记录调试遇到的问题
1.warnings.warn(old_gpu_warn % (d, name, major, capability[1]))
Mnist_attention.py:60: UserWarning: invalid index of a 0-dim tensor. This will be an error in PyTorch 0.5. Use tensor.item() to convert a 0-dim tensor to a Python number
100. * batch_idx / len(train_loader), loss.data[0]))
解决办法:把loss.data[0])改为loss.item()
2. _tkinter.TclError: Can't find a usable init.tcl in the following directories:
/opt/anaconda1anaconda2anaconda3/lib/tcl8.5 /home/vivian/HelloWorld/helloworld/lib/tcl8.5 /home/vivian/HelloWorld/lib/tcl8.5 /home/vivian/HelloWorld/helloworld/library /home/vivian/HelloWorld/library /home/vivian/HelloWorld/tcl8.5.18/library /home/vivian/tcl8.5.18/library
This probably means that Tcl wasn't installed properly.解决办法:找到缺的,把整个tcl8.5文件夹复制到虚拟环境(需要用到的环境中)、
ps:改好后还会缺 tk, 同法
3.
UserWarning: volatile was removed and now has no effect. Use `with torch.no_grad():` instead.
label = Variable(label.cuda(), volatile=True)修改方法如下:
#原语句
label = Variable(label.cuda(), volatile=True)
#修改后语句
label = Variable(label.cuda())
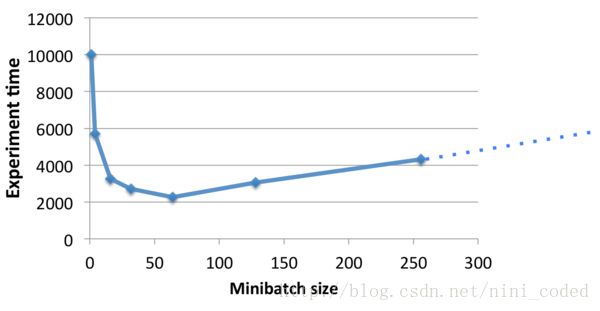
1.Batch_size的使用意义及大小的选择
Batch_size不宜选的太小,太小了容易不收敛,或者需要经过很大的epoch才能收敛;也没必要选的太大,太大的话首先显存受不了,其次可能会因为迭代次数的减少而造成参数修正变的缓慢。
http://blog.csdn.net/ycheng_sjtu/article/details/49804041这篇文章很详细的介绍了Batch_size的使用意义和选择原则,并且进行了试验来比较Batch_size对训练结果的影响情况,非常值得一看。
2.Batch_size有时候明明已经很小了,可显存还是很紧张,还有就是同样的图片大小,同样的Batch_size,为啥有时候显存够用有时候就不够用呢,目前我所知道的可能是如下四个问题:
(1)模型的复杂度,复杂的模型占的内存比简单的模型要大很多,这一点容易被忽略;
(2)电脑可能还在运行其他占显存的任务,使用nvida-smi命令来查看,并关闭它们;
(3)不光train阶段的Batch_size要改,test阶段的Batch_size也要调小,我以前一直以为只改动train的就可以了,too naive;
(4)图片大小,这个好理解
部分参考自Stack Overflow :https://stackoverflow.com/questions/33790366/caffe-check-failed-error-cudasuccess-2-vs-0-out-of-memory
batch_size、epoch、iteration是深度学习中常见的几个超参数:
(1)batchsize:每批数据量的大小。DL通常用SGD的优化算法进行训练,也就是一次(1 个iteration)一起训练batchsize个样本,计算它们的平均损失函数值,来更新参数。
(2)iteration:1个iteration即迭代一次,也就是用batchsize个样本训练一次。
(3)epoch:1个epoch指用训练集中的全部样本训练一次,此时相当于batchsize 等于训练集的样本数。
最初训练DNN采用一次对全体训练集中的样本进行训练(即使用1个epoch),并计算一次损失函数值,来更新一次权值。当时数据集较小,该方法尚可。后来随着数据集迅速增大,导致这种方法一次开销大进而占用内存过大,速度过慢。
后来产生了一次只训练一个样本的方法(batchsize=1),称作在线学习。该方法根据每一个样本的情况更新一次权值,开销小速度快,但收到单个样本的巨大随机性,全局来看优化性能较差,收敛速度很慢,产生局部震荡,有限迭代次数内很可能无法收敛。
目前常用随机梯度下降SGD来训练,相当于上述两个“极端”方法的折中:将训练集分成多个mini_batch(即常说的batch),一次迭代训练一个minibatch(即batchsize个样本),根据该batch数据的loss更新权值。这相比于全数据集训练,相当于是在寻找最优时人为增加了一些随机噪声,来修正由局部数据得到的梯度,尽量避免因batchsize过大陷入局部最优。
这种方法存在两对矛盾。由于一次只分析的一小部分数据,因此整体优化效果与batchsize有关:
batchsize越小,一个batch中的随机性越大,越不易收敛。然而batchsize越小,速度越快,权值更新越频繁;且具有随机性,对于非凸损失函数来讲,更便于寻找全局最优。从这个角度看,收敛更快,更容易达到全局最优。
batchsize越大,越能够表征全体数据的特征,其确定的梯度下降方向越准确,(因此收敛越快),且迭代次数少,总体速度更快。然而大的batchsize相对来讲缺乏随机性,容易使梯度始终向单一方向下降,陷入局部最优;而且当batchsize增大到一定程度,再增大batchsize,一次batch产生的权值更新(即梯度下降方向)基本不变。因此理论上存在一个最合适的batchsize值,使得训练能够收敛最快或者收敛效果最好(全局最优点)。
根据现有的调参经验,加入正则化项BN后,在内存容量允许的情况下,一般来说设置一个较大的batchsize值更好,通常从128开始调整。
https://blog.csdn.net/nini_coded/article/details/79250703