参考源码:Spark 2.0 mllib Kmeans
大概用时三小时,虽说大部分和源码都一样,但是自己写的过程中,还是学到了很多东西。
package org.apache.spark.myExamples
import breeze.optimize.MaxIterations
import org.apache.spark.SparkContext
import org.apache.spark.internal.Logging
import org.apache.spark.mllib.linalg.BLAS._
import org.apache.spark.rdd.RDD
import org.apache.spark.util.Utils
import org.apache.spark.mllib.linalg.{SparseVector, Vector, Vectors}
import org.apache.spark.mllib.pmml.PMMLExportable
import org.apache.spark.mllib.util.{MLUtils, Saveable}
import org.apache.spark.sql.SparkSession
import org.apache.spark.storage.StorageLevel
import org.apache.spark.util.random.XORShiftRandom
/**
* Created by wjf on 16-9-2.
*/
object MySparkKmeans {
def main(args: Array[String]): Unit = {
val spark =SparkSession.builder().appName("test my sparkKmeans").master("local").getOrCreate()
val sc =spark.sparkContext
val lines =sc.textFile("data/mllib/kmeans_data.txt")
val data =lines.map(line => Vectors.dense(line.split(" ").map(_.toDouble))).cache()
val maxIterations =20
val K=2
val seed =42L
val epsilon =0.1
val kmeans =new MySparkKMeans(K,maxIterations,epsilon,seed)
val model :KMeansModel=kmeans.run(data)
model.centers.foreach(println)
// val a= new A(1,2)
// println(a.K)
//// println(a.n)
// a.K =100
// println(a.K)
}
}
class MySparkKMeans (private var K:Int,
private var maxIterations:Int,
private var epsilon:Double,
private var seed:Long) extends Serializable with Logging {
val EPSILON=1e-4
// there is a private ,we can't use default main construct
// default constructor
def this() =this(2,20,1e-4,Utils.random.nextLong())
// private var a:Int
def getK:Int =K
def setK(K:Int):this.type ={
require(K >0,s"Number of clusters must be positive but go ${K}")
this.K =K
this
}
def getMaxIterations:Int =maxIterations
def setMaxIterations(maxIterations: Int):this.type={
require( maxIterations >0 ,s"Maximum of iterations must be nonnegative but got ${maxIterations}")
this.maxIterations=maxIterations
this
}
def getEpsilon:Double =epsilon
def setEpsilon(epsilon:Double): this.type={
require(epsilon >0 ,s"Distance threshold must be nonnegative but got ${epsilon}")
this.epsilon =epsilon
this
}
def getSeed:Long =seed
def setSeed(seed:Long):this.type ={
this.seed=seed
this
}
def run(data: RDD[Vector]):KMeansModel ={
if(data.getStorageLevel == StorageLevel.NONE){
logWarning("This input data is not directly cached, which may hurt performance if its" +
" parent RDDs are also uncached.")
}
val norms =data.map(Vectors.norm(_,2.0))
norms.persist()
val zippedData = data.zip(norms).map{ case( v,norm) =>
new VectorWithNorm(v,norm)
}
val model =runAlgorithm(zippedData)
norms.unpersist()
model
}
private def initCenters(data :RDD[VectorWithNorm]): Array[VectorWithNorm] ={
val sample =data.takeSample(true,K,new XORShiftRandom(this.seed).nextInt()).toSeq
// run many times, it's useless in spark 2.0
// val runs =10
// Array.tabulate(runs)(r => sample.slice(K , (r+1)*K).map{
// v => new VectorWithNorm(Vectors.dense(v.vector.toArray),v.norm)
// }.toArray)
sample.map( v => new VectorWithNorm(Vectors.dense(v.vector.toArray),v.norm)).toArray
}
private def findClosest(centers: TraversableOnce[VectorWithNorm], point: VectorWithNorm): (Int, Double) = {
var bestDistance = Double.PositiveInfinity
var bestIndex = 0
var i = 0
centers.foreach { center =>
// Since `\|a - b\| \geq |\|a\| - \|b\||`, we can use this lower bound to avoid unnecessary
// distance computation.
var lowerBoundOfSqDist = center.norm - point.norm
lowerBoundOfSqDist = lowerBoundOfSqDist * lowerBoundOfSqDist
if (lowerBoundOfSqDist < bestDistance) {
val distance: Double = fastSquaredDistance(center, point)
if (distance < bestDistance) {
bestDistance = distance
bestIndex = i
}
}
i += 1
}
(bestIndex, bestDistance)
}
private def fastSquaredDistance(v1: Vector, norm1: Double, v2: Vector, norm2: Double, precision: Double = 1e-6): Double = {
val n = v1.size
require(v2.size == n)
require(norm1 >= 0.0 && norm2 >= 0.0)
val sumSquaredNorm = norm1 * norm1 + norm2 * norm2
val normDiff = norm1 - norm2
var sqDist = 0.0
/*
* The relative error is
*
* EPSILON * ( \|a\|_2^2 + \|b\\_2^2 + 2 |a^T b|) / ( \|a - b\|_2^2 ),
*
* which is bounded by
*
* 2.0 * EPSILON * ( \|a\|_2^2 + \|b\|_2^2 ) / ( (\|a\|_2 - \|b\|_2)^2 ).
