FaceNet的center-loss和SoftMax简介(比较简略)
项目地址:https://github.com/davidsandberg/facenet
- facenet基于MTCNN的人脸检测和Inception-Resnet-v1的人脸识别网络
- softmax,center loss 训练结果比triplet loss训练结果好太多,自己训练达到99.0%+-0.006。利用msceleb训练集。
一、MTCNN人脸检测
待补充
二、Inception-resnet-v1人脸识别模块
2.1如何自己重新训练facenet模型
2.1.1triplet loss原理
triplet loss代码如下:
def triplet_loss(anchor, positive, negative, alpha):
"""Calculate the triplet loss according to the FaceNet paper
Args:
anchor: the embeddings for the anchor images.
positive: the embeddings for the positive images.
negative: the embeddings for the negative images.
Returns:
the triplet loss according to the FaceNet paper as a float tensor.
"""
with tf.variable_scope('triplet_loss'):
pos_dist = tf.reduce_sum(tf.square(tf.subtract(anchor, positive)), 1)
neg_dist = tf.reduce_sum(tf.square(tf.subtract(anchor, negative)), 1)
basic_loss = tf.add(tf.subtract(pos_dist,neg_dist), alpha)
loss = tf.reduce_mean(tf.maximum(basic_loss, 0.0), 0)
return loss- 可以看出,triplet loss 利用一组三元数据,分别设为(A,P,N)。其中A代表基准图片,P是与A同一个人的人脸,N是与A不同人的人脸。输入的是从网络输出的embeddings,即最后的特征值。
- facenet中embeddings的shape由batchsize和embeddings的shape决定,在此例中,我将batchsize设置为30,embeddings_shape为128.则每次输入的anchor为(10,128)的数据。P,N也一样。
- 计算loss时,由于A和P的距离小于A和N的距离,所以当alpha=0.2时,
basic_loss=dist(a,p)+0.2−dist(a,n)basic_loss=dist(a,p)+0.2−dist(a,n)
此表达式的目的是为了loss减小的同时,可以修改符合dist(a,p)+0.2 > dist(a,n)这组数据,因为此时,pos_dist+0.2 > neg_dist(a,n),要让pos距离尽可能小,neg距离尽可能大。而在降低loss的同时,就是在做这件事。
解释了triplet loss,开始训练。
2.1.2 利用triplet loss 训练
如何利用triplet loss训练
- 首先人脸检测,裁剪图片,下载Msceleb或者casia图片库,利用MTCNN进行face align,可以crop到160或者182,只需要分别修改margin和imagesize,margin=32对应160,margin=44对应182.如果裁剪到182,训练时要加–random_crop参数,最后输入网络的依然是160.如果像MsCeleb这种数据集,大约1000,0000的数据量,即使清洗数据依然有500,0000的人脸数据量。需要利用多GPU裁剪,参考上述链接。5百万数据,TITAN XP做了14个小时。
- 接下来训练识别模型,triplet loss的队列输入每次输入三个图片算一组。batchsize也必须调整为3的倍数,970,4G我用的30。整个数据训练流程如下:
- 这里要提到images_per_person和images_per_person。首先计算一个epoch要提取的数值,假设images_per_person=45,images_per_person=40,那么nrof_examples=45*40=1800,在这1800容器中,按挑选45个人提取图片,输入进网络计算出embeddings,具体提取过程参考select_triplets()和sample_people(),batchsize=30时,约20000组三元数据。
- 队列读入数据 ,进行enqueue的op,计算loss,合并正则的loss,此处tf.GraphKeys.REGULARIZATION_LOSSES是在inception-resnet-v1的model中,inference()中slim.arg_scope中定义自动添加到这里,就是所有的权值正则化项,而weight_decay手动定义,这里取1e-4,打印正则化项shape,长度133.
