hadoop3的简单安装方法(单节点)
前言
目前,网络上关于Hadoop安装的资料很多,过程比较详细,各种问题的解决方案基本都能找到,但资料质量参差不齐,随着hadoop版本的更新,有些方法已经不适用。lz初学hadoop,在这里面碰到不少坑,在此对hadoop安装方法进行梳理,既作为自己看的笔记,也希望能与大家交流。安装过程依照Apache官网的安装文档,对安装中遇到的问题,见招拆招。
安装环境
电脑系统:windows 10;虚拟机软件:VMware 11;远程登陆工具:securecrt
虚拟机操作系统:CentOS 7
JDK版本:1.8.0_171;hadoop版本:3.1.0
单节点集群安装
1.1 准备工作
①安装虚拟机
虚拟机的安装参考——在VMware Workstation中安装centos7.0教程。lz的安装设置如图1所示。
②使用远程登陆工具连接到虚拟机
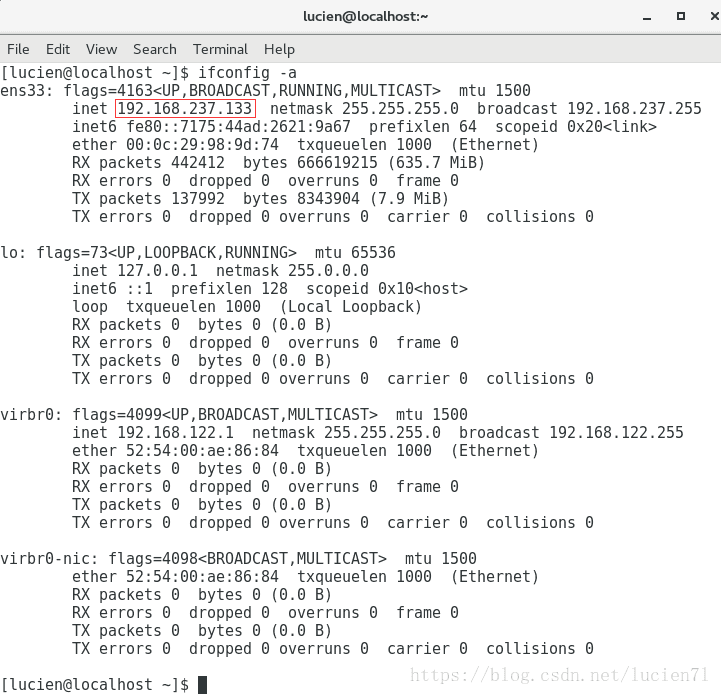
1、打开“Application”—>“Terminal”,输入ifconfig -a 查看虚拟机IP,如下图红框所示。
2、使用SecureCRT连接到CentOS,参考——如何用SecureCrt连接linux系统。之后的所有操作都在SecureCRT中进行。
③软件包准备
1、在系统根目录下新建文件夹resouce存放JDK、Hadoop等安装文件。
mkdir /resource
ls /
[root@localhost ~]# rz
rz waiting to receive.
开始 zmodem 传输。 按 Ctrl+C 取消。
100% 318264 KB 28933 KB/s 00:00:11 0 Errors
100% 186416 KB 31069 KB/s 00:00:06 0 Errors
[root@localhost ~]# mv hadoop-3.1.0.tar.gz /resource/
[root@localhost ~]# mv jdk-8u171-linux-x64.tar.gz /resource/
[root@localhost ~]# ls /resource/
hadoop-3.1.0.tar.gz jdk-8u171-linux-x64.tar.gz
[root@localhost ~]# 1.2 安装JDK
1、检查系统中JDK的版本
java -version
2、查找本地已安装的JDK软件包
[root@localhost lucien]# rpm -qa | grep java
tzdata-java-2018c-1.el7.noarch
python-javapackages-3.4.1-11.el7.noarch
java-1.7.0-openjdk-1.7.0.171-2.6.13.2.el7.x86_64
java-1.8.0-openjdk-1.8.0.161-2.b14.el7.x86_64
java-1.7.0-openjdk-headless-1.7.0.171-2.6.13.2.el7.x86_64
javapackages-tools-3.4.1-11.el7.noarch
java-1.8.0-openjdk-headless-1.8.0.161-2.b14.el7.x86_643、卸载OpenJDK,因为OpenJDK与官网JDK存在存在差异,更换为官网JDK可以避免不必要的麻烦。
[root@localhost lucien]# yum remove *openjdk*root@localhost lucien]# rpm -qa | grep java
tzdata-java-2018c-1.el7.noarch
python-javapackages-3.4.1-11.el7.noarch
javapackages-tools-3.4.1-11.el7.noarch4、解压jdk到“/usr/lib”文件夹下。
tar -zxvf /resource/jdk-8u171-linux-x64.tar.gz -C /usr/lib 查看结果如下图。
![]()
5、设置环境变量
编辑profile文件,vim使用方法参考vim命令。
[root@localhost ~]# vim /etc/profile在最前面添加如下信息。
export JAVA_HOME=/usr/lib/jdk1.8.0_171
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH[root@localhost ~]# source /etc/profile
[root@localhost ~]# java -version
java version "1.8.0_171"
Java(TM) SE Runtime Environment (build 1.8.0_171-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.171-b11, mixed mode)
