Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks(CycleGAN)
Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
目录
摘要
1.引言
2.相关工作
3.Formulation
3.1. Adversarial Loss
3.2. Cycle Consistency Loss
3.3. Full Objective
4.implementation
4.1 Network Architecture
4.2 Training details
5.Results
摘要
图像到图像的转换是一个经典的视觉和图形问题,目的是在对齐的数据集中学习输入图像和输出图像之间的映射关系。然而,许多任务,对齐训练数据很难获取。作者提出一种不对齐数据集训(源数据域X到目标域Y)的学习方法。目标是学习映射G: X -> Y 认为来自G(x)的分布图与使用对抗性损失的分布图无法区分。因为这个映射是高度受限,所以作者使用一个逆映射:Y -> X, 并引入一个循环一致性损失强制 F(G(X))~X(反之亦然)。在不存在配对训练数据的情况下,给出了定性的结果,包括收集风格迁移,物体变形,季节转移,光增强等。通过对几种已有方法的定量比较,证明了作者的方法的优越性。
1. 引言
1873年的一个美好的春日,克劳德.莫奈把画架放在阿让泰尔附近的塞纳河岸边,他看到了什么(图1,左上)?一张彩色图片,如果被发明,可能记录了一个清澈的蓝天和一条反射着它的玻璃河。莫奈通过笔触和明亮的调色表达了他对这一场景的印象。
如果莫奈在一个凉爽的夏夜在卡西斯的小港(图1,左下)呢?在一组莫奈的绘画作品中走一走,就可以想象出他将如何描绘这个场景;也许是用柔和的色调,突然涂上一点颜料,以及稍微平坦动态的范围
我们可以想象,所以的这一切,尽管从来没有看到莫奈画该场景的画。相反,我们知道一套莫奈的绘画和一套风景照片,我们可以推断出两个数据集之间的差异,由此可以想象出,将一个数据集“转换”到另一个数据集,会是怎样?
在本文中,我们提出了可以学习的方法;捕捉一个图像集的特殊特征,并找出如果将这些特征转化为另一个图像集,所有这些都是在没有任何配对训练数据集的情况下进行的。
图像迁移问题[21]将图像从给定场景的一种表达形式,x,转换为另一种表示形式,y,例如灰色to彩色, 图像to语义标签,边缘图to图片。多年来研究计算机视觉,图像处理,计算摄影,图形制作等功能强大的“转换”系统,都是在监督下设计的,训练数据集是成对的才可用。然而,获取成对的训练数据可能即困难又昂贵。例如,对于诸如语义分割这样的任务,仅存在两个数据集(例如[4]),它们相对较小。获得输入输出对图形任务的艺术风格化更加困难,它们期望的输出高度复杂,通常需要技术创作。许多任务,像物体变形(e.g 斑马<->马 图1中部),想要的输出甚至没有明确的定义。
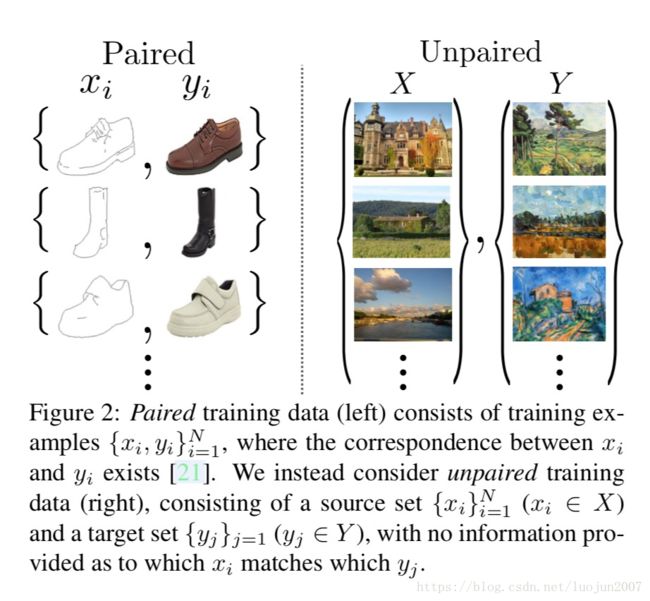
因此,我们寻求一种算法,它可以在没有成对的输入输出例子(图2,右)的情况下在域之间进行转换。我们假设域之间存在某种潜在的关系,即它们是两个不同的渲染方式,但是相同的底层场景,并寻求学习这种关系。虽然缺少在成对例子的监督,但是可以在数据集的层次上采用监督;我们给出一个图像域X 和 有差别的另外一个域 Y. 我们可以训练映射G: X -> Y 这样的输出 y = G(x), 从理论上讲,这个目标可以在y上产生一个域经验分布Pdata(y) 相匹配的输出分布(通常,这要求G是随机的)。最优的G因此将域X转换成一个分布于Y上的域Y,且分布相同。但是,这样的转换并不能保证每个输入x和输出y具有成对的意义。有无穷多个映射G,它们将在y上导出相同的分布。另外,在实际应用中,我们发现很难孤立的优化对抗性目标:标准的程序往往会导致model崩溃(所有的输入图像映射到相同的输出图像,而优化没有取得进展)
