前言:
文章以Andrew Ng 的 deeplearning.ai 视频课程为主线,记录Programming Assignments 的实现过程。相对于斯坦福的CS231n课程,Andrew的视频课程更加简单易懂,适合深度学习的入门者系统学习!
本次作业主要是练习正交化,使用正交化可以有效缓解数据过拟合,提高网络的性能。正交化主要有两种方式实现,Regularization和Dropout,下面我们分别对这两种方式进行实现。
1.1 Dataset
首先还是看一下这次的数据集,还是一个binary classification问题。
train_X, train_Y, test_X, test_Y = load_2D_dataset()

1.2 Non-regularized model
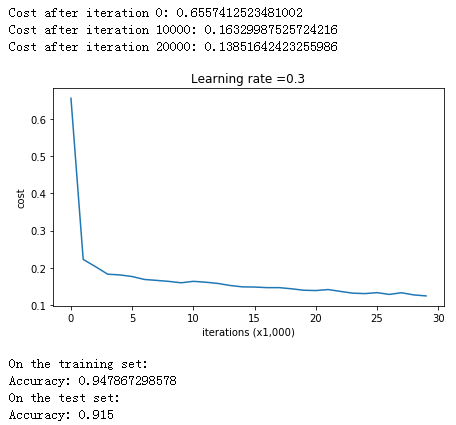
我们首先看一下在没有正规化的情况下,网络的训练效果:
def model(X, Y, learning_rate = 0.3, num_iterations = 30000, print_cost = True, lambd = 0, keep_prob = 1):
grads = {}
costs = []
m = X.shape[1]
layers_dims = [X.shape[0], 20, 3, 1]
parameters = initialize_parameters(layers_dims)
for i in range(0, num_iterations):
if keep_prob == 1:
a3, cache = forward_propagation(X, parameters)
elif keep_prob < 1:
a3, cache = forward_propagation_with_dropout(X, parameters, keep_prob)
# Cost function
if lambd == 0:
cost = compute_cost(a3, Y)
else:
cost = compute_cost_with_regularization(a3, Y, parameters, lambd)
assert(lambd==0 or keep_prob==1)
if lambd == 0 and keep_prob == 1:
grads = backward_propagation(X, Y, cache)
elif lambd != 0:
grads = backward_propagation_with_regularization(X, Y, cache, lambd)
elif keep_prob < 1:
grads = backward_propagation_with_dropout(X, Y, cache, keep_prob)
parameters = update_parameters(parameters, grads, learning_rate)
if print_cost and i % 10000 == 0:
print("Cost after iteration {}: {}".format(i, cost))
if print_cost and i % 1000 == 0:
costs.append(cost)
plt.plot(costs)
plt.ylabel('cost')
plt.xlabel('iterations (x1,000)')
plt.title("Learning rate =" + str(learning_rate))
plt.show()
return parameters
parameters = model(train_X, train_Y)
print ("On the training set:")
predictions_train = predict(train_X, train_Y, parameters)
print ("On the test set:")
predictions_test = predict(test_X, test_Y, parameters)
训练结果如下:
我们再看一下训练结果形成的decision boundary
plt.title("Model without regularization")
axes = plt.gca()
axes.set_xlim([-0.75,0.40])
axes.set_ylim([-0.75,0.65])
plot_decision_boundary(lambda x: predict_dec(parameters, x.T), train_X, train_Y)
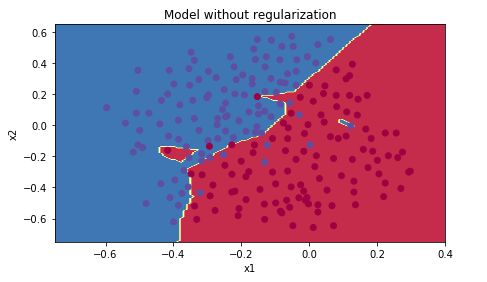
从decision boundary中可以看出训练的网络明显过拟合了。
1.3 L2 Regularization
L2 Regularization主要针对的是权值的L2范数,相应的在前向算法计算cost函数和后向算法中都要做相应的修改
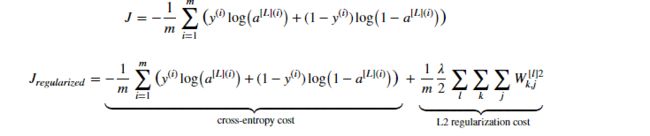
cost函数:
def compute_cost_with_regularization(A3, Y, parameters, lambd):
m = Y.shape[1]
W1 = parameters["W1"]
W2 = parameters["W2"]
W3 = parameters["W3"]
cross_entropy_cost = compute_cost(A3, Y)
L2_regularization_cost=lambd/(2*m)*(np.sum(W1*W1)+np.sum(W2*W2)+np.sum(W3*W3))
cost = cross_entropy_cost + L2_regularization_cost
return cost
后向算法:
def backward_propagation_with_regularization(X, Y, cache, lambd):
m = X.shape[1]
(Z1, A1, W1, b1, Z2, A2, W2, b2, Z3, A3, W3, b3) = cache
dZ3 = A3 - Y
dW3 = 1./m * np.dot(dZ3, A2.T) + lambd/m*W3
db3 = 1./m * np.sum(dZ3, axis=1, keepdims = True)
dA2 = np.dot(W3.T, dZ3)
dZ2 = np.multiply(dA2, np.int64(A2 > 0))
dW2 = 1./m * np.dot(dZ2, A1.T) + lambd/m*W2
db2 = 1./m * np.sum(dZ2, axis=1, keepdims = True)
dA1 = np.dot(W2.T, dZ2)
dZ1 = np.multiply(dA1, np.int64(A1 > 0))
dW1 = 1./m * np.dot(dZ1, X.T) + lambd/m*W1
db1 = 1./m * np.sum(dZ1, axis=1, keepdims = True)
gradients = {"dZ3": dZ3, "dW3": dW3, "db3": db3,"dA2": dA2,
"dZ2": dZ2, "dW2": dW2, "db2": db2, "dA1": dA1,
"dZ1": dZ1, "dW1": dW1, "db1": db1}
return gradients
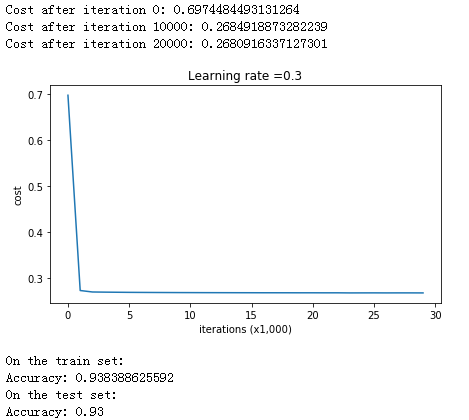
现在我们加入L2 Regularization后对模型的训练结果如下:
parameters = model(train_X, train_Y, lambd = 0.7)
print ("On the train set:")
predictions_train = predict(train_X, train_Y, parameters)
print ("On the test set:")
predictions_test = predict(test_X, test_Y, parameters)
我们再看一下加入L2 Regularization后形成的decision boundary
plt.title("Model with L2-regularization")
axes = plt.gca()
axes.set_xlim([-0.75,0.40])
axes.set_ylim([-0.75,0.65])
plot_decision_boundary(lambda x: predict_dec(parameters, x.T), train_X, train_Y)
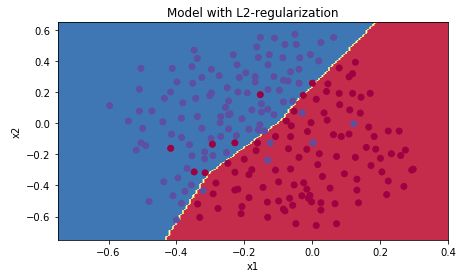
