爬虫--解析库的使用 XPath、BeautifulSoup、pyquery
1. XPath
XPath , 全称XML Path Language ,即XML 路径语言,它是一门在XML 文档中查找信息的语言。它最初是用来搜寻XML 文档的,但是它同样适用于HTML 文档的搜索。
XPath 的选择功能十分强大,它提供了非常简洁明了的路径选择表达式。另外,它还提供了超过100 个内建函数,用于字符串、数值、时间的匹配以及节点、序列的处理等。几乎所有我们想要定位的节点,都可以用XPath 来选择。

from lxml import etree
text = '''
'''
html = etree.HTML(text)
result= etree.tostring(html)
print(result.decode('utf-8'))


7. 父节点
from lxml import etree
html = etree.parse('F:\\spider\\XPath\\test.html', etree.HTMLParser())
result = etree.tostring(html)
res = html.xpath('//a[@href="link4.html"]/../@class') # 或者下面的写法
# res = html.xpath('//a[@href="link4.html"]/parent::*/@class')
print(result.decode('utf-8'))
print('\n', res)

9. 文本获取
from lxml import etree
html = etree.parse('F:\\spider\\XPath\\test.html', etree.HTMLParser())
res = html.xpath('//li[@class="item-0"]/a/text()') # 文本获取
print(res)
# ['first item', 'fifth item']这里我们是逐层选取的,先选取了li 节点,又利用/选取了其直接子节点儿然后再选取其文本,得到的结果恰好是符合我们预期的两个结果。
from lxml import etree
html = etree.parse('F:\\spider\\XPath\\test.html', etree.HTMLParser())
res = html.xpath('//li[@class="item-0"]//text()') # 文本获取
print(res)
# ['first item', 'fifth item', '\r\n\t']不出所料,这里的返回结果是3 个。可想而知,这里是选取所有子孙节点的文本,其中前两个就是li 的子节点a 节点内部的文本,另外一个就是最后一个li 节点内部的文本,即换行符。
10 . 属性获取
我们知道用text ()可以获取节点内部文本,那么节点属性该怎样获取呢?其实还是用@符号就可以。例如,我们想获取所有li 节点下所有a 节点的href 属性,代码如下:
from lxml import etree
# 属性获取
html = etree.parse('F:\\spider\\XPath\\test.html', etree.HTMLParser())
res = html.xpath('//li/a/@href') # 文本获取
print(res)
# ['linkl.html', 'link2.html', 'link3.html', 'link4.html', 'link5.html']

13. 按序选择
有时候,我们在选择的时候某些属性可能同时匹配了多个节点,但是只想要其中的某个节点,如第二个节点或者最后一个节点。这时可以利用中括号传入索引的方法获取特定次序的节点。
from lxml import etree
text = '''
'''
html = etree.parse("F:/spider/XPath/test.html", etree.HTMLParser())
res = html.xpath("//li/a/text()") # 注意:这里的下标从1开始
res1 = html.xpath("//li[1]/a/text()")
res2 = html.xpath("//li[last()]/a/text()")
res3 = html.xpath("//li[position()<3]/a/text()")
res5 = html.xpath("//li[last()-2]/a/text()")
print(res, res1, res2, res3, res5, sep='\n')
# ['first item', 'second item', 'third item', 'fourth item', 'fifth item']
# ['first item']
# ['fifth item']
# ['first item', 'second item']
# ['third item']第一次选择时,我们选取了第一个li 节点,中括号中传入数字1即可。注意,这里和代码中不同,序号是以1 开头的,不是以0 开头。
14. 节点轴选择
XPath 提供了很多节点轴选择方法,包括获取子元素、兄弟元素、父元素、祖先元素等。
from lxml import etree
text = '''
'''
html = etree.HTML(text)
res = html.xpath("//li[1]/ancestor::*") # 注意:这里的下标从1开始
print(res)
# [, , , ]
res = html.xpath("//li[1]/ancestor::div")
print(res)
# []
res = html.xpath("//li[1]/attribute::*")
print(res)
# ['item-O']
res = html.xpath('//li[1]/child::a[@href="link1.html"]')
print(res)
# []
res = html.xpath("//li[1]/descendant::span")
print(res)
# []
res = html.xpath('//li[1]/following::*[1]')
print(res)
# []
res = html.xpath('//li[1]/following-sibling::*')
print(res)
# [, , , ] 

2. BeautifulSoup
一个强大的解析工具,它借助网页的结构和属性等特性来解析网页。有了它,我们不用再去写一些复杂的正则表达式,只需要简单的几条语句,就可以完成网页中某个元素的提取。
Beaut 1也l Soup 自动将输入文档转换为Unicode 编码,输出文档转换为UTF-8 编码。你不需妥考虑、编码方式,除非文档没有指定一个编码方式,这时你仅仅需妥说明一下原始编码方式就可以了。
from bs4 import BeautifulSoup
soup = BeautifulSoup('Nice...', 'lxml')
print(soup.div.string)
# Nice...from bs4 import BeautifulSoup
html = """
The Dormouse's story
The Dormouse's story
Once upon a time there were three little sisters; and their names were
,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""
soup = BeautifulSoup(html, 'lxml')
print(soup.prettify()) # 修饰、美化 -- 以标准的缩进格式输出
print()
print(soup.title)
print(soup.title.string)
#
#
#
# The Dormouse's story
#
#
#
#
#
# The Dormouse's story
#
#
#
# Once upon a time there were three little sisters; and their names were
#
#
#
# ,
#
# Lacie
#
# and
#
# Tillie
#
# ;
# and they lived at the bottom of a well.
#
#
# ...
#
#
#
#
# The Dormouse's story
# The Dormouse's story节点选择器
直接调用节点的名称就可以选择节点元素,再调用st ring 属性就可以得到节点内的文本了。
from bs4 import BeautifulSoup
html = """
The Dormouse's story
The Dormouse's story
Once upon a time there were three little sisters; and their names were
,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""
soup = BeautifulSoup(html, 'lxml')
print(soup.title)
print(soup.title.string)
print(type(soup.title))
print(soup.head)
print(soup.p)
# The Dormouse's story
# The Dormouse's story
#
# The Dormouse's story
# The Dormouse's story
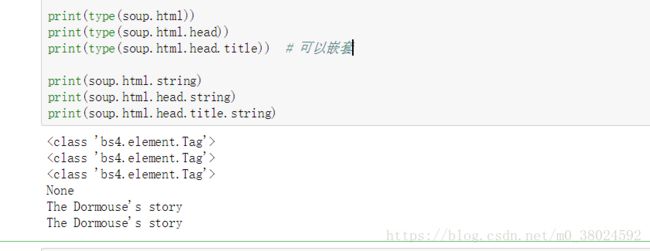
bs4.ele ment.Tag是Beautiful Soup 中一个重要的数据结构。经过选择器选择后,选择结果都是这种Tag 类型。Tag 具有一些属性,比如string属性,调用该属性,可以得到节点的文本内容,所以接下来的输出结果正是节点的文本内容。
最后选择了p 节点。不过这次情况比较特殊,只有第一个p 节点的内容,后面的几个p 节点并没有选到。
from bs4 import BeautifulSoup
html = """
The Dormouse's story
The Dormouse's story
...
"""
soup = BeautifulSoup(html, 'lxml')
print(soup.p.name) # 返回 p
print(soup.p["name"]) # 返回 dromouse
print(soup.p.attrs) # {'class': ['title'], 'name': 'dromouse'}
print(soup.p.attrs['name']) # 返回 dromouse
如果返回结果是单个节点,那么可以直接调用string 、attrs 等属性获得其文本和属性;如果返回结果是多个节点的生成器,则可以转为列表后取出某个元素,然后再调用string 、a ttrs 等属性获取其对应节点的文本和属性。




3. pyquery
如果你对Web 有所涉及,如果你比较喜欢用css 选择器,如果你对jQuery 有所了解,那么这里有一个更适合你的解析库一-pyquery 。