这些问题需要增加更多的结构到我们的目标中。因此,我们利用转换应该是“循环一致性”的特征,也就是说,如果我们把一个句子从英语翻译成法语,然后再从法语翻译成英语,那么我们就应该回到原句子[3]. 从数学上讲,如果我们有一个翻译家G: X -> Y 和另一个翻译家F: Y -> X,那么G和F应该是互逆的,并且两个映射都应该是双射的。通过同时训练G和F,并添加一个循环一致性损失,我们鼓励 F(G(x)) ~ x 和 G(F(y)) ~ y. 将此损失与域X和域Y上的对抗损失结合起来,就得到了未配对图像转换的全部目标。
2. 相关工作

Cycle Consistency
循环一致性使用传递性作为结构化数据规范化方法的思路由来已久。在视觉跟踪中,加强简单的前向-后向一致性是几十年的标准技巧。语言领域,通过“反向翻译和再认”来验证译文的改进是人类译者所使用的技术。最近,更高阶的循环一致性用在结构运动中,3D形状匹配,联合分割,稠密语义配准,深度估计。和我们工作最相似的是,他们使用循环一致性损失传递训练CNN监督网络。这篇论文中,我们引入相似的损失,以推动G和F之间的一致性。与我们工作同时进行,在这些相同的过程中,yi等人。独立使用相似的目标进行不成对的图像到图像的转换,灵感来自谷歌翻译的双重学习。
3. Formulation
我们的目标是学习两个域X和域Y之间的映射函数,给定的训练样本 X 和 Y。我们将数据分布表示为:X~Pdata(x) 和 Y~Pdata(y)。如图3(a) 表示,我们的模型包括两个映射G: X -> Y 和 F:Y -> X. 此外,我们还介绍了两个对抗性鉴别器Dx 和 Dy, Dx的目的是区别图像x和翻译后的图像F(y);同样,Dy的目的是区分y和G(x)。我们的目的包括两种类型:对抗性损失[15]为了将生成的图像与目标域中的数据分布进行匹配;以及循环一致性损失,以防止学习的映射G和F相互矛盾。
3.1. Adversarial Loss
我们采用对抗损失[15]映射到两个映射函数。对于映射函数G:X -> Y及其Dy, 我们表示目标为:

G试图生成与域Y中的图像相似的图像G(x),而Dy的目的是区分转换后的样本G(x)和实际样本Y。G的目标是最小化这个目标,相反对抗性D的目标是最小化。即 。我们为映射函数F引入了一个类似的对抗损失:Y -> X 及其鉴别器Dx , 即
。我们为映射函数F引入了一个类似的对抗损失:Y -> X 及其鉴别器Dx , 即 。
。
3.2. Cycle Consistency Loss
理论上讲,对抗训练可以学习生成输出的映射G和F, 它们分别作为目标域Y和X分布(严格来说,这个映射函数G和F是随机函数),不过,网络的容量足够大,可以同时讲一组图像映射到目标域中任意随机排列的图像,这些图像中,任何学习到的映射都可以生成与目标分布相匹配的输出分布。这样,对抗损失本身不能保证学习功能能讲个题的输入映射到一个期望的输出Yi。为了进一步减少可能的映射函数的区间,我们认为学习的映射函数应该具有循环一致性:
如图3(b)所示,对于每个来自域X的图像x,图像循环转换应该能够使x返回到原始图像,即 x -> G(x) -> F(G(x)) 约等于 x。我们称此为前向循环一致性。同理3(c)所示,对于域Y的每个图像y,G和F也应该满足后向循环一致性:y -> F(y) -> G(F(y)) 约等于 y。我们可以通过循环一致性损失来激励这种过程:

在初步实验中,我们还尝试用F(G(x))和x之间的对抗性损失,以及G(F(y))和y之间的对抗性损失来替代L1范数,但是没有观察到性能的改善。
3.3. Full Objective
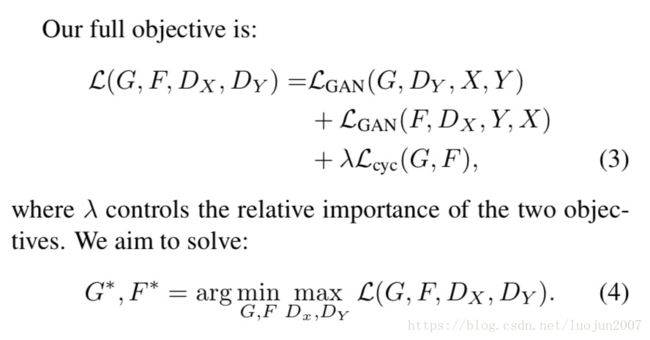
注意,我们的模型可以看作是训练两个“自编码器”[9]:我们学习一个自动编码FoG: X -> X与另外一个自编码GoF:Y -> Y。然而,这些自动编码都有特殊的内部结构:它们通过将图像转换为另一域的中间表示,将图像映射到自身。这样的设置也可以看作是“对抗性自动编码”的特例。[32]它使用一个对抗性损失来训练一个自动编码器的瓶颈层,以匹配人意的目标分布。在我们的例子中,X -> X 自动编码的目标分布是域Y(中间表示)。
在第5.1.4节中,我们将我们的方法域完全目标的融合方法进行比较,包括对抗性损失Lgan和循环性一致性损失Lcyc进行单独比较,并从经验上证明这两个目标在获取高质量结构方面发挥了关键作用。我们还给出了仅在一个方向上使用cycle loss,实验证明,单循环不适合受限问题的正规化训练。
4. Implementation
Network Architecture
我们采用了适合我们使用的网络架构-Johnson等人的生成网络。他们在神经风格迁移和超分辨率方面已经展现了令人印象深刻的结果。该网络包括两个stride-2卷积,几个残差块和两个分步长卷积。对128*128图像使用6个块,对256*256和更高分辨率的训练图像使用9个块,与Johnson等人相似。我们使用例子归一化。对于判别网络,我们使用70个PatchGANs,其目的是对70*70的重叠图像块进行是真是假分类。这样的判别器架构比全图判别器具有更少的参数,并且可以以全卷积的方式应用于任意大小的图像。
Training details
我们应用了两个最近工作中的技巧来稳定我们的模型训练程序。
第一,对于Lgan(方程1),我们用最小二乘损失替代负对数似然目标。这种损失在训练和生成高质量结果时更稳定。
第二,减少模型的震荡[1]我们遵循Shrivastava等人的策略[45]使用历史生成的图片更新鉴别器,而不是网络最新生成的图片。我们保留了一个图像缓冲区,用来存储50幅以前生成的图像。
对于所有的实验,我们在方程3中设置了lamda = 10。我们使用Adam求解器[24],batch size = 1。所有网络都从零开始训练,学习率为0.0002。我们在前100个epoch保持相同的学习率,并在接下来的100个epoch中线性衰减为0。请参阅附录(第7节)了解关于数据集,架构和训练程序的更多细节。
5. Results
我们首先将我们的方法与最近的方法进行比较,即对配对的数据集进行image-to-image转换,其中groud truth input-output配对数据用于评估。然而,我们研究了对抗损失和循环一致性损失的重要性,并将完整的方法与几个变量进行了比较。最后我们在不存在成对数据集的许多应用程序上演示了该算法的通用性。为了简介起见,我们将方法称之为CycleGAN。可以在github上查看代码和完整的结果。
github源码地址:https://github.com/junyanz/CycleGAN
使用与“pix2pix"相同的评估数据集和度量标准[21]我们将我们的方法与几个baseline进行定性和定量的比较。任务包括Cityscapes数据集中的语义标签图片[4]和从Google地图上刮下来的地图数据。我们还对全损耗函数进行了消融研究

