python爬虫入门--爬取百度百科10000条记录
一:前言
本文代码基于python2.7,安装Requests和BeautifulSoup以及bs4库
源代码托管在本人github:https://github.com/Wuchenwcf/MyCode/tree/master/python/%E5%9F%BA%E7%A1%80%E7%88%AC%E8%99%AB
二、系统设计
系统包括一下几个模块:
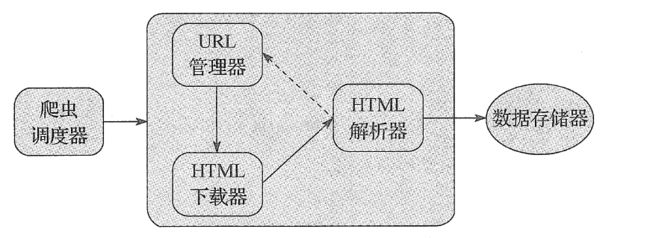
1.爬虫调度器主要负责统筹等其他四个模块的协调工作
2.URL管理器负责管理URL链接,维护已经爬取的URL集合和未爬取的URL集合,提供获取新URL连
3.HTML 下载器用于从URL管理器中获取未被爬取的URL连接并下载HTML网页4.HTML解析器用于从下载的HTML下载器中获取的已经下载的HTML网页,并从中解析出新的URL连接交给URL管理器,解析出有效数据交给数据存储器。
5.数据存储器用于将HTML解析器解析出来的数据通过文件或者数据库的形式存储起来。
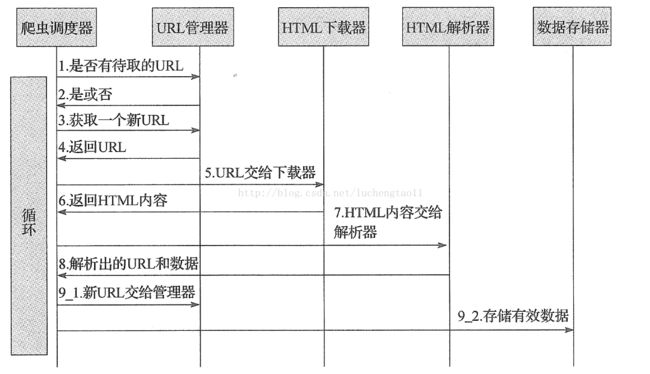
程序流程图如下:
三:代码
1.URL管理器,UrlManager.py
# coding:utf-8
class UrlManager(object):
def __init__(self):
self.new_urls=set() # 未爬取URL集合
self.old_urls=set() # 已爬取URL集合
def has_new_url(self):
"""
判断是否有未爬取的
:return:
"""
return self.new_urls_size()!=0
def get_new_url(self):
"""
获取一个未爬取的
:return:
"""
new_url=self.new_urls.pop()
self.old_urls.add(new_url)
return new_url
def add_new_url(self,url):
"""
将新的URL添加到未爬取的URL集合中
:param url:单个URL
:return:
"""
if url is None:
return
if url not in self.new_urls and url not in self.old_urls:
self.new_urls.add(url)
def add_new_urls(self,urls):
"""
将新的URL添加到未爬取的URL集合中
:param urls:URL集合
:return:
"""
if urls is None or len(urls)==0:
return
for url in urls:
self.add_new_url(url)
def new_urls_size(self):
"""
获取未爬取URL集合的大小
:return:
"""
return len(self.new_urls)
def old_url_size(self):
"""
获取已经爬取URL集合的大小
:return:
"""
return len(self.old_urls)2.HTML下载器,HtmlDownloader.py
# coding:utf-8
import requests
class HtmlDownloader(object):
def dowload(self,url):
if url is None:
return None
user_agent='Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.101 Safari/537.36'
headers={'User-Agent':user_agent}
r=requests.get(url,headers=headers)
if r.status_code==200:
r.encoding='utf-8'
return r.text
return
3.HTML 解析器,HtmlParser.py
# coding:utf-8
import re
import urlparse
from bs4 import BeautifulSoup
class HtmlParser(object):
def parser(self,page_url,html_cont):
"""
用于解析网页内容,抽取URL和数据
:param page_url: 下载页面的URL
:param html_cont: 下载的网页内容
:return: 返回URL和数据
"""
if page_url is None or html_cont is None:
return
soup = BeautifulSoup(html_cont,'html.parser')
new_urls = self._get_new_urls(page_url,soup)
new_data = self._get_new_data(page_url,soup)
return new_urls, new_data
def _get_new_urls(self,page_url,soup):
"""
抽取新的URL集合
:param page_url:
:param soup:
:return:
"""
new_urls=set()
# 抽取符合要求的a标记
links=soup.find_all('a',href = re.compile('/item/'))
for link in links:
# 提取href属性
new_url=link['href']
# 拼接成完整网址
new_full_url = urlparse.urljoin(page_url,new_url)
# print new_full_url
new_urls.add(new_full_url)
return new_urls
def _get_new_data(self,page_url,soup):
"""
抽取有效数据
:param page_url:下载页面的URL
:param soup:
:return: 返回有效数据
"""
data={}
data['url']=page_url
title=soup.find('dd',class_='lemmaWgt-lemmaTitle-title').find('h1')
data['title']=title.get_text()
summary=soup.find('div',class_='lemma-summary')
# 获取tag中包含的所有文本内容,包括子孙tag中的内容,并将结果作为Unicode字符串返回
data['summary']=summary.get_text()
return data
4.数据存储器 DataOutput.py
# coding:utf-8
import codecs
class DataOutput(object):
def __init__(self):
self.datas=[]
def store_data(self,data):
if data is None:
return
self.datas.append(data)
def output_html(self):
fout=codecs.open('baike.html','w',encoding='utf-8')
fout.write("")
fout.write("")
fout.write("")
for data in self.datas:
fout.write("")
fout.write("%s "%data['url'])
fout.write("%s "%data['title'])
fout.write("%s "%data['summary'])
fout.write(" ")
self.datas.remove(data)
fout.write("
")
fout.write("")
fout.write("")
fout.close()
5.爬虫调度器 SpiderMan.py
# coding:utf-8
from DataOutput import DataOutput
from HtmlParser import HtmlParser
from HtmlDownloader import HtmlDownloader
from UrlManager import UrlManager
import sys
reload(sys)
#可以让输出部乱码
sys.setdefaultencoding('utf8')
class SpiderMan(object):
def __init__(self):
self.manager = UrlManager()
self.downloader = HtmlDownloader()
self.parser = HtmlParser()
self.output = DataOutput()
def crawl(self,root_url):
# 添加入口URL
self.manager.add_new_url(root_url)
#判断url管理器中是否有新的url,同时判断抓取饿多少个url
while(self.manager.has_new_url() and self.manager.old_url_size()<10000):
try:
# 从URL管理器中获取新的url
new_url=self.manager.get_new_url()
# HTML下载器下载网页
html=self.downloader.dowload(new_url)
"""
with open(r"%s.html"%self.manager.old_url_size(), 'wb') as f:
f.write(html)
f.flush()
"""
# HTML解析器抽取网页数据
new_urls,data = self.parser.parser(new_url,html)
# 将抽取的url添加到url管理器中
self.manager.add_new_urls(new_urls)
# 数据存储器存储文件
self.output.store_data(data)
print "已经抓取%s个连接"%self.manager.old_url_size()
except Exception ,e:
print e
print "crawl failed"
#数据存储器将文件输出成指定格式
self.output.output_html()
if __name__=="__main__":
spider_man=SpiderMan()
spider_man.crawl("https://baike.baidu.com/item/Python")