记录一次dubbo线程池满Thread pool exhausted排查和解决
先看日志报出的线程池线程满的日志信息:

在初始时候,dubbo协议配置,我是使用dubbo默认的参数,dubbo线程池默认是固定长度线程池,大小为200。一开始出现线程池满的问题,本以为是并发量大导致的,没做太多关注,运维也没有把相应的日志dump下来,直接重启了。所以一开始只是优化了dubbo的配置。调大固定线程池数量为400,并且将dispatcher转发由默认的配置"all"改为message。all表示所有消息都派发到线程池,包括请求,连接事件,断开事件,心跳等。message表示只有请求响应消息派发到线程池,其他连接断开事件,心跳等消息,直接在IO线程上执行。同时开启了访问日志记录,观察是不是有出现其他消费系统有短时间大并发调用接口的情况。
通过日志观察几天下来,大概每天接口的调用量在60~70万左右,瞬时并发调用量也就十几,理论上不应该出现线程池满的情况,所以这时候就怀疑是不是有出现线程Blocked的情况,这时候便想通过日志记录一下线上的dubbo线程池的情况,即在未出现线程池满之前能够及时发现问题。所以就增加了一个切面。切点是接口中的所有方法。在调用前和调用后打印线程池信息的日志。通过查看线程池源码我们可知,线程池的toString()方法,记录了线程池的情况信息
public String toString() {
long ncompleted;
int nworkers, nactive;
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
ncompleted = completedTaskCount;
nactive = 0;
nworkers = workers.size();
for (Worker w : workers) {
ncompleted += w.completedTasks;
if (w.isLocked())
++nactive;
}
} finally {
mainLock.unlock();
}
int c = ctl.get();
String rs = (runStateLessThan(c, SHUTDOWN) ? "Running" :
(runStateAtLeast(c, TERMINATED) ? "Terminated" :
"Shutting down"));
return super.toString() +
"[" + rs +
", pool size = " + nworkers +
", active threads = " + nactive +
", queued tasks = " + workQueue.size() +
", completed tasks = " + ncompleted +
"]";
}由上述源码我们通过dubbo的 dataStore对象可以获取dubbo线程池的实例,从而打印其toString()信息
import com.alibaba.dubbo.common.Constants;
import com.alibaba.dubbo.common.extension.ExtensionLoader;
import com.alibaba.dubbo.common.store.DataStore;
import org.aspectj.lang.annotation.After;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Before;
import org.aspectj.lang.annotation.Pointcut;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.stereotype.Component;
import java.util.Map;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.ThreadPoolExecutor;
/**
* @ClassName DubboAOP
* @Description
* @Author libo
* @Date 2019/7/25 11:46
* @Version 1.0
**/
@Component
@Aspect
public class DubboAOP {
private static final Logger logger = LoggerFactory.getLogger(DubboAOP.class);
@Pointcut("execution(* com.ncarzone.oa.biz.facade.EmployeeServiceFacadeImpl.*(..))")
public void pointCut(){
}
@Before("pointCut()")
public void before(){
logger.info("======before()======"+Thread.currentThread().getName());
printDubboThreadInfo();
}
@After("pointCut()")
public void after(){
printDubboThreadInfo();
logger.info("======after()==="+Thread.currentThread().getName());
}
private void printDubboThreadInfo(){
DataStore dataStore = ExtensionLoader.getExtensionLoader(DataStore.class).getDefaultExtension();
Map executors = dataStore.get(Constants.EXECUTOR_SERVICE_COMPONENT_KEY);
for(Map.Entry entry : executors.entrySet()){
ExecutorService executor = (ExecutorService)entry.getValue();
if(executor instanceof ThreadPoolExecutor){
ThreadPoolExecutor tp = (ThreadPoolExecutor) executor;
logger.info("===dubboThread======"+tp.toString());
}
}
}
}

不幸的是,在经过今天之后,线程池满的问题又暴露出来了,日志如下图所示,可以根据我们写的切面的日志打印信息可以看到活跃线程一直在增加,即一个新的请求过来之后,就没有下文了,线程没有运行完,自然就无法被回收到线程池中。因而判断极有可能是线程出现阻塞或者是一直在等待的情况。所以这次直接让运维人员帮忙dump下线程日志。 jstack + pid xxx.log
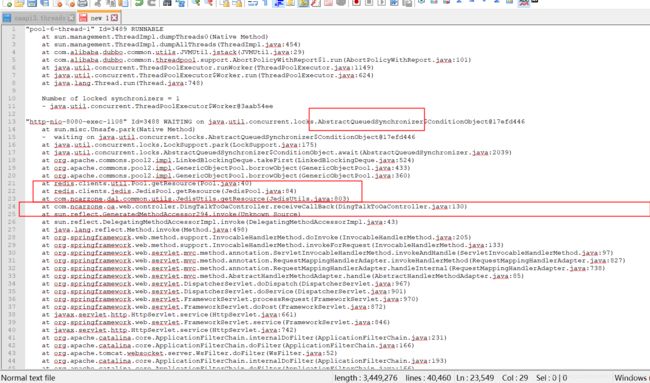