[root@localhost ~]# javac -version
javac 1.8.0_1711.3 安装ssh和pdsh
ssh是hadoop安装的必需软件,pdsh是hadoop建议安装的软件。CentOS 7中已安装了openssh,可以通过下面的指令查看本机是否安装了ssh,及 ssh的运行状态。目前,我们还不需要配置ssh和pdsh,因此,只要满足hadoop的安装条件就可以了,不做过多介绍。[root@localhost ~]# rpm -qa | grep ssh
openssh-7.4p1-16.el7.x86_64
libssh2-1.4.3-10.el7_2.1.x86_64
openssh-clients-7.4p1-16.el7.x86_64
openssh-server-7.4p1-16.el7.x86_64[root@localhost ~]# ps -ef | grep ssh
root 1071 1 0 Jun22 ? 00:00:00 /usr/sbin/sshd -D
lucien 2039 1857 0 Jun22 ? 00:00:00 /usr/bin/ssh-agent /bin/sh -c exec -l /bin/bash -c "env GNOME_SHELL_SESSION_MODE=classic gnome-session --session gnome-classic"
root 59942 1071 0 05:34 ? 00:00:00 sshd: root@pts/1
root 61362 59956 0 05:54 pts/1 00:00:00 grep --color=auto ssh1.4单机版hadoop安装
1、解压hadoop压缩包到指定目录
[root@localhost ~]# tar -zxvf /resource/hadoop-3.1.0.tar.gz -C /usr/lib/2、编辑文件/usr/lib/hadoop-3.1.0/etc/hadoop/hadoop-env.sh。小技巧:先用echo查看JAVA_HOME,然后将其复制到文件中。
[root@localhost ~]# echo ${JAVA_HOME}
/usr/lib/jdk1.8.0_171
[root@localhost ~]# vim /usr/lib/hadoop-3.1.0/etc/hadoop/hadoop-env.sh
3、至此单机版Hadoop已经初步安装配置完成,官方提供了一个小测试,如下:
①新建一个input文件夹,并将etc/hadoop文件夹下的所有xml文件拷贝到该文件夹中,指令如下。
[root@localhost ~]# mkdir /resource/input
②利用mapReduce方法从input文件夹下的文件中查找符合条件的字符串,并将结果保存到output文件夹中。
[root@localhost ~]# /usr/lib/hadoop-3.1.0/bin/hadoop jar /usr/lib/hadoop-3.1.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.0.jar grep /resource/input /resource/output 'dfs[a-z.]+'
③查看结果。
[root@localhost ~]# cat /resource/output/*
1 dfsadmin1.5 伪分布式hadoop安装
在1.4的基础上进行如下配置:1、编辑etc/hadoop/core-site.xml;
[root@localhost ~]# vim /usr/lib/hadoop-3.1.0/etc/hadoop/core-site.xml
fs.defaultFS
hdfs://localhost:9000
2、编辑etc/hadoop/hdfs-site.xml;
[root@localhost ~]# vim /usr/lib/hadoop-3.1.0/etc/hadoop/hdfs-site.xml
dfs.replication
1
3、检查是否可以ssh到localhost,由于之前没有配置,显然是无法免密码连接的。
[root@localhost ~]# ssh localhost
The authenticity of host 'localhost (::1)' can't be established.不过hadoop提供了解决方案,执行红色指令后,既可以ssh到localhost了。
[root@localhost ~]# ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
Generating public/private rsa key pair.
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:JWkivbaAf74NxUVF3a5VqxjQUR08b9y25YgDli1TMpo [email protected]
The key's randomart image is:
+---[RSA 2048]----+
| o+=ooo.|
| . +o.. .+o|
| . o +o+* o*|
| . . =E+*.. .X|
| . . o S. +o..Bo|
| . o o .o.o..|
| . + . |
| o o |
| o.. |
+----[SHA256]-----+
[root@localhost ~]# cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
[root@localhost ~]# chmod 0600 ~/.ssh/authorized_keys
[root@localhost ~]# ssh localhost
Last login: Sat Jun 23 06:46:59 2018 from localhost
[root@localhost ~]# /usr/lib/hadoop-3.1.0/bin/hdfs namenode -format5、运行NameNode daemon和DataNode daemon。
[root@localhost ~]# /usr/lib/hadoop-3.1.0/sbin/start-dfs.sh[root@localhost ~]# /usr/lib/hadoop-3.1.0/sbin/start-dfs.sh
经过查找资料,找到该问题的解决方案。修改etc/hadoop/hadoop-env.sh文件,在末尾添加如下代码。
[root@localhost ~]# vim /usr/lib/hadoop-3.1.0/etc/hadoop/hadoop-env.sh export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root再运行,成功。
[root@localhost ~]# /usr/lib/hadoop-3.1.0/sbin/start-dfs.sh 利用jps指令查看启动状态,发现NameNode未启动。然后根据官方提示找到logs文件夹查看与相关日志,错误如下。
[root@localhost ~]# jps
68727 DataNode
69542 SecondaryNameNode
70860 Jps2018-06-23 07:23:25,445 ERROR org.apache.hadoop.hdfs.server.namenode.NameNode: Failed to start namenode.
org.apache.hadoop.hdfs.server.common.InconsistentFSStateException: Directory /tmp/hadoop-root/dfs/name is in an inconsistent state: storage directory does not exist or is not accessible.
at org.apache.hadoop.hdfs.server.namenode.FSImage.recoverStorageDirs(FSImage.java:376)
at org.apache.hadoop.hdfs.server.namenode.FSImage.recoverTransitionRead(FSImage.java:227)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.loadFSImage(FSNamesystem.java:1086)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.loadFromDisk(FSNamesystem.java:714)
at org.apache.hadoop.hdfs.server.namenode.NameNode.loadNamesystem(NameNode.java:669)
at org.apache.hadoop.hdfs.server.namenode.NameNode.initialize(NameNode.java:731)
at org.apache.hadoop.hdfs.server.namenode.NameNode.(NameNode.java:968)
at org.apache.hadoop.hdfs.server.namenode.NameNode.(NameNode.java:947)
at org.apache.hadoop.hdfs.server.namenode.NameNode.createNameNode(NameNode.java:1674)
at org.apache.hadoop.hdfs.server.namenode.NameNode.main(NameNode.java:1741)
2018-06-23 07:23:25,446 INFO org.apache.hadoop.util.ExitUtil: Exiting with status 1: org.apache.hadoop.hdfs.server.common.InconsistentFSStateException: Directory /tmp/hadoop-root/dfs/name is in an inconsistent state: storage directory does not exist or is not accessible.
2018-06-23 07:23:25,448 INFO org.apache.hadoop.hdfs.server.namenode.NameNode: SHUTDOWN_MSG: 提示文件不存在,经过多方查找,找到解决方案,重新格式化即可。
[root@localhost ~]# /usr/lib/hadoop-3.1.0/bin/hdfs namenode -format[root@localhost ~]# jps
72320 Jps
68727 DataNode
69542 SecondaryNameNode
71533 NameNode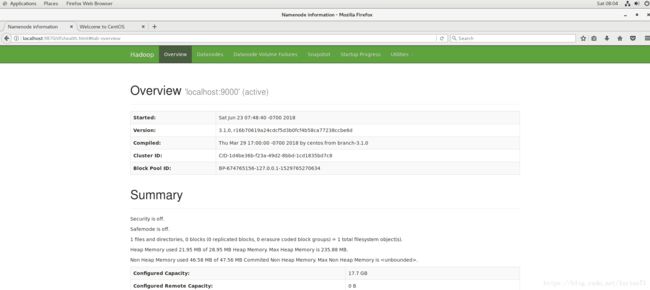
6、生成执行MapReduce任务的目录。同样的用前文单机hadoop测试的方法。
[root@localhost ~]# /usr/lib/hadoop-3.1.0/bin/hdfs dfs -mkdir /user
[root@localhost ~]# /usr/lib/hadoop-3.1.0/bin/hdfs dfs -mkdir /user/demo
7、将输入文件拷贝到分布式文件系统
[root@localhost ~]# /usr/lib/hadoop-3.1.0/bin/hdfs dfs -mkdir /user/demo/input
[root@localhost ~]# /usr/lib/hadoop-3.1.0/bin/hdfs dfs -put /resource/input/*.xml /user/demo/input8、执行示例程序
[root@localhost ~]# /usr/lib/hadoop-3.1.0/bin/hadoop jar /usr/lib/hadoop-3.1.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.0.jar grep /user/demo/input output 'dfs[a-z.]+'9、将输出文件从分布式文件系统拷贝到本地文件系统查看
