solrcloud 7.5在k8s上的部署安装和使用教程
网易公开课,开课啦!
主讲内容:docker/kubernetes 云原生技术,大数据架构,分布式微服务,自动化测试、运维。
7月1号-7月29号 8折优惠!!!
7月1号-7月29号 8折优惠!!!
7月1号-7月29号 8折优惠!!!
全栈工程师开发手册 (作者:栾鹏)
架构系列文章
solr的docker hub 官网:https://hub.docker.com/_/solr/
solr简介
Apache Solr支持不同格式,例如数据库,PDF文件,XML文件,CSV文件。
7.5版本的主要升级内容:https://www.w3cschool.cn/solr_doc/solr_doc-s4kg2fp6.html
为什么选择Apache Solr
Apache Solr是搜索服务器,提供REST风格API。
Solr基于Lucene。
使用 Apache Zookeeper针对高流量进行优化。
Solr功能
先进的全文搜索功能。
XML,JSON和HTTP - 基于开放接口标准。
高度可扩展和容错。
同时支持模式和无模式配置。
分页搜索和过滤。
支持许多主要语言
丰富的文档。
k8s 部署分布式solr
先重构了一下镜像,以便满足下面的需求
FROM solr:7.5
# 扩展数据源
COPY mysql-connector-java-8.0.15.jar /opt/solr/server/solr-webapp/webapp/WEB-INF/lib/
COPY protobuf-java-3.6.1.jar /opt/solr/server/solr-webapp/webapp/WEB-INF/lib/
# 扩展分词器
COPY ikanalyzer/* /opt/solr/server/solr-webapp/webapp/WEB-INF/lib/
RUN mkdir -p /opt/solr/server/solr-webapp/webapp/WEB-INF/classes
COPY ikanalyzer/* /opt/solr/server/solr-webapp/webapp/WEB-INF/classes/
Solr将其核心数据存储在server/solr目录的每个核心的子目录中。该server/solr目录还包含属于Solr分发的配置文件。所以如果想在k8s中持久化,需要添加挂载。
Solr支持SOLR_HOME环境变量以指向Solr主目录的非标准位置。
这里我们使用外部zookeeper,zk下的/solr路径,所以需要我们先在zookeeper中创建这个节点
/opt/zookeeper/bin/zkCli.sh create /solr solr
如果想删除可以使用
/opt/zookeeper/bin/zkCli.sh delete /solr
k8s的文件地址在github上:
如果是docker 启动我们可以设置zookeeper的地址
/bin/bash -c 'solr start -f -z $ZK_PORT_2181_TCP_ADDR:$ZK_PORT_2181_TCP_PORT'
启动后,可以访问8983端口对应的nodeport,访问solr的web界面
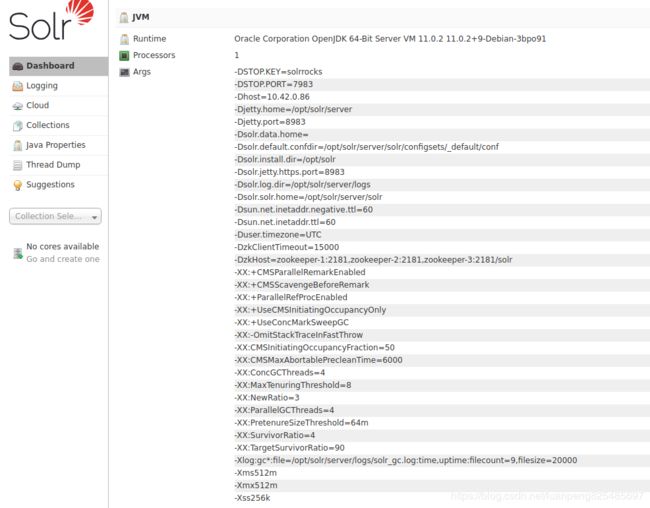
从图片中可以看到solr.home为/opt/solr/server/solr,安装目录为install.dir=/opt/solr
逻辑概念
- 一个群集可以托管多个Solr文档集合。
- 一个集合可以划分为多个Shards,其中每个Shards包含Collection中的Documents的一个子集。
- Collection的Shards数量由下面的因素决定:
- 单个搜索请求可能的并发数目
- Collection可合理包含的文档数量的理论限制值
物理概念
- 群集由一个或多个Solr节点组成,这些节点正在运行Solr服务器进程的实例。
- 每个节点可以托管多个核心。
- 群集中的每个Core都是逻辑分片的物理副本。
- 每个副本为其所属的Collection指定的相同配置。
- 每个Shard的副本数目由下面的因素决定:
- 集群中内置的冗余级别以及在某些节点不可用时集群可以容错的程度。
- 可以在高负载下处理的并发搜索请求数量的理论限制。
建立核心(core)
Solr服务器的配置在独立模式下称为核心。在集群模式下叫做集合collections。因为有了配置才能建立数据存储搜索的服务。
core简介:简单说core就是solr的一个实例,一个solr服务下可以有多个core,每个core下都有自己的索引库和与之相应的配置文件,所以在操作solr创建索引之前要创建一个core,因为索引都存在core下面。
第一种方式:
1、打开pod的dos命令窗口,切换目录到${solr.home}\bin,然后输入:solr create -c corename之后回车;
2、打开solr安装文件,在/opt/solr/server/solr下就会出现新的文件夹corename(就是新创建的core);
3、打开浏览器,输入solr访问路径:http://xxx.xxx.xxx:8983/solr,就会看到新建的core
命令解释:
solr create:
-c :要创建的核心或集合的名称(必需)。
-d :配置目录,在SolrCloud模式非常有用。默认在server/solr/目录下面创建
-n :配置名称。这将默认为核心或集合的名称。
-p :本地Solr的实例的端口发送create命令; 默认脚本试图通过寻找运行Solr的实例来检测端口。
-s :Number of shards to split a collection into, default is 1.
-rf :集合中的每个文件的份数。默认值是1。
要想指定配置目录,需要提前创建配置目录和配置文件。
创建核心需要先创建目录
solr@solr-c5bccd9f6-bwss5:/opt/solr/server/solr$ mkdir newcore
solr@solr-c5bccd9f6-bwss5:/opt/solr/server/solr$ cd newcore/
solr@solr-c5bccd9f6-bwss5:/opt/solr/server/solr/newcore$ mkdir conf
solr@solr-c5bccd9f6-bwss5:/opt/solr/server/solr/newcore$ cp -r ../server/solr/configsets/_default/conf/* ./conf/
solr@solr-c5bccd9f6-bwss5:/opt/solr/server/solr/newcore$ cp -r ../contrib/ ./
solr@solr-c5bccd9f6-bwss5:/opt/solr/server/solr/newcore$ cp -r ../dist/ ./
第二次创建core,就不用这么麻烦了,直接把第一次创建的newcore目录复制一份,修改core.properties文件中的name 即可。
使用核心名称和配置目录-d参数-c参数。对于所有其它参数使用默认设置。
/opt/solr$ bin/solr create -c newcore -d ./server/solr/newcore
create命令会将newcore配置目录的副本上传到ZooKeeper下/configs/newcore,相当于你直接创建了一个core和一个collections
创建以后就可以直接在ui上看到创建的collections和依赖的core了。
更多命令参考:https://lucene.apache.org/solr/guide/7_5/solr-control-script-reference.html#solr-control-script-reference
第二种方式
是直接使用AdminUI页面创建一个core
1、直接在/opt/solr/server/solr下创建新文件夹,名字自定义,此处命名为newcore,作为新建的core;
2、找到/opt/solr/server/solr/configsets/_default目录下的conf文件夹,然后拷贝一份到/opt/solr/server/solr/newcore目录节点下。
3、然后按照下图操作:
创建核心需要先创建目录
solr@solr-c5bccd9f6-bwss5:/opt/solr/server/solr$ mkdir newcore
solr@solr-c5bccd9f6-bwss5:/opt/solr/server/solr$ cd newcore/
solr@solr-c5bccd9f6-bwss5:/opt/solr/server/solr/newcore$ mkdir conf
solr@solr-c5bccd9f6-bwss5:/opt/solr/server/solr/newcore$ cp -r ../server/solr/configsets/_default/conf/* ./conf/
solr@solr-c5bccd9f6-bwss5:/opt/solr/server/solr/newcore$ cp -r ../contrib/ ./
solr@solr-c5bccd9f6-bwss5:/opt/solr/server/solr/newcore$ cp -r ../dist/ ./
有了目录以后再做一下其他的修改就可以创建核心了。至于做什么修改,这就看你的业务需要了。等以后会修改了再回过头来修改,现在可以先不用修改。
