SparkStreaming之读取Kafka数据
本文主要记录使用SparkStreaming从Kafka里读取数据,并计算WordCount
主要内容:
- 1.本地模式运行SparkStreaming
- 2.yarn-client模式运行
相关文章:
1.Spark之PI本地
2.Spark之WordCount集群
3.SparkStreaming之读取Kafka数据
4.SparkStreaming之使用redis保存Kafka的Offset
5.SparkStreaming之优雅停止
6.SparkStreaming之写数据到Kafka
7.Spark计算《西虹市首富》短评词云
1.本地模式运行
object ScalaKafkaStreaming {
def main(args: Array[String]): Unit = {
// offset保存路径
val checkpointPath = "D:\\hadoop\\checkpoint\\kafka-direct"
val conf = new SparkConf()
.setAppName("ScalaKafkaStream")
.setMaster("local[2]")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN")
val ssc = new StreamingContext(sc, Seconds(5))
ssc.checkpoint(checkpointPath)
val bootstrapServers = "hadoop1:9092,hadoop2:9092,hadoop3:9092"
val groupId = "kafka-test-group"
val topicName = "Test"
val maxPoll = 500
val kafkaParams = Map(
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> bootstrapServers,
ConsumerConfig.GROUP_ID_CONFIG -> groupId,
ConsumerConfig.MAX_POLL_RECORDS_CONFIG -> maxPoll.toString,
ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer],
ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer]
)
val kafkaTopicDS = KafkaUtils.createDirectStream(ssc, LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](Set(topicName), kafkaParams))
kafkaTopicDS.map(_.value)
.flatMap(_.split(" "))
.map(x => (x, 1L))
.reduceByKey(_ + _)
.transform(data => {
val sortData = data.sortBy(_._2, false)
sortData
})
.print()
ssc.start()
ssc.awaitTermination()
}
}本地模式运行SparkStreaming每隔5s从Kafka读取500条数据并计算WorkCount,然后按次数降序排列,并将Offset保存在本地文件夹
创建Topic
kafka-topics.sh --create --zookeeper hadoop1:2181,hadoop2:2181,hadoop3:2181/kafka --topic Test --partitions 3 --replication-factor 3
查看创建的Topic
kafka-topics.sh --describe --zookeeper hadoop1:2181,hadoop2:2181,hadoop3:2181/kafka

编写Kafka程序并往Topic里写数据
public class ProducerTest {
private static final String[] WORDS = {
"hello", "hadoop", "java", "kafka", "spark"
};
public static void main(String[] args) throws Exception {
Properties props = new Properties();
props.put("bootstrap.servers", "hadoop1:9092,hadoop2:9092,hadoop3:9092");
props.put("acks", "all");
props.put("retries", 0);
props.put("batch.size", 16384);
props.put("linger.ms", 1);
props.put("buffer.memory", 33554432);
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer kafkaProducer = new KafkaProducer(props);
boolean flag = true;
while (flag) {
for (int i = 0; i < 500; i++) {
//3、发送数据
kafkaProducer.send(new ProducerRecord("Test", WORDS[new Random().nextInt(5)]));
}
kafkaProducer.flush();
System.out.println("==========Kafka Flush==========");
Thread.sleep(5000);
}
kafkaProducer.close();
}
}
每5s写500条数据到Topic
运行结果如下:
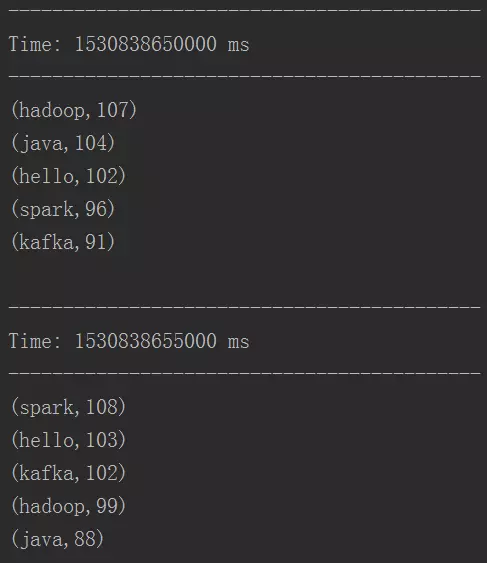
可以看到我们的程序可以正确运行了。
2.yarn-client模式运行
修改程序的checkpoint为hdfs上的目录
object ScalaKafkaStreaming {
def main(args: Array[String]): Unit = {
// offset保存路径
val checkpointPath = "/data/output/checkpoint/kafka-direct"
val conf = new SparkConf()
.setAppName("ScalaKafkaStream")
//.setMaster("local[2]")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN")
val ssc = new StreamingContext(sc, Seconds(3))
ssc.checkpoint(checkpointPath)
val bootstrapServers = "hadoop1:9092,hadoop2:9092,hadoop3:9092"
val groupId = "kafka-test-group"
val topicName = "Test"
val maxPoll = 20000
val kafkaParams = Map(
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> bootstrapServers,
ConsumerConfig.GROUP_ID_CONFIG -> groupId,
ConsumerConfig.MAX_POLL_RECORDS_CONFIG -> maxPoll.toString,
ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer],
ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer]
)
val kafkaTopicDS = KafkaUtils.createDirectStream(ssc, LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](Set(topicName), kafkaParams))
kafkaTopicDS.map(_.value)
.flatMap(_.split(" "))
.map(x => (x, 1L))
.reduceByKey(_ + _)
.transform(data => {
val sortData = data.sortBy(_._2, false)
sortData
})
.print()
ssc.start()
ssc.awaitTermination()
}
}
pom.xml文件
org.apache.spark
spark-core_2.11
2.3.0
provided
org.apache.spark
spark-streaming_2.11
2.3.0
provided
org.apache.spark
spark-streaming-kafka-0-10_2.11
2.3.0
compile
maven-assembly-plugin
false
jar-with-dependencies
make-assembly
package
assembly
org.scala-tools
maven-scala-plugin
2.15.2
scala-compile-first
compile
**/*.scala
scala-test-compile
testCompile
这里将spark-streaming-kafka-0-10_2.11打包进jar,不然运行时会报找不到一些类,也可以通过其他方式解决
上传jar,执行
./bin/spark-submit \
--class me.jinkun.scala.kafka.ScalaKafkaStreaming \
--master yarn \
--deploy-mode client \
--driver-memory 512m \
--executor-memory 512m \
--executor-cores 1 \
/opt/soft-install/data/spark-yarn-1.0-SNAPSHOT.jar
运行过程可能会报如下错误:
Current usage: 114.5 MB of 1 GB physical memory used; 2.2 GB of 2.1 GB virtual memory used. Killing container.
解决方式:参考https://blog.csdn.net/kaaosidao/article/details/77950125
我这里修改yarn-site.xml,加入如下配置
yarn.nodemanager.vmem-pmem-ratio
3
运行如下:

说明程序已经正常启动,进入Yarn的管理界面可以看到正在执行任务http://hadoop1:8088

Yarn管理界面正在运行的作用
通过ID可以查看运行的日志

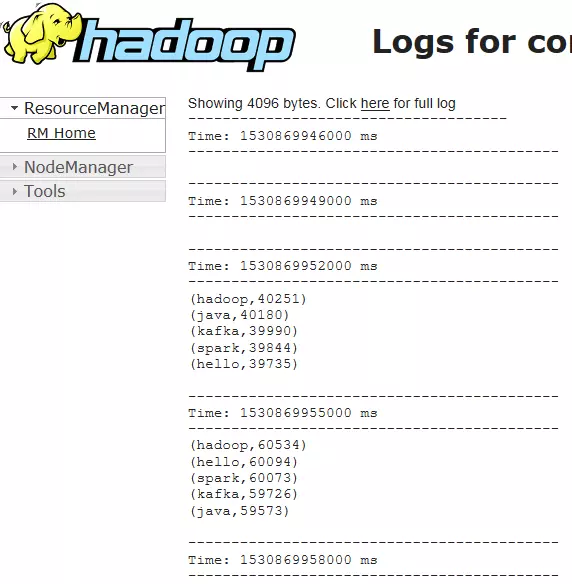
运行的结果
通过Tracking UI 可以看到Spark的管理界面
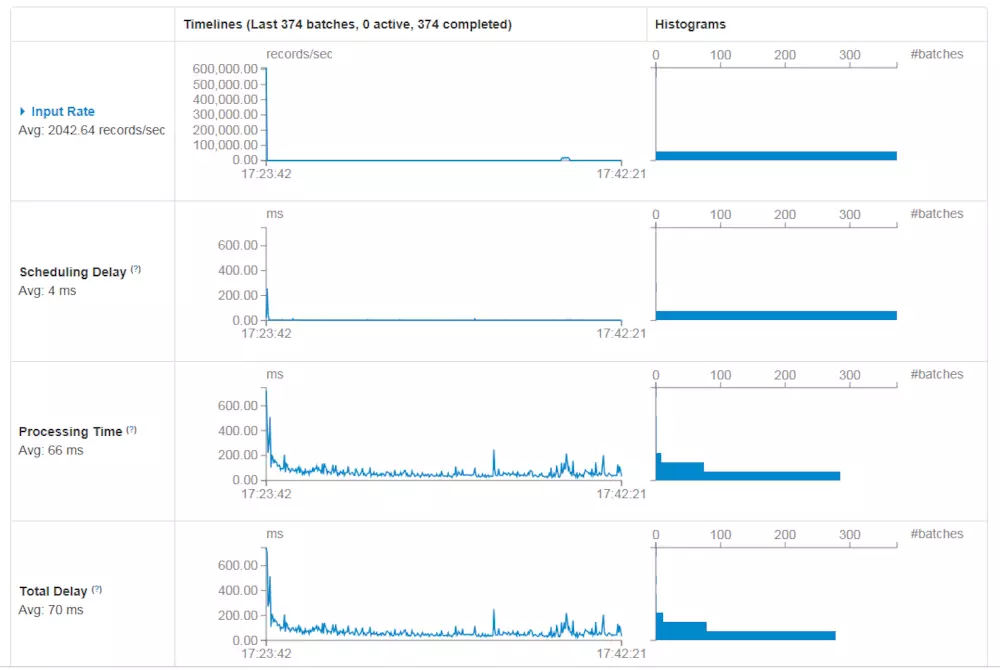
运行如下命令停止SparkStreaming程序
yarn application -kill [appid]
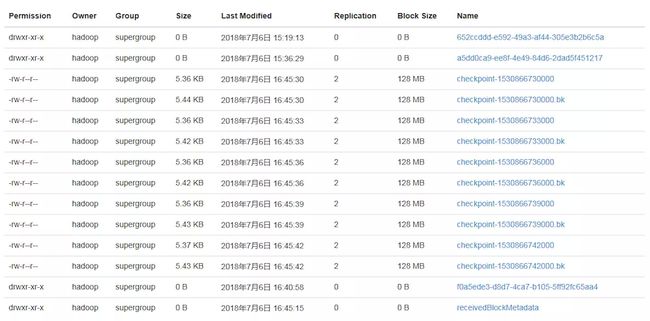
3.checkpoint

在我们设置的checkpoint文件夹里保存了最近5次的checkpoint,在线上程序一般保存到hdfs里。
作者:阿坤的博客
链接:https://www.jianshu.com/p/30614ff250b5
来源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。