利用hadoop-2.5.0-cdh5.3.6版本,搭建完全分布式HA详细记录(怕忘)
我就按照自己的思路写,可能步骤不一定正确
1、在搭建完全 分布式集群时,首先要保证我们的三台机子的时间同步,所以我们需要同步一台时间服务器,我的三台虚拟机分别为如下hostname
-->make.hadoop.com 第一台
-->make.hadoop2.com 第二台
-->make.hadoop3.com 第三台
1、首先我们把第一台机器当做我们的同步时间的服务器,按步骤操作,即Hadoop2跟Hadoop3同步hadoop机器上的时间
打开我们第一台机器的ntpd时间服务,其他的两台机器不用开
1.1-->sudo service ntpd status
1.2-->sudo service ntpd start
1.3-->开机自动启动设置(在第一台设置,其他不要设置)
-->sudo chkconfig ntpd on
1.4修改配置文件 vi /etc/ntp.conf,其中只有三处需要做修改,如下图
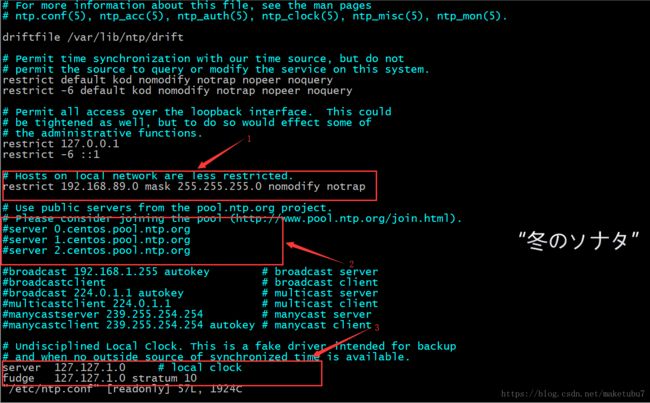
箭头1处,将前面的注释去掉,并把网段修改为自己的网段,2处,因为这里为内网环境不用开启服务,这里的三个server直接 注释掉,3处,开启本地服务,直接将前面的#号去掉,到此处 第一台机器的配置就写好了,我们重启服务,sudo service ntpd restart,
1.5我们试着去其他两台机器,同步一下时间,并设置自动同步的任务 ,
-->在其他两台机器上执行同步命令 sudo /usr/sbin/ntpdate make.hadoop.com 误差基本能保持在1s之内
-->设置定时任务crontab -e 进入任务编辑界面,这里直接将我的贴出来 0-59/10 * * * * /usr/sbin/ntpdate make.hadoop.com 这里不知道脚本的位置 ,可以用which查看一下位置,到这三台机器的时间同步就设置好了。
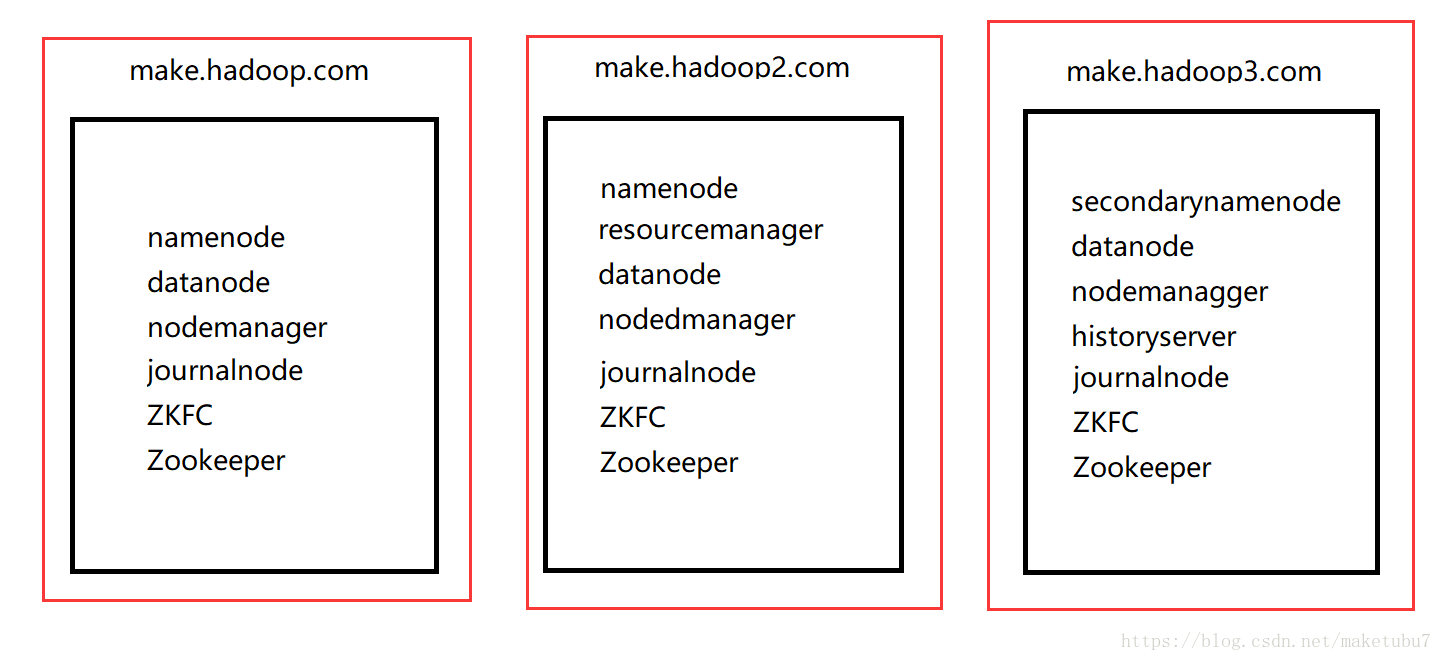