然后就可以创建core了,这里使用的core的名字要和你前面创建的目录名称一样。

name:自定义的名字,建议和instanceDir保持一致
instanceDir: solrhome目录下的实例类目
dataDir:默认填data即可
config:指定配置文件,new_core/conf/solrconfig.xml
schema:指定schema.xml文件,new_core/conf/schema文件(实际上是managed-schema文件)
通过ui创建的方式我这种方式没有成功,报下面的错误
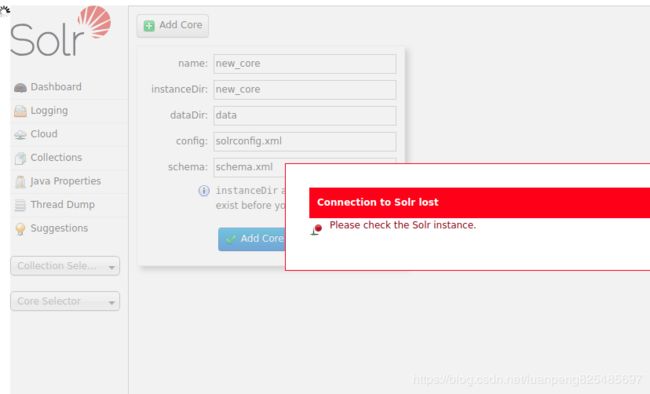
有时需要先手动在zookeeper中创建一个节点
/opt/zookeeper/bin/zkCli.sh create /solr/configs/newcore newcore
另外由于solr7版本进行升级修改了默认参数:可以在solr的pod中执行下面的命令进行修改。
/opt/solr/server/scripts/cloud-scripts/zkcli.sh -zkhost zookeeper-1:2181,zookeeper-2:2181,zookeeper-3:2181/solr -cmd clusterprop -name legacyCloud -val true
不然会出现下面的情况
问题:Error CREATEing SolrCore 'new_core': non legacy mode coreNodeName missing {schema=schema.xml, dataDir=data, config=solrconfig.xml}
下面可以创建collections了。

schema
schema简介:
schema是用来告诉solr如何建立索引的,他的配置围绕着一个schema配置文件,这个配置文件决定着solr如何建立索引,每个字段的数据类型,分词方式等,老版本的schema配置文件的名字叫做schema.xml他的配置方式就是手工编辑,但是现在新版本的schema配置文件的名字叫做managed-schema,他的配置方式不再是用手工编辑而是使用schemaAPI来配置,官方给出的解释是使用schemaAPI修改managed-schema内容后不需要重新加载core或者重启solr更适合在生产环境下维护,如果使用手工编辑的方式更改配置不进行重加载core有可能会造成配置丢失,
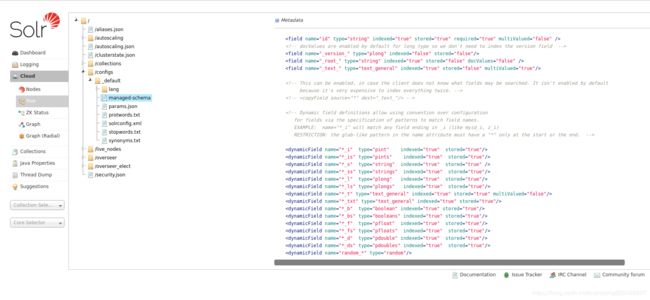
schema主要成员:
(1)fieldType:为field定义类型,最主要作用是定义分词器,分词器决定着如何从文档中检索关键字。
(2)analyzer:他是fieldType下的子元素,这就是传说中的分词器,他由一组tokenizer和filter组成,
(3)field:他是创建索引用的字段,如果想要这个字段生成索引需要配置他的indexed属性为true,stored属性为true表示存储该索引。如下图所示每个field都要引用一种fieldType由type属性定义
更多字段含义,可以参考:http://lucene.apache.org/solr/guide/7_5/documents-fields-and-schema-design.html
Schema API:
Schema API其实就是用post请求向solr服务器发送携带json参数的请求,所有操作内容都封装在json中,如果是linux系统直接使用curl工具或postman
更多api可以参考,很全面的:http://lucene.apache.org/solr/guide/7_5/schema-api.html
效果等同于手动修改managed-schema文件
分词器
配置IK分词
下载地址:https://pan.baidu.com/s/1Dbma2vAepBSsCag_EztTTw
解压后重构镜像
FROM solr:7.5
# 扩展数据源
COPY mysql-connector-java-8.0.15.jar /opt/solr/server/solr-webapp/webapp/WEB-INF/lib/
COPY protobuf-java-3.6.1.jar /opt/solr/server/solr-webapp/webapp/WEB-INF/lib/
# 扩展分词器
COPY ikanalyzer/* /opt/solr/server/solr-webapp/webapp/WEB-INF/lib/
RUN mkdir -p /opt/solr/server/solr-webapp/webapp/WEB-INF/classes
COPY ikanalyzer/* /opt/solr/server/solr-webapp/webapp/WEB-INF/classes/
