如下:这几个节点需要在同一个局域网内;这几个节点需要有相同的erlang cookie,否则不能正常通信,为了实现cookie内容一致,采用scp的方式进行。
这里仍然使用上面的镜像rabbitmq:management,因为上面的镜像中已经安装了erlang和rabbit
rabbit在目录/usr/lib/rabbitmq中
erlang在目录/usr/lib/erlang中
设置erlang
找到erlang cookie文件的位置,官方在介绍集群的文档中提到过.erlang.cookie一般会存在这两个地址:第一个是$home/.erlang.cookie;第二个地方就是/var/lib/rabbitmq/.erlang.cookie。如果我们使用解压缩方式安装部署的rabbitmq,那么这个文件会在${home}目录下,也就是$home/.erlang.cookie。如果我们使用rpm等安装包方式进行安装的,那么这个文件会在/var/lib/rabbitmq目录下。
在rabbitmq:management镜像查看文件
cat ~/.erlang.cookie
这里将 node1 的该文件复制到 node2、node3,注意这个文件的权限是 400(默认即是400),因此采用scp的方式只拷贝内容即可;
可以通过cat $~/.erlang.cookie来查看三台机器的cookie是否一致,设置erlang的目的是要保证集群内的cookie内容一致。
k8s部署
首先说明一下,rabbitmq是使用autocluster插件去调用kubernetes apiserver获取rabbitmq服务的endpoints获取node节点信息,并加入集群的。下面开始操作:
# 集群中的每个rabbitmq都要是相同的cookie
echo $(openssl rand -base64 32) > erlang.cookie
kubectl create secret generic erlang.cookie --from-file=erlang.cookie -n cloudai-2
kubectl create -f rabbitmq-serviceAccount.yaml
kubectl create -f rabbitmq-service.yaml
kubectl create -f rabbitmq-deployment.yaml
其中rabbitmq-serviceAccount.yaml为
---
apiVersion: v1
kind: ServiceAccount # 也就是pod在k8s中的角色。kubectl是admin角色。Service Account 是 Kubernetes 用于集群内运行的程序,进行服务发现时调用 API 的帐号,帐号的 token 会直接挂载到 Pod 中,可以供程序直接使用。
metadata:
name: rabbitmq
namespace: cloudai-2
---
kind: Role
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
name: rabbitmq
namespace: cloudai-2
rules:
- apiGroups:
- ""
resources:
- endpoints
verbs:
- get
---
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
name: rabbitmq
namespace: cloudai-2
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: rabbitmq
subjects:
- kind: ServiceAccount
name: rabbitmq
namespace: cloudai-2
rabbitmq-service.yaml文件为
apiVersion: v1
kind: Service
metadata:
labels:
app: rabbitmq
name: rabbitmq
namespace: cloudai-2
spec:
ports:
- port: 5672
name: port-5672
protocol: TCP
targetPort: 5672
- port: 4369
name: port-4369
protocol: TCP
targetPort: 4369
- port: 5671
name: port-5671
protocol: TCP
targetPort: 5671
- port: 15672
name: port-15672
protocol: TCP
targetPort: 15672
- port: 25672
name: port-25672
protocol: TCP
targetPort: 25672
selector:
app: rabbitmq # 选择pod
externalIPs:
- 192.168.2.177 # 这里要更改一下,只在指定的外部ip上监听,而非像nodeport所有节点监听. 只用externalIPs:port 访问
rabbitmq-deployment.yaml文件为
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: rabbitmq
namespace: cloudai-2
labels:
app: rabbitmq
version: v1.0.0
spec:
selector:
matchLabels:
app: rabbitmq
version: v1.0.0
replicas: 1
template:
metadata:
labels:
app: rabbitmq
version: v1.0.0
spec:
serviceAccountName: rabbitmq
volumes:
- name: tz-config
hostPath:
path: /usr/share/zoneinfo/Asia/Shanghai
- name: config-path
persistentVolumeClaim:
claimName: pvc-rabbirmq
containers:
- name: rabbitmq
image: rabbitmq:management
imagePullPolicy: IfNotPresent
ports:
- containerPort: 5672
name: port-5672
- containerPort: 4369
name: port-4369
- containerPort: 5671
name: port-5671
- containerPort: 15672
name: port-15672
- containerPort: 25672
name: port-25672
env:
- name: AUTOCLUSTER_TYPE
value: "k8s"
- name: AUTOCLUSTER_DELAY
value: "10"
- name: AUTOCLUSTER_CLEANUP
value: "true"
- name: RABBITMQ_DEFAULT_USER
value: intellif # 连接rabbit的账号
- name: RABBITMQ_DEFAULT_PASS
value: introcks #连接rabbit的密码
- name: HOSTNAME
valueFrom:
fieldRef:
fieldPath: status.podIP
- name: MY_POD_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
- name: CLEANUP_INTERVAL
value: "60"
- name: CLEANUP_WARN_ONLY
value: "false"
- name: K8S_SERVICE_NAME
value: "rabbitmq"
- name: K8S_ADDRESS_TYPE
value: "hostname"
- name: K8S_HOSTNAME_SUFFIX
value: ".$(K8S_SERVICE_NAME)"
- name: RABBITMQ_USE_LONGNAME
value: "true"
- name: K8S_HOST
value: "192.168.0.52" # 修改ip,因为
- name: K8S_PORT # 修改端口号
value: "6443"
- name: RABBITMQ_ERLANG_COOKIE
valueFrom:
secretKeyRef:
name: erlang.cookie
key: erlang.cookie
resources:
limits:
cpu: 500m
memory: 1024Mi
requests:
cpu: 10m
memory: 100Mi
volumeMounts:
- name: tz-config
mountPath: /etc/localtime
- name: config-path
mountPath: /var/lib/rabbitmq
部署高可用的rabbitmq
我们上面部署pod仅部署了一遍, pod重启, rabbitmq的元消息会丢失, 如果部署高可用的rabbit.