通过线程dump日志,我们可以看到出现了大量线程的等待,dump中记录了出问题的代码之处。通过分析,可知在获取redis连接,去取redis数据的时候,由于没有拿到redis的连接,即getResource方法执行卡住了,同时项目的redis配置又没有设置获取连接的最大超时时间,通过redis源码我们可知,如果没有设置,则默认是-1,即可能会出现长时间等待获取连接的情况。它会从空闲的连接队列(private final LinkedBlockingDeque


因而我们需要在项目的jedis连接池配置中增加MaxWaitMillis配置,我这里设置的是500毫秒。

现在知道了是此种情况导致的,但是因为我项目里配置的最大分配连接是600,而项目里使用redis的地方并不多,理论上不应该出现redis连接池满的情况,应该还是有其他问题。所以继续看了thread dump日志,发现了问题点所在,因为之前和钉钉的开放平台对接,做了一个回调接口,但偶尔会出现重复回调的情况,所以就做了一个redis锁,来避免这个问题。但是这边代码有严重的问题,如果jedis设置缓存不成功,则会进入线程休眠,线程休眠是不会释放所持有的连接的,而这个地方就陷入了死循环。导致该连接被一直占用,从而连接池中可用的连接越来越少,直到被占满。

将此处代码做了修改.使用sleep虽然保证了线程安全,但是影响性能。修改为根据userIds进行加锁,代码如下:
DingTalkEncryptor dingTalkEncryptor = null;
String plainText;
String userIds = "";
//获取Jedis实例
Jedis jedis = JedisUtils.getResource();
// synchronized (DingTalkToOaController.class){
try {
dingTalkEncryptor = new DingTalkEncryptor(TOKEN,AESKEY, Global.getConfig("corpId"));
if(json != null){
String encrypt = json.getString("encrypt");
plainText = dingTalkEncryptor.getDecryptMsg(signature, timestamp, nonce, encrypt);
//对从encrypt解密出来的明文进行处理
JSONObject plainTextJson = JSONObject.parseObject(plainText);
String eventType = plainTextJson.getString("EventType");
JSONArray userIdArray = plainTextJson.getJSONArray("UserId");
JSONArray jsonArray = new JSONArray();
if(!StringUtils.equals(eventType,CHECK)){
StringBuilder sb = new StringBuilder();
for(Object str : userIdArray){
sb.append(str.toString()+",");
}
userIds = sb.substring(0,sb.length()-1);
if(jedis.setnx(userIds,DigitConstant.STR_1) == 0){
LOGGER.info("=====redis获取锁不成功,直接return==========="+userIds);
return;
}
jedis.expire(userIds,3);
//由userId查询其智能人事信息.添加到oa
DingTalkClient client = new DefaultDingTalkClient("https://oapi.dingtalk.com/topapi/smartwork/hrm/employee/list");
OapiSmartworkHrmEmployeeListRequest req = new OapiSmartworkHrmEmployeeListRequest();
req.setUseridList(userIds);
OapiSmartworkHrmEmployeeListResponse rsp ;
try {
rsp = client.execute(req, getAccessToken());
String result = rsp.getBody();
JSONObject jsonData = JSONObject.parseObject(result);
jsonArray = jsonData.getJSONArray("result");
} catch (ApiException e) {
e.printStackTrace();
LOGGER.error("====获取智能人事信息失败===",ExceptionUtils.getMessage(e));
}
}
LOGGER.info("===事件类型===="+eventType);
switch (eventType){
case "user_add_org":
syncOrgElementsBaseInfo(jsonArray);
break;
case "user_modify_org":
syncOrgElementsBaseInfo(jsonArray);
break;
case "user_leave_org":
//将其置为离职
updateOrgElement(jsonArray);
break;
case "check_url":
default :
break;
}
}
} catch (DingTalkEncryptException e) {
LOGGER.error("====receiveCallBack===钉钉解析异常==={}",ExceptionUtils.getMessage(e));
}finally {
jedis.del(userIds);
JedisUtils.returnResource(jedis);
}至此优化完成,线上dubbo接口调用日志如下所示:

当然最终运行情况还要观察几天。并隔断时间找运维dump一下线程日志,分析下是否问题真正得到解决~ 通过此次线上问题的排查也是学习了一些工具的使用,例如Memory Analynize Tool, Jvisualvm等,因为线上实时监控工具不足,所以一开始是分析了堆的dump文件,查看JVM运行情况。。。 通过此次排查得到了一个结论就是不能抱着侥幸心理啊,处理问题并非偶然,需要自己多加上心。