在managed-schema文件中增加下面的内容,以便可以使用分词器
更改以后,我们在web上传一段文本,选择使用test_ik,可以看看效果
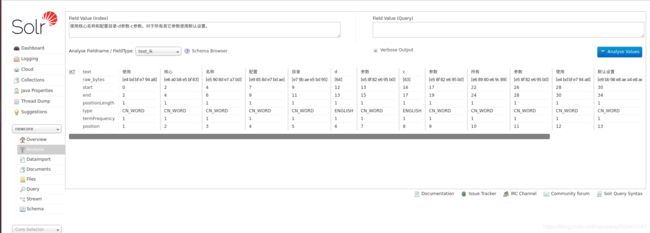
配置的更改
solrcloud分布式,使用zookeeper进行配置文件管理,可以使用bin / solr或SolrJ上载配置文件。
以下命令可用于使用bin / solr脚本上载新的配置集。
in/solr zk upconfig -n -d
管理SolrCloud配置文件
要更新或更改SolrCloud配置文件:
-
使用源代码管理结帐流程从ZooKeeper下载最新的配置文件。
-
进行更改。
-
将更改的文件提交给源代码管理。
-
将更改推送回ZooKeeper。
-
重新加载集合,以使更改生效。
也可以手动推送到zookeeper中,比如如果我修改了database-config.xml
/opt/solr$ bin/solr zk cp server/solr/newcore/conf/database-config.xml zk:/configs/newcore/database-config.xml -z zookeeper-1:2181,zookeeper-2:2181,zookeeper-3:2181/solr
命令包含
zkcli.sh -zkhost localhost:9983 -cmd bootstrap -solrhome /opt/solr
zkcli.sh -zkhost localhost:9983 -cmd upconfig -confdir /opt/solr/collection1/conf -confname myconf
zkcli.sh -zkhost localhost:9983 -cmd downconfig -confdir /opt/solr/collection1/conf -confname myconf
zkcli.sh -zkhost localhost:9983 -cmd linkconfig -collection collection1 -confname myconf
zkcli.sh -zkhost localhost:9983 -cmd makepath /apache/solr
zkcli.sh -zkhost localhost:9983 -cmd put /solr.conf 'conf data'
zkcli.sh -zkhost localhost:9983 -cmd putfile /solr.xml /User/myuser/solr/solr.xml
zkcli.sh -zkhost localhost:9983 -cmd get /solr.xml
zkcli.sh -zkhost localhost:9983 -cmd getfile /solr.xml solr.xml.file
zkcli.sh -zkhost localhost:9983 -cmd clear /solr
zkcli.sh -zkhost localhost:9983 -cmd list
zkcli.sh -zkhost localhost:9983 -cmd ls /solr/live_nodes
zkcli.sh -zkhost localhost:9983 -cmd clusterprop -name urlScheme -val https
zkcli.sh -zkhost localhost:9983 -cmd updateacls /solr
DIH导入索引数据
DIH简介:
DIH全称是Data Import Handler 数据导入处理器,顾名思义这是向solr中导入数据的,我们的solr目的就是为了能让我们的应用程序更快的查询出用户想要的数据,而数据存储在应用中的各种地方入xml、pdf、关系数据库中,那么solr首先就要能够获取这些数据并在这些数据中建立索引来达成快速搜索的目的,这里就列举我们最常用的从关系型数据库中向solr导入索引数据。
加入我们现在有一个数据库,包含了大量的用户和用户描述(例如存储用户简历相关的内容)

首先需要重新封装镜像
先下载mysql的驱动:https://jar-download.com/download-handling.php
封装镜像
FROM solr:7.5
# 扩展分词器
COPY mysql-connector-java-5.1.17.jar /opt/solr/server/solr-webapp/webapp/WEB-INF/lib/
RUN mkdir -p /opt/solr/server/solr-webapp/webapp/WEB-INF/classes
build镜像
docker build -t luanpeng/lp:solr-7.5 .
在我们自己建立的core的目录下有conf目录,这里面有着几个很重要的配置文件,之前我们用到的managed-schema(老版本是schema.xml)也在其中,另外还有一个solrconfig.xml文件,这是我们DIH配置的第一步,需要在此文件中配置数据导入文件的映射位置
修改solrconfig.xml文件
在 solrhome/${collection}/conf/solrconfig.xml 文件,添加对导入包的引用
在 solrhome/${collection}/conf/solrconfig.xml 文件,添加 dataimport requestHandler,配置requestHandler。
/opt/solr/newcore/conf/data-config.xml
dsj
oracle.jdbc.driver.OracleDriver
jdbc:oracle:thin:@ip:1521:orcl
user
password
说明:数据源可以配置在solrconfig.xml ,也可以配置在data-config.xml。
solr 是以文档为基本单位来存储和展示,data-config.xml定义着文档的元素。文档作为同类的代表,包含1个或多个根实体(root entity),实体又可包含多个子实体。实体是关系型数据库中的表或视图的映射,包含多个字段(filed)。字段的属性定义来源于solr schema。
在 solrhome/${collection}/conf/目录下,创建data-config.xml,并添加以下内容。
我们拷贝/opt/solr/example/example-DIH/solr/db/conf/db-data-config.xml文件成data-config文件,并修改成
entity配置说明
- name : 标识实体的唯一名称
- pk:实体的主键。非必选,用于增量导入(delta-import)。
- dataSource:配置在solrconfig.xml的dataSource名称,多数据源的时候会这么使用。示例中使用这种配置方式。
- query:必填,用全量导入(full-import)查询数据库的SQL。
- deltaQuery:用于增量导入,查询增量的主键传给deltaImportQuery使用${dih.delta.column-name}
- deltaImportQuery:增量导入查询用
- deletedPkQuery:增量删除用,根据主键来删除文档。
(1)首先配置数据源关系型数据库基本四项,驱动类,url,用户名,密码。
(2)配置document,可以把它当作与mysql中数据库一个层级的对象。
(3)配置entity,可以把它当作与数据库中一个表对应,在query中书写查询sql。
(4)配置field与表中的字段与之对应。
注意这里容易与schema中的配置混淆,我的理解是schema中配置的是创建索引的配置,而索引的创建需要有数据基础,而现在讲的数据导入文件就是建立索引的数据基础,他是创建索引的元数据。现在配置文件完成后可以用DIH命令执行了。
同时配置managed-schema 添加
DIH 命令
