redis-spider的使用:当当网图书爬虫案例
需求:抓取当当图书的信息
目标:抓取当当图书信息, 包含: 图书所属大分类、图书所属小的分类、小分类的url地址, 图书的名字、封面图片地址、图书url地址、作者、出版社、出版时间、价格、
url:http://book.dangdang.com
思路分析:
- 程序的入口
当当图书中,从大分类入手,还有一个中间分类,以及小分类,小分类对一个的地址就是列表页的地址
注意,url地址的响应和elements略微不同,其中不是每个大分类都在a标签中,中间部分分类不在span标签中


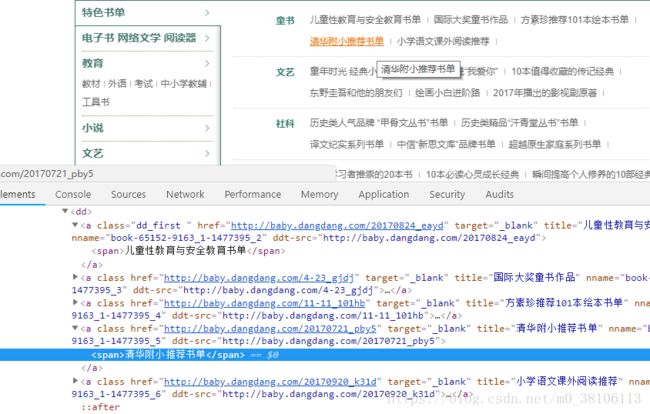
##注意:
由于前两个大分类中小分类对应的列表是变化的,我们只需要根据不同小分类名称进行它的列表类型, 然后进行不同提取就可以;换句话说代码量比较多
#2. 确定列表页的url地址和程序终止条件
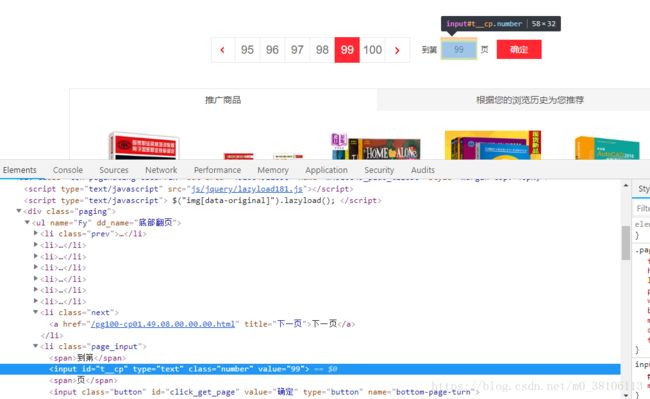
有下一页的时候,li[@class=“next”]下的a标签有链接