2、下面的图为我的服务器节点的集群规划,我的集群是按照这个节点进行搭建的
2.1、HA的完全搭建,我们首先要安装Zookeeper,下载Zookeeper的tar.gz压缩包,并对其解压,解压后我们来看看它的目录结构,并对配置文件做一定的修改。(单节点)
我们先对conf下的zooxxx.cfg重命名为coo.cfg,对coo.cfg文件进行修改配置(此处为单节点的配置,为了初始化datadir)
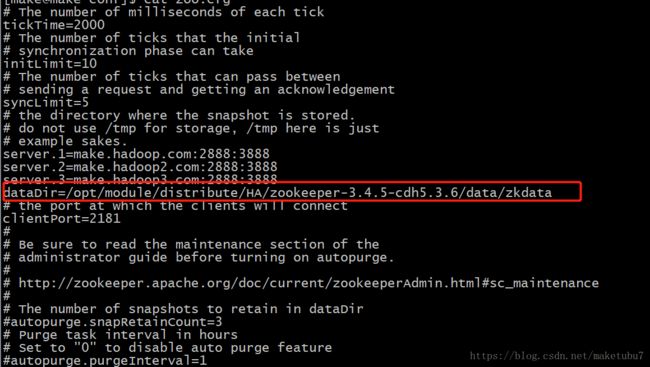
dataDir=/opt/module/distribute/HA/zookeeper-3.4.5-cdh5.3.6/data/zkdata这个是zk的本地数据存放目录,自己随意指定,能记住就是OK的。然后我们启动zk节点,因为我已经配置了分布式,这里就不演示了。
-->bin/zkServer.sh start 节点的名称为 QuorumPeerMain 现在可以启动zk的客户端看一下他的目录,可以看到只有一个文件,因为这个时候我们hadoop节点还没有配置上去,不过我们在启动的时候已经生成了我们刚刚自己配置好的路径。
2.2、接下来我们配置分布式的zookeeper,还是对coo.cfg文件进行修改,只不过这里会添加一点东西

2181表示客户端端口号、2888表示ZK节点内部通信端口号、3888表示ZK内部选举端口号,这里的server.1、server.2、server.3对应的是每台机器,现在我们需要在刚刚配置的路径下面,新建一个名叫myid的文件,,里面的内容就是对应机器的server后面的id,我这里就是1、2、3,你们也可以是a、b、c。现在我们将配置好的zookeeper分发到其他机器
-->scp -r zookeeper-3.4.5-cdh5.3.6/ make.hadoop2.com:/opt/moudle/distribute/HA
-->scp -r zookeeper-3.4.5-cdh5.3.6/ make.hadoop3.com:/opt/moudle/distribute/HA
分发完成之后,将对应的myid文件改成自己机器对应 的id.
