LR如何在语言理解NLU中实现文本分类
对于Sirius也好,微软小冰也罢,还有度秘、小智、小i等等一些列的问答机器人,已经从方面影响着人类。它们功能强大,既可聊天讲笑话,又可作为业务的客服帮你处理事务,还可知无不言言无不尽的回答各式专业问题,可谓工作小能手。比如像这样:(本来在逗小冰,结果在这午夜,就猝不及防的这麻辣小龙虾刺痛了味蕾.......)
还有就像问题解决型机器人,存在的目的是为了帮用户解决具体问题,例如:售前咨询、售后报修、订机票、酒店、餐厅座位等等。
那机器人是如何理解人类的话语,并正确响应的呢?
人在听到问题时,脑子里会有一些列的反应,我们不妨将脑袋的思考过程简化。脑袋至少需要做到两件事:
理解用户问题,知道用户在问什么。
将用户的问题转化为对知识库的查询。
当然,大前提条件——人的脑袋中是有过往经验的,那对于机器人来说,可以用知识库来替代。

本文仅就针对第一个事情:理解用户问题,知道用户在问什么,来分析下技术路线。
在之前的文章音箱竟然能听懂普通话,原来是因为它,其实已经提到了,大家有兴趣的可以看看,音箱是怎样“听懂”普通话的,本文可以作为这篇文章的延伸。
聊天机器人的语言理解有很多种实现技术。主要solution有:对于用户输入问题进行意图识别和实体提取。
比如天气查询:首先要知道问句是想查天气,那这个明白问句是要干嘛的过程,就是意图识别;其次,知道是查天气的了,那既然查天气,自然需要知道你要查哪里的天气,哪天的天气。而,地点和时间都是自然语言理解NLU中的实体。
所以基于以上例子,不难理解,对于输入的问题主要做好这两件事(意图识别、实体提取),便能对句子有个理解了。
意图理解是个典型的分类问题。
意图识别和语言提取可以通过基于规则(rule-based))和基于模型(model-based)两种方式来实现。
采用一些成熟的分类算法(朴素贝叶斯、SVM、决策树、LR等),即可得到一个分类器。前面也有一些列的文章分享,比如机器学习之Logistic Regression,提到过回归算法来进行数值预测。逻辑回归算法本质还是回归,只是其引入了逻辑函数来帮助其分类。实践发现,逻辑回归在文本分类领域表现的也很优秀。那下面就来看一看。
逻辑函数
假设数据集有n个独立的特征,x1到xn为样本的n个特征。常规的回归算法的目标是拟合出一个多项式函数,使得预测值与真实值的误差最小:
![]()
而我们希望这样的f(x)能够具有很好的逻辑判断性质,最好是能够直接表达具有特征x的样本被分到某类的概率。比如f(x)>0.5的时候能够表示x被分为正类,f(x)<0.5表示分为反类。而且我们希望f(x)总在[0, 1]之间。有这样的函数吗?
sigmoid函数就出现了。这个函数的定义如下:
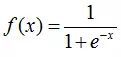
先直观的了解一下,sigmoid函数的图像如下所示:
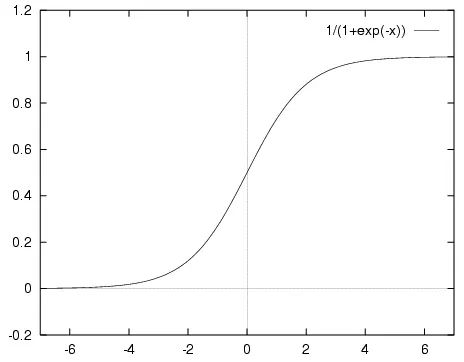
sigmoid函数具有我们需要的一切优美特性,其定义域在全体实数,值域在[0, 1]之间,并且在0点值为0.5。
那么,如何将f(x)转变为sigmoid函数呢?令p(x)=1为具有特征x的样本被分到类别1的概率,则p(x)/[1-p(x)]被定义为让步比(odds ratio)。引入对数:

上式很容易就能把p(x)解出来得到下式:
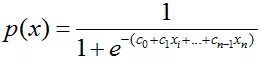
现在,我们得到了需要的sigmoid函数。接下来只需要和往常的线性回归一样,拟合出该式中n个参数c即可。
测试数据
测试数据选择康奈尔大学网站的2M影评数据集。看看罗辑回归分类算法在处理此类情感分类问题效果如何。
直接读入写好的movie_data.npy和movie_target.npy以节省时间。
代码与分析
逻辑回归的代码如下:
# -*- coding: utf-8 -*- from matplotlib import pyplot import scipy as sp import numpy as np from matplotlib import pylab from sklearn.datasets import load_files from sklearn.cross_validation import train_test_split from sklearn.feature_extraction.text import CountVectorizer from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.naive_bayes import MultinomialNB from sklearn.metrics import precision_recall_curve, roc_curve, auc from sklearn.metrics import classification_report from sklearn.linear_model import LogisticRegression import time start_time = time.time() #绘制R/P曲线 def plot_pr(auc_score, precision, recall, label=None): pylab.figure(num=None, figsize=(6, 5)) pylab.xlim([0.0, 1.0]) pylab.ylim([0.0, 1.0]) pylab.xlabel('Recall') pylab.ylabel('Precision') pylab.title('P/R (AUC=%0.2f) / %s' % (auc_score, label)) pylab.fill_between(recall, precision, alpha=0.5) pylab.grid(True, linestyle='-', color='0.75') pylab.plot(recall, precision, lw=1) pylab.show() #读取 movie_data = sp.load('movie_data.npy') movie_target = sp.load('movie_target.npy') x = movie_data y = movie_target #BOOL型特征下的向量空间模型,注意,测试样本调用的是transform接口 count_vec = TfidfVectorizer(binary = False, decode_error = 'ignore',\ stop_words = 'english') average = 0 testNum = 10 for i in range(0, testNum): #加载数据集,切分数据集80%训练,20%测试 x_train, x_test, y_train, y_test\ = train_test_split(movie_data, movie_target, test_size = 0.2) x_train = count_vec.fit_transform(x_train) x_test = count_vec.transform(x_test) #训练LR分类器 clf = LogisticRegression() clf.fit(x_train, y_train) y_pred = clf.predict(x_test) p = np.mean(y_pred == y_test) print(p) average += p #准确率与召回率 answer = clf.predict_proba(x_test)[:,1] precision, recall, thresholds = precision_recall_curve(y_test, answer) report = answer > 0.5 print(classification_report(y_test, report, target_names = ['neg', 'pos'])) print("average precision:", average/testNum) print("time spent:", time.time() - start_time) plot_pr(0.5, precision, recall, "pos")
代码运行结果如下:
0.8
0.817857142857
0.775
0.825
0.807142857143
0.789285714286
0.839285714286
0.846428571429
0.764285714286
0.771428571429
precision recall f1-score support
neg 0.74 0.80 0.77 132
pos 0.81 0.74 0.77 148
avg / total 0.77 0.77 0.77 280
average precision: 0.803571428571
time spent: 9.651551961898804
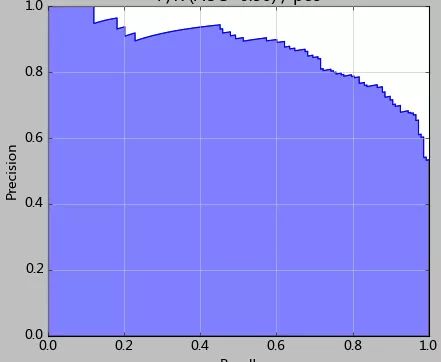
首先连续测试了10组测试样本,最后统计出准确率的平均值。另外一种好的测试方法是K折交叉检验(K-Fold)。这样都能更加准确的评估分类器的性能,考察分类器对噪音的敏感性。
其次我们注意看最后的图,这张图就是使用precision_recall_curve绘制出来的P/R曲线(precition/Recall)。结合P/R图,我们能对逻辑回归有更进一步的理解。
通常使用0.5来做划分两类的依据。而结合P/R分析,阈值的选取是可以更加灵活和优秀的。在上图可以看到,如果选择的阈值过低,那么更多的测试样本都将分为1类。因此召回率能够得到提升,显然准确率牺牲相应准确率。
比如本例中,或许可以选择0.42作为划分值——因为该点的准确率和召回率都很高。
对于文本分类问题,采用交叉验证(cross validation)可得到这个分类器的大致效果。要想达到比较理想的分类效果(准确率/召回率),则需要进行模型调优。而在利用LR实践过程中,觉得训练样本调优和特征调优是比较重要的调优点。
参考资料
http://lib.csdn.net/article/machinelearning/3399
http://blog.csdn.net/busycai/article/details/6159109
时光隧道
相关文章推荐
1、音箱竟然能听懂普通话,原来是因为它
2、机器学习之Logistic Regression
3、常用机器学习算法之线性回归
4、机器学习之朴素贝叶斯分类器
5、机器学习之决策树分类和预测算法原理
5、更多历史文章:请关注下方二维码查看




The first step is always the hardest.

长按~识别二维码,关注我们