*
* The bound doesn't need the inner product, so we can use it as a sufficient condition to
* check quickly whether the inner product approach is accurate.
*/
val precisionBound1 = 2.0 * EPSILON * sumSquaredNorm / (normDiff * normDiff + EPSILON)
if (precisionBound1 < precision) {
sqDist = sumSquaredNorm - 2.0 * dot(v1, v2)
} else if (v1.isInstanceOf[SparseVector] || v2.isInstanceOf[SparseVector]) {
val dotValue = dot(v1, v2)
sqDist = math.max(sumSquaredNorm - 2.0 * dotValue, 0.0)
val precisionBound2 = EPSILON * (sumSquaredNorm + 2.0 * math.abs(dotValue)) /
(sqDist + EPSILON)
if (precisionBound2 > precision) {
sqDist = Vectors.sqdist(v1, v2)
}
} else {
sqDist = Vectors.sqdist(v1, v2)
}
sqDist
}
private def fastSquaredDistance(v1: VectorWithNorm, v2: VectorWithNorm): Double = {
fastSquaredDistance(v1.vector, v1.norm, v2.vector, v2.norm)
}
private def runAlgorithm(data: RDD[VectorWithNorm]):KMeansModel= {
val sc = data.sparkContext
val centers = initCenters(data)
val iterationStartTime = System.nanoTime()
var costs = 0.0
var iteration = 0
// most important code of kmeans
while (iteration < maxIterations) {
type WeightedPoint = (Vector, Long)
def mergeContribs(x: WeightedPoint, y: WeightedPoint): WeightedPoint = {
axpy(1.0, x._1, y._1)
(y._1, x._2 + y._2)
}
val bcCenters = sc.broadcast(centers)
val costAccums = sc.doubleAccumulator
val totalContribs = data.mapPartitions { points =>
val thisCenters = bcCenters.value
val k = thisCenters.length
val dims = thisCenters(0).vector.size
val sums = Array.fill(k)(Vectors.zeros(dims))
val counts = Array.fill(k)(0L)
points.foreach { point =>
val (bestCenter, cost) = findClosest(thisCenters, point)
val sum = sums(bestCenter)
costAccums.add(cost)
axpy(1.0, point.vector, sum)
counts(bestCenter) += 1
}
val contribs = for (j <- 0 until k) yield {
(j, (sums(j), counts(j)))
}
contribs.iterator
}.reduceByKey(mergeContribs).collectAsMap()
bcCenters.unpersist(blocking = false)
var j = 0
while (j < K) {
val (sum, count) = totalContribs(j)
if (count != 0) {
scal(1.0 / count, sum)
val newCenter = new VectorWithNorm(sum)
// if(fastSquaredDistance(newCenter,centers(j)) > epsilon * epsilon){
//
// }
centers(j) = newCenter
}
j += 1
}
costs = costAccums.value
iteration += 1
}
val iterationTimeSeconds =(System.nanoTime() - iterationStartTime) /1e9
logInfo(s"Iterations took " + "%.3f".format(iterationTimeSeconds) + " seconds.")
if(iteration == maxIterations) {
logInfo(s"KMeans reached the max number of iteration: $maxIterations.")
}
new KMeansModel(centers.map(_.vector))
}
}
class KMeansModel(val centers:Array[Vector]) extends Saveable with Serializable with PMMLExportable{
def getCenters:Array[Vector] = centers
/**
* Save this model to the given path.
*
* This saves:
* - human-readable (JSON) model metadata to path/metadata/
* - Parquet formatted data to path/data/
*
* The model may be loaded using `Loader.load`.
*
* @param sc Spark context used to save model data.
* @param path Path specifying the directory in which to save this model.
* If the directory already exists, this method throws an exception.
*/
override def save(sc: SparkContext, path: String): Unit = {
}
/** Current version of model save/load format. */
override protected def formatVersion: String ="1.0"
}
class VectorWithNorm(val vector: Vector,val norm :Double) extends Serializable{
def this(vector: Vector) = this(vector, Vectors.norm( vector,2.0))
def this(array: Array[Double]) = this(Vectors.dense(array))
// converts the vector to a dense vector
def toDense: VectorWithNorm = new VectorWithNorm(Vectors.dense(vector.toArray),norm)
}
//class A(var K:Int, private var n:Int){
//
//}
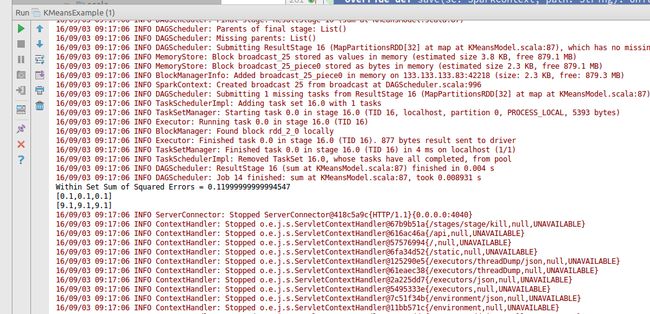
运行结果,ok
QQ截图20160903091933.png