2.3、启动所有的zk节点,每台机器都要启动,三台全部启动后,查看每台机器的状态
-->bin/zkServer.sh start
-->bin/zkServer.sh status 这里应该有一个leader,两个follower,如图,我的第二台机器就是leader,关于zk的内部选举机制,可以自己去了解,我也要去了解的,到这里zookeeper的部分就配置完了



3、对hadoop的文件配置,因为对hadoop配置文件的修改,我们在伪分布式的搭建下就已经说过,这里就简单说一下
3.1、对hadoop-env,mapred-env,yarn-env.sh文件,指定你自己的JAVA_HOME
-->修改slaves,添加你自己集群里的所有机器的hostname
make.hadoop.com
make.hadoop2.com
make.hadoop3.com
接下来把四个配置文件的内容贴出来
core-cite.xml
fs.defaultFS
hdfs://ns1
hadoop.tmp.dir
/opt/module/distribute/HA/hadoop-2.5.0-cdh5.3.6/data/tmp
hadoop.http.staticuser.user
make
ha.zookeeper.quorum
make.hadoop.com:2181,make.hadoop2.com:2181,make.hadoop3.com:2181
hdfs-site.xml
dfs.replication
3
dfs.permissions.enabled
false
dfs.nameservices
ns1
dfs.blocksize
134217728
dfs.ha.namenodes.ns1
nn1,nn2
dfs.namenode.rpc-address.ns1.nn1
make.hadoop.com:8020
dfs.namenode.http-address.ns1.nn1
make.hadoop.com:50070
dfs.namenode.rpc-address.ns1.nn2
make.hadoop2.com:8020
dfs.namenode.http-address.ns1.nn2
make.hadoop2.com:50070
dfs.namenode.shared.edits.dir
qjournal://make.hadoop.com:8485;make.hadoop2.com:8485;make.hadoop3.com:8485/ns1
dfs.journalnode.edits.dir
/opt/module/distribute/HA/hadoop-2.5.0-cdh5.3.6/data/journal
dfs.client.failover.proxy.provider.ns1
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.ha.fencing.methods
sshfence ----这个参数的值可以有多种,你也可以换成shell(/bin/true)试试,也是可以的,这个脚本do nothing 返回0
dfs.ha.fencing.ssh.private-key-files
/home/make/.ssh/id_rsa
dfs.ha.fencing.ssh.connect-timeout
30000
dfs.ha.automatic-failover.enabled
true
mapered-site.xml
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
make.hadoop.com:10020
mapreduce.jobhistory.webapp.address
make.hadoop.com:19888
yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
make.hadoop3.com
yarn.log-aggregation-enable
true
yarn.log-aggregation.retain-seconds
106800
到这里我们的配置文件就都配置好了,然后一样的把这个分发出去,然后把 share/doc的文件删掉,因为太大,占资源
-->scp -r hadoop-2.5.0-cdh5.3.6/ make.hadoop2.com:/opt/moudle/distribute/HA
-->scp -r hadoop-2.5.0-cdh5.3.6/ make.hadoop3.com:/opt/moudle/distribute/HA
3.2、这里我们已经启动了zookeeper服务,然后启动三台journalnode(这个是用来同步两台namenode的数据的)
-->sbin/hadoop-daemon.sh start journalnode
3.3、操作namenode(只要格式化一台,另一台进行同步,不能两台都格式化,那样是错的!)
-->格式化第一台:bin/hdfs namenode -format
-->启动刚格式化好的namenode:sbin/hadoop-deamon.sh start namenode
-->在第二台机器上同步namenode的数据:bin/hdfs namenode -bootstrapStandby -->启动第二台的namenode:sbin/hadoop-deamon.sh start namenode
3.4、这里其实可以直接打开你的hdfs的web 端看一看,应该有一台是active,一台standby,如图
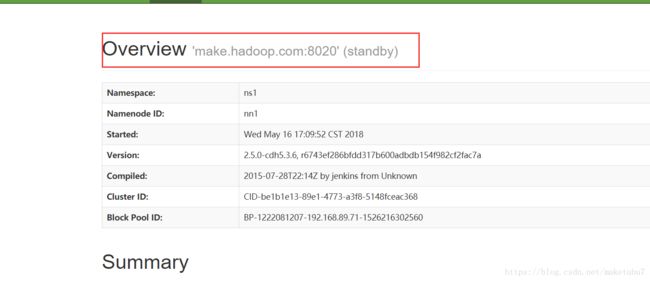
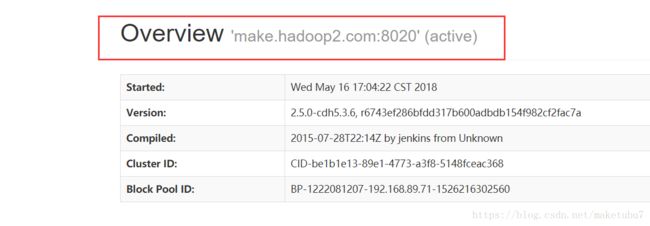
3.5、其实到这里,我们的namenode的一个HA就做完了,可以进行故障自动转移,可以做一个测试,把目前处于active的机器的namenode进程杀掉,那么另一个standby的机器会立刻切换过来active,负责对外提供服务,到此你的HA自动故障转移已经完成了。
4、留一个思考,如果我们的namenode、zk这台机器,发生一种很少见的情况,比如直接关机,直接断网(网卡坏掉),那么我们的自动故障转移,还能不能发挥作用,这个答案我们后面来补充(其实也是老师给我们讲的啦,买个关子,顺便自己也思考一下),我们另一个namenode能不能切换过来呢?