- 计算loss后不断迭代。
本人triplet loss训练结果一直不如人意,最终lfw的acc只能停留在86%左右。而换成center loss,一下就99.0%了。玄学triplet loss。
2.1.1 center loss原理
利用softmax训练
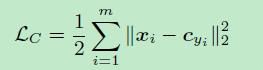
此公式中 cyicyi 代表第i类的中心,只训练符合此类的 xixi,使得类内距离尽可能的小。达到了提高精度的效果。在人脸识别更适用,因为同一个人的人脸相差不大,特征的类内距离更为接近。人脸的中心性更强一些,也就是说一个人的所有脸取平均值之后的人脸我们还是可以辨识是不是这个人。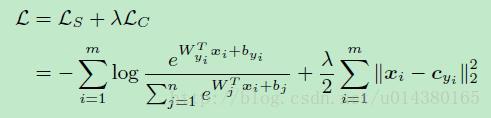
总的loss是由softmax loss和center loss相加,由λλ控制比例。
关于center loss 原理:center loss 原理
train_softmax.py训练
def center_loss(features, label, alfa, nrof_classes):
"""Center loss based on the paper "A Discriminative Feature Learning Approach for Deep Face Recognition"
(http://ydwen.github.io/papers/WenECCV16.pdf)
"""
nrof_features = features.get_shape()[1]
centers = tf.get_variable('centers', [nrof_classes, nrof_features], dtype=tf.float32,
initializer=tf.constant_initializer(0), trainable=False)
label = tf.reshape(label, [-1])
centers_batch = tf.gather(centers, label)
diff = (1 - alfa) * (centers_batch - features)
centers = tf.scatter_sub(centers, label, diff)
loss = tf.reduce_mean(tf.square(features - centers_batch))
return loss, centers- 2.1.2 利用center loss和softmax训练
其中添加loss的模块如下:
# Add center loss
if args.center_loss_factor>0.0:
prelogits_center_loss, _ = facenet.center_loss(prelogits, label_batch, args.center_loss_alfa, nrof_classes)
tf.add_to_collection(tf.GraphKeys.REGULARIZATION_LOSSES, prelogits_center_loss * args.center_loss_factor)
learning_rate = tf.train.exponential_decay(learning_rate_placeholder, global_step,
args.learning_rate_decay_epochs*args.epoch_size, args.learning_rate_decay_factor, staircase=True)
tf.summary.scalar('learning_rate', learning_rate)
# Calculate the average cross entropy loss across the batch
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(
labels=label_batch, logits=logits, name='cross_entropy_per_example')
cross_entropy_mean = tf.reduce_mean(cross_entropy, name='cross_entropy')
tf.add_to_collection('losses', cross_entropy_mean)
# Calculate the total losses
regularization_losses = tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES)
total_loss = tf.add_n([cross_entropy_mean] + regularization_losses, name='total_loss')
- 整体流程与triplet loss类似,此方法是基础方法,所有显示的epochsize=1000是对此方法生效的。在triplet loss方法时1000只是一个最低限额,而真正的epochsize次数不是1000.与triplet loss不同的是,每次一张图片的输入而不是三元组的输入。
- 学习率,开场0.1,150=0.01,180=0.001,210=0.0001到了150时loss和acc有明显的变化,acc从98%上升到99%,其余变化点无明显变化。
- 收敛迅速,200个epoch达到99%,TITAN XP batchsize=150.
补充:
其余滑动平均、随机crop,prewhiten等代码中都很详细。
三、评价模型准确率
- 如何验证lfw数据集
- 评价模型准确率时,利用lfw的pairs做varification。accuracy很好理解,具体参考facenet.calculate_roc(),利用10折交叉验证,找出最佳accuracy的阈值,从0-4步长0.01.一般在1.2左右。
- 而Validation rate,和far这个判断值搞了半天才搞清楚,这个值是在假定误把不同的人判断为相同的人的概率设定为FAIR=0.001的情况下,判断两个人是同一个人判断正确的概率。这个是为了尽可能降低将不同人判断为同一个人的概率。
def calculate_val_far(threshold, dist, actual_issame):
predict_issame = np.less(dist, threshold)
true_accept = np.sum(np.logical_and(predict_issame, actual_issame))
false_accept = np.sum(np.logical_and(predict_issame, np.logical_not(actual_issame)))
n_same = np.sum(actual_issame)
n_diff = np.sum(np.logical_not(actual_issame))
val = float(true_accept) / float(n_same)
far = float(false_accept) / float(n_diff)
return val, far
版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/Eclipsesy/article/details/78909799