[root@localhost ~]# /usr/lib/hadoop-3.1.0/bin/hdfs dfs -get output output
[root@localhost ~]# cat output/*
1 dfsadmin10、在分布式文件系统上查看输出文件
[root@localhost ~]# /usr/lib/hadoop-3.1.0/bin/hdfs dfs -cat output/*11、完成操作,停止守护进程
[root@localhost ~]# /usr/lib/hadoop-3.1.0/sbin/stop-dfs.sh
Stopping namenodes on [localhost]
Last login: Sat Jun 23 07:48:38 PDT 2018 on pts/3
Stopping datanodes
Last login: Sat Jun 23 08:23:39 PDT 2018 on pts/3
Stopping secondary namenodes [localhost.localdomain]
Last login: Sat Jun 23 08:23:46 PDT 2018 on pts/312、通过yarn在单节点中管理MapReduce任务。
①配置etc/hadoop/mapred-site.xml
mapreduce.framework.name
yarn
mapreduce.application.classpath
$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*
②配置etc/hadoop/yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.env-whitelist
JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME
③启动yarn。注意:此时报错!看错误是否似曾相识。
[root@localhost ~]# /usr/lib/hadoop-3.1.0/sbin/start-yarn.sh
同样的我们修改etc/hadoop/hadoop-env.sh文件,在末尾添加如下代码:
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root[root@localhost ~]# /usr/lib/hadoop-3.1.0/sbin/start-yarn.sh
Starting resourcemanagers on []
Last login: Sat Jun 23 08:23:52 PDT 2018 on pts/3
localhost: ERROR: Cannot set priority of resourcemanager process 114323
Starting nodemanagers
Last login: Sat Jun 23 18:53:18 PDT 2018 on pts/3
localhost: ERROR: Cannot set priority of nodemanager process 114469先找到日志文件看一下
[root@localhost ~]# cat /usr/lib/hadoop-3.1.0/logs/hadoop-root-resourcemanager-localhost.localdomain.log2018-06-23 18:53:19,619 INFO org.apache.hadoop.yarn.server.resourcemanager.ResourceManager: registered UNIX signal handlers for [TERM, HUP, INT]
2018-06-23 18:53:19,784 INFO org.apache.hadoop.conf.Configuration: found resource core-site.xml at file:/usr/lib/hadoop-3.1.0/etc/hadoop/core-site.xml
2018-06-23 18:53:19,849 ERROR org.apache.hadoop.conf.Configuration: error parsing conf mapred-site.xml
com.ctc.wstx.exc.WstxParsingException: Illegal to have multiple roots (start tag in epilog?).
at [row,col,system-id]: [26,2,"file:/usr/lib/hadoop-3.1.0/etc/hadoop/mapred-site.xml"]
##略##
##略##
Caused by: com.ctc.wstx.exc.WstxParsingException: Illegal to have multiple roots (start tag in epilog?).
at [row,col,system-id]: [26,2,"file:/usr/lib/hadoop-3.1.0/etc/hadoop/mapred-site.xml"]
##略##
2018-06-23 18:53:19,860 INFO org.apache.hadoop.yarn.server.resourcemanager.ResourceManager: Transitioning to standby state
2018-06-23 18:53:19,860 INFO org.apache.hadoop.yarn.server.resourcemanager.ResourceManager: Transitioned to standby state
2018-06-23 18:53:19,861 INFO org.apache.hadoop.yarn.server.resourcemanager.ResourceManager: SHUTDOWN_MSG:
从日志中可以看到错误是发生在/usr/lib/hadoop-3.1.0/etc/hadoop/mapred-site.xml文件,找到该文件,发现有两个configuration,但一般都只有一个,因此对其进行合并,如下。
mapreduce.framework.name
yarn
mapreduce.application.classpath
$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*
重新启动,成功。可以通过http://localhost:8088/网站查看。
[root@localhost ~]# /usr/lib/hadoop-3.1.0/sbin/start-yarn.sh
Starting resourcemanager
Last login: Sat Jun 23 19:10:02 PDT 2018 on pts/3
Starting nodemanagers
Last login: Sat Jun 23 19:16:58 PDT 2018 on pts/3
[root@localhost ~]# jps
116866 NodeManager
117305 Jps
116655 ResourceManager

总结
至此,基于单节点的hadoop运行环境搭建完成,整个过程完全参照官方文档进行,只有在报错和遇到问题时再去网上搜索相关解决方案。这其中有两个重要的地方:1、必须熟悉linux命令,lz接触linux的时间不长,很多命令都需要去网上查询,但熟能生巧,用的多了就记住了;2、要学会看官方文档和系统日志,安装过程中的许多问题都是在日志中找到症结,并解决的。
但是,在搭建过程中我们并未对hadoop的架构、运行机制、配置细项进行探究,在之后的学习中,我们再来做深入的探讨。