DIH命令就是用来执行数据导入的,命令种类繁多这里只列出简单常用。DIH命令采用的方式是URL的方式。
Dataimport(导入数据)
full-import:全部数据导入例如:
http://xx.xx.xx.xx:8983/solr/your_core_name/dataimport/?command=full-import
当然最好还是直接通过ui界面操作。

Command:full_import:全量导入;delta_import:增量导入。
选择 全量导入,Execute执行,Refresh Status刷新查看状态,其他都选默认即可。
Clean:在索引开始构建之前是否删除之前的索引,默认为true
Commit:在索引完成之后是否提交。默认为true
Execute:执行导入
Refresh Status:刷新后才能看到数据发生了变化(点一次刷新一次)
Documents (索引文档)
索引的增加,修改,删除相关操作。其中修改的逻辑是先删除后增加。
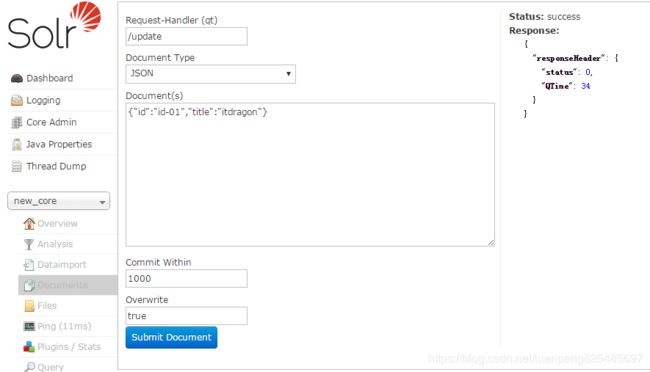
比较重要的是前三个参数
Request-Handler(qt):update(新增,更新和删除都用update)
Document Type:提交的索引文档类型,有JSON、XML等格式
Document(s):提交的索引文档内容
Commit Within:每1000毫秒执行
Overwrite:true,若文档存在则默认覆盖
删除索引:删除用json格式会出错,用xml格式后面需添加< commit/>
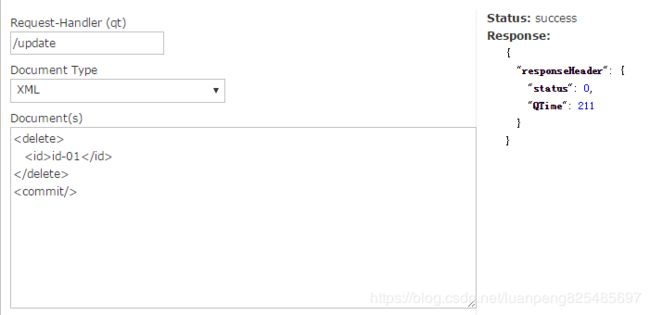
工作中,我们不可能为了个别数据去写代码修改数据,那么熟练使用Documents,对我们的工作有很大的帮助。
Query(查询页面)
查询所有价格在10到20之间的数据,并以价格降序输出商品类目名,商品标题,商品价格信息。
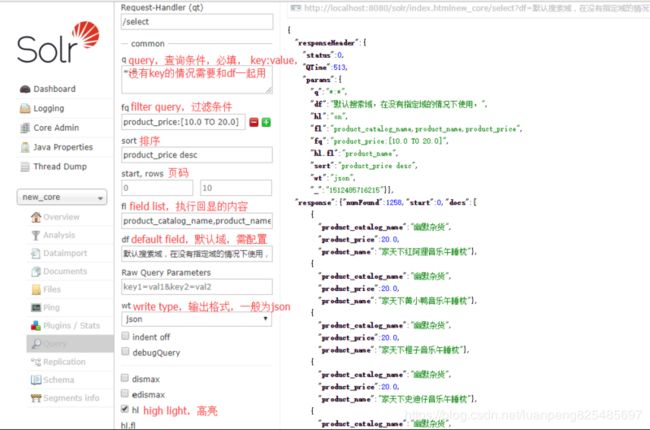
Request-Handler(qt):select查询操作
q(query):查询条件,key:value 形式,只能满足简单的查询
fq(filter query):过滤条件。对q的补充,实现复杂的查询。如:product_price:[10.0 TO 20.0] 表示价格在10~20之间。" " 表示无限,[ TO 20.0] 表示小于20.0
sort:对查询结果排序。如:product_price desc 表示价格降序
start,rows,开始页数,和每页多少条,简称页码
fl(field list):指定那些字段有返回值。多个值用","分隔。如:product_catalog_name,product_name,product_price
df(default field):默认域,当q查询没有key的时候,发挥作用
wt(write type):输出格式,一般都是json
hl(high light):高亮,搜索的结果若不高亮,那就没啥意义了。
solr与Elasticsearch的区别
参考:http://i.zhcy.tk/blog/elasticsearchyu-solr/