可以明显看到过拟合的情况得到了有效的缓解,L2 Regularization 使 decision boundary 变得smoother,但是L2 Regularization中的超参数lambd需要tune
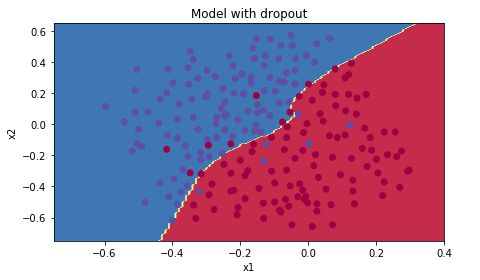
1.3 Dropout
dropout也是正规化常用的手段,在每次迭代训练的过程中随机关闭一些神经元,这些关闭的神经元对前向过程和反向梯度过程都不make contribution,通过这样的方式来避免过拟合的情况。我们来看一下具体的代码实现:
前向过程:
def forward_propagation_with_dropout(X, parameters, keep_prob = 0.5):
np.random.seed(1)
W1 = parameters["W1"]
b1 = parameters["b1"]
W2 = parameters["W2"]
b2 = parameters["b2"]
W3 = parameters["W3"]
b3 = parameters["b3"]
Z1 = np.dot(W1, X) + b1
A1 = relu(Z1)
D1 = np.random.rand(A1.shape[0],A1.shape[1])
D1 = D1 A1 = A1*D1 A1/=keep_prob Z2=np.dot(W2,A1)+b2 A2=relu(Z2) D2=np.random.rand(A2.shape[0],A2.shape[1]) D2=D2 D2=D2 A2=A2*D2 A2/=keep_prob Z3=np.dot(W3,A2)+b3 A3=sigmoid(Z3) cache = (Z1, D1, A1, W1, b1, Z2, D2, A2, W2, b2, Z3, A3, W3, b3) return A3, cache 反向过程:前向过程关闭的神经元在反向过程中同样关闭即可 def backward_propagation_with_dropout(X, Y, cache, keep_prob): m=Y.shape[1] (Z1, D1, A1, W1, b1, Z2, D2, A2, W2, b2, Z3, A3, W3, b3) = cache dZ3=A3-Y dW3 = 1 / m * np.dot(dZ3, A2.T) db3 = 1 / m * np.sum(dZ3, axis=1, keepdims=True) dA2 = np.dot(W3.T, dZ3) dA2=dA2*D2/keep_prob temp = np.copy(dA2) temp[Z2 < 0] = 0 dZ2 = temp dW2 = 1 / m * np.dot(dZ2, A1.T) db2 = 1 / m * np.sum(dZ2, axis=1, keepdims=True) dA1= np.dot(W2.T, dZ2) dA1 = dA1* D1 / keep_prob temp = np.copy(dA1) temp[Z1 < 0] = 0 dZ1 = temp dW1 = 1 / m * np.dot(dZ1, X.T) db1 = 1 / m * np.sum(dZ1, axis=1, keepdims=True) gradients = {"dZ3": dZ3, "dW3": dW3, "db3": db3, "dA2": dA2, "dZ2": dZ2, "dW2": dW2, "db2": db2, "dA1": dA1, "dZ1": dZ1, "dW1": dW1, "db1": db1} return gradients 现在我们对加入Dropout后对模型的训练结果: parameters = model(train_X, train_Y, keep_prob = 0.86, learning_rate = 0.3) print ("On the train set:") predictions_train = predict(train_X, train_Y, parameters) print ("On the test set:") predictions_test = predict(test_X, test_Y, parameters) 我们再看一下decision boundary 注意:Dropout 仅仅使用在train阶段,而不能将其使用在test阶段 最后附上我作业的得分,表示我程序没有问题,如果觉得我的文章对您有用,请随意打赏,我将持续更新Deeplearning.ai的作业!