有一个class="next none"的标签
所以只要找不到next none的情况下,就找next的url
#3. 确定数据的位置

#4.开始写爬虫
##1.创建爬虫项目
scrapy startproject dangdang
cd dangdang
scrapy genspider book book.dangdang.com
##2.明确爬取的资料,完善Item
import scrapy
'''当当图书爬虫, 抓取的数据'''
class DDBookItem(scrapy.Item):
# define the fields for your item here like:
# 图书所属大分类
b_category_name = scrapy.Field()
# 图书所属小的分类
s_category_name = scrapy.Field()
# 小分类的url地址
s_category_url = scrapy.Field()
# 图书的名字
name = scrapy.Field()
# 封面图片地址
img_url = scrapy.Field()
# 图书url地址
book_url = scrapy.Field()
# 作者
author = scrapy.Field()
# 出版社
publisher = scrapy.Field()
# 出版时间
published_date = scrapy.Field()
# 价格、
price = scrapy.Field()
##3.完善spider
(1)编写parse()方法,获取大中小分类标题并请求小分类的页面,最后一个分类不是图书,舍弃
def parse(self, response):
"""获取大中小分类标题并请求小分类的链接"""
divs = response.xpath('//*[@id="bd_auto"]/div[2]/div[1]/div[1]/div[3]/div')[0:-1]
for div in divs:
item = DDBookItem()
item['b_category_name'] = div.xpath('./dl/dt//text()').extract_first().strip()
a_s = div.xpath('./div//dl[contains(@class,"inner_dl")]/dd/a')
for a in a_s:
item['s_category_name'] = a.xpath('./text()').extract_first()
item['s_category_url'] = a.xpath('./@href').extract_first()
# yield scrapy.Request(item['s_category_url'], callback=self.parse_list, meta={'item': deepcopy(item)})
yield dict(item)
然后获取到的信息如下
{'b_category_name': '',
's_category_name': '人生哲学',
's_category_url': 'http://category.dangdang.com/cp01.21.01.00.00.00.html'}
获取到的信息有些没有大标题,其次获取的信息是两份
调试之后发现,有些大分类的在response中的详细位置不一样
改为div.xpath(’./dl/dt//text()’)后,代码如下
[, , ]
[]
所以加上修改
item['b_category_name'] = ''.join([str.strip() for str in div.xpath('./dl/dt//text()').extract()])
先去掉空格再组合
然后重复的问题,修改xpath,限制范围
a_s = div.xpath('./div//dl[contains(@class,"inner_dl")]/dd/a')
for a in a_s:
item['s_category_name'] = a.xpath('./text()').extract_first()
item['s_category_url'] = a.xpath('./@href').extract_first()
(2)编写parse_list(),获取每本书的详细信息,并请求下一页,返回item给引擎
def parse_list(self, response):
item = response.meta['item']
lis = response.xpath('//ul[@class="bigimg"]/li')
for li in lis:
item['name'] = li.xpath('./p[@class="name"]/a/text()').extract_first()
item['img_url'] = li.xpath('./a[1]/img/@src').extract_first()
item['book_url'] = li.xpath('./p[@class="name"]/a/@href').extract_first()
item['author'] = li.xpath('./p[@class="search_book_author"]/span[1]/a/text()').extract_first()
item['publisher'] = li.xpath('./p[@class="search_book_author"]/span[3]/a/text()').extract_first()
item['published_date'] = li.xpath('./p[@class="search_book_author"]/span[2]/text()').extract_first()
item['price'] = li.xpath('./p[@class="price"]/span[1]/text()').extract_first()
item['price'] = item['price'] if item['price'] else ''
if '\xa5' in item['price']:
item['price'] = item['price'].split('\xa5')[1]
yield item
# 获取下一页的url
next_url = response.xpath("//a[text()='下一页']/@href").extract_first()
if next_url:
# 使用response的urljoin完成拼接功能
next_url = response.urljoin(next_url)
print(next_url)
# 构造下一页请求
yield scrapy.Request(next_url, callback=self.parse_list, meta={'item': dict(item)})
##5.开启redis爬虫
接着开启redis爬虫,先说明一下redis爬虫的意义:防止多电脑爬虫的时候起始url被反复请求
(1)由继承Spider 改为 继承RedisSpider
from scrapy_redis.spiders import RedisSpider
# 1. 由继承Spider 改为 继承RedisSpider
class DangdangSpider(RedisSpider):
(2)把start_urls 改为 redis_key
# start_urls = ['http://book.dangdang.com/']
redis_key = 'dangdang:start_urls'
##6.在settings.py中配置 Scrapy_Redis
# Scrapy_Redis配置信息
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
SCHEDULER_PERSIST = True
# 配置使用Redis来存储爬取到的数据, 如果不需要使用Redis存储可以不配置
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 400,
}
# Redis数据库配置
REDIS_URL = "redis://127.0.0.1:6379"
##7.用脚本给redis数据库加入start_url
import redis
# 将start_url 存储到redis中的redis_key中,让爬虫去爬取
redis_Host = "127.0.0.1"
redis_key = 'dangdang:start_urls'
# 创建redis数据库连接
rediscli = redis.Redis(host=redis_Host, port=6379, db="0")
# 先将redis中的requests全部清空
flushdbRes = rediscli.flushdb()
print("flushdbRes = {}".format(flushdbRes))
rediscli.lpush(redis_key, "http://book.dangdang.com/")
##8.运行程序
# 启动数据库
redis-server.exe conf/redis.conf
# 写入信息
python load_urls_to_redis.py
# 爬取信息
scrapy crawl book
#总结: 把一个Spider爬虫,修改为RedisSpider只需要四步:
把继承Spider修改为继承RedisSpider
把start_urls修改为redis_key
添加scrapy_redis的配置
把start_url添加到数据库中