参考:https://www.kubernetes.org.cn/2629.html
REST API
有时需要初始化一些列队列和交换器,每次部署一套新环境后,都需要一步一步创建会有点麻烦,通过REST API可方便的实现自动化脚本。
当启用web管理插件后,不仅获得了WEB UI,也拥一个REST化的WEB管理API,任何语言或脚本只要有HTTP库,都能调用。
接口会返回json串,比如获取所有队列:
curl -i -u admin:admin http://xx.xx.xx.xx:15672/api/queues
会返回一个json数组,每个元素是一个队列,包含队列的各种属性:
[{"arguments":{},"auto_delete":false,"backing_queue_status":{"avg_ack_egress_rate":0.0,"avg_ack_ingress_rate":0.0,"avg_egress_rate":0.0,"avg_ingress_rate":0.0,"delta":["delta","undefined",0,0,"undefined"],"len":0,"mode":"default","next_seq_id":0,"q1":0,"q2":0,"q3":0,"q4":0,"target_ram_count":0},"consumer_utilisation":null,"consumers":1,"durable":false,"effective_policy_definition":[],"exclusive":true,"exclusive_consumer_tag":null,"garbage_collection":{"fullsweep_after":65535,"max_heap_size":0,"min_bin_vheap_size":46422,"min_heap_size":233,"minor_gcs":291},"head_message_timestamp":null,"idle_since":"2019-02-28 ..
...
要想知道rest能获取什么样的数据,和,他们具有什么样的接口,可以参考
http://xx.xx.xx.xx:15672/api/index.html
注意:在该界面看到的接口,斜体表示变量,需要自己根据需要更改。
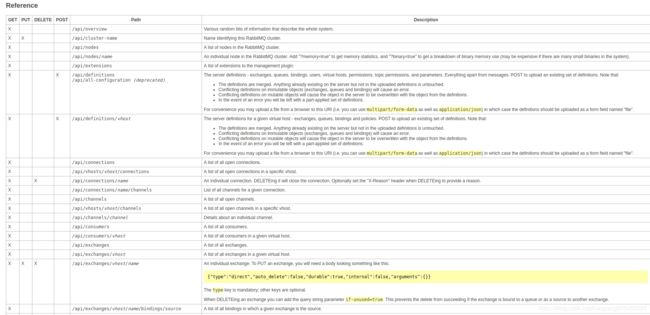
rabbitmqadmin脚本
另外,还提供了rabbitmqadmin脚本的方式查看元数据信息和一些统计数据,它会包装REST API,使用干净的接口与其交互,而且输出内容也是格式化过的,方便我们查看。
比如查看所有队列,可以这样写:
./rabbitmqadmin list queues
会返回如下结果:
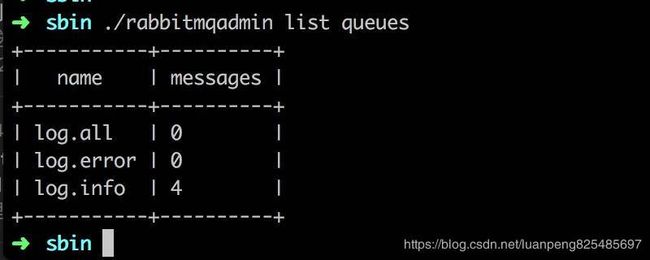
监控
监控RabbitMQ并不只是确保端口5672是开启的并能接收TCP连接而已,还要能够模拟AMQP客户端来确保连接之后获取信道,如果能使用REST API找出是否所有构成RabbitMQ部件都正常运行,并且之间能正常通信,就更好了。
监控RabbitMQ的各个方面,比如:监控Rabbit内部状态、确认RabbitMQ可用并且能够响应、观察队列状态检测消费者异常、检测消息通信结构中不合需求的配置更改等。
采用RabbitMQ提供的restful http api来做监控其实很简单,只需调用(比如HttpClient工具):http://server-ip:15672/api/nodes即可。下面展示下博主这里的某些监控指标:broker节点的内存占用,磁盘剩余空间,Socket句柄,Broker子进程数,文件句柄数。