SparkSQL创建表的几种方式
数据格式:7654,MARTIN,SALESMAN,7698,1981/9/28,1250,1400,30
// 需要导入的包
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.sql.catalyst.encoders.ExpressionEncoder
import org.apache.spark.sql.Encoder
import org.apache.spark.sql.Row
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.types._
import org.apache.spark.sql._
import org.apache.spark.sql.types._
1. 使用case class定义表
case class Emp(empno: Int, ename: String, job: String, mgr: String,
hiredate: String, sal: Int, comm: String, deptno: Int);
object Emps {
def main(args: Array[String]) {
// 创建一个SparkSession
val spark = SparkSession.builder().master("local").appName("sql").getOrCreate()
import spark.sqlContext.implicits._
// 导入emp.csv文件(导入数据)
val lines = spark.sparkContext.textFile("G:/emp.csv").map(_.split(","));
// 生成表: DataFrame
val allEmp = lines.map(x=>Emp(x(0).toInt,x(1),x(2),x(3),x(4),x(5).toInt,x(6),x(7).toInt))
//由allEmp直接生成表
val empDF = allEmp.toDF()
println(empDF.show());
}
}
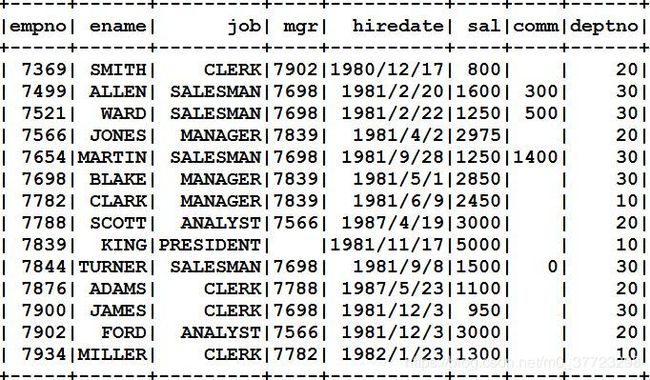
执行结果:

2.使用SparkSession对象
object Emps {
def main(args: Array[String]) {
// 创建一个SparkSession
val spark = SparkSession.builder().master("local").appName("sql").getOrCreate()
import spark.sqlContext.implicits._
// 导入emp.csv文件(导入数据)
val lines = spark.sparkContext.textFile("G:/emp.csv").map(_.split(","));
val myschema = StructType(List(StructField("empno", DataTypes.IntegerType),
StructField("ename", DataTypes.StringType),
StructField("job", DataTypes.StringType),
StructField("mgr", DataTypes.StringType),
StructField("hiredate", DataTypes.StringType),
StructField("sal", DataTypes.IntegerType),
StructField("comm", DataTypes.StringType),
StructField("deptno", DataTypes.IntegerType)))
// 把读入的每一行数据映射成一个个Row
val rowRDD = lines.map(x => Row(x(0).toInt, x(1), x(2), x(3), x(4), x(5).toInt, x(6), x(7).toInt))
val df = spark.createDataFrame(rowRDD,myschema)
println(df.show());
}
}
执行结果:
3.直接读取一个带格式的文件(json文件) —> 最简单
// josn格式
{"name":"Michael"}
{"name":"Andy", "age":30}
{"name":"Justin", "age":19}
object Emps {
def main(args: Array[String]) {
// 创建一个SparkSession
val spark = SparkSession.builder().master("local").appName("sql").getOrCreate()
import spark.sqlContext.implicits._
val df = spark.read.json("G:/person.json")
println(df.show())
}
